VC9とutf-8 (BOM付きUTF-8)
Microsoft Visual C++ Compiler for Python 2.7 (VC9) についての数日前の投稿(これとこれ)に関係して、ソースコードの日本語エンコーディングの話。
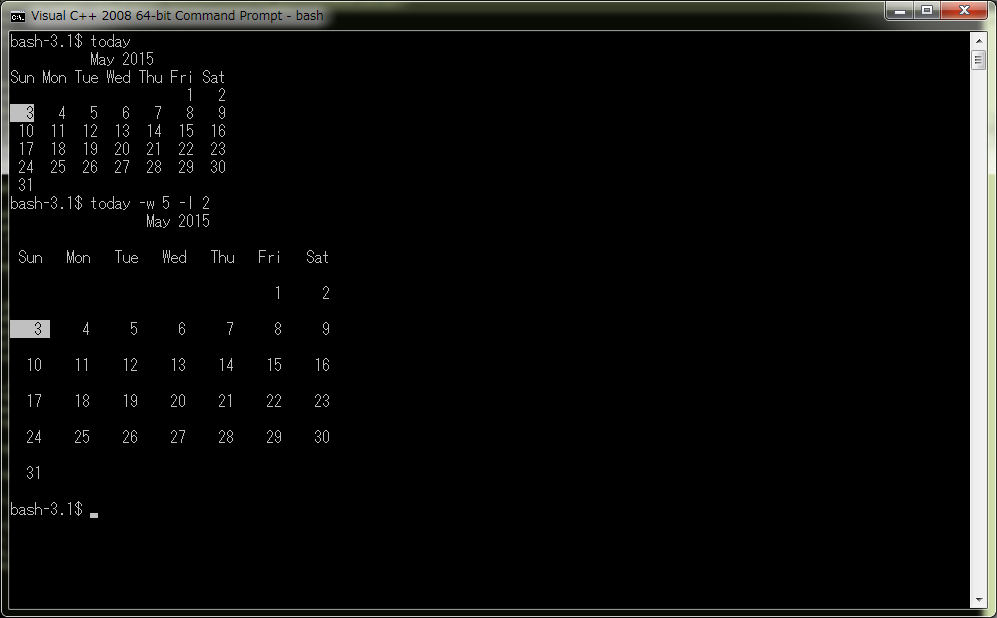
まずは動画をみてくらはい
以下動画、小さいですが、ブラウザのほうのズーム(Chromeとかなら Ctrl + マウスホイール)で多少見やすくなるかと。
「utf-8になぜに BOM (Byte Order Mark)が必要なのよ」問題はともかくとして、IDE のない Microsoft Visual C++ Compiler for Python 2.7 でもこの知識さえあれば、どうにかなります、って話でした。
細かすぎて伝わらない選手権
ビデオの解像度がいまひとつなので、読みにくかったかもしれない、ポイントとなる部分は、ここに貼り付けときます。
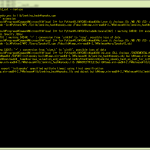
まず、「バイナリファイルとして16進ダンプ」(16進というよりは quoted-printed)してる部分:
1 import quopri
2 print(quopri.encodestring(open("test2.cpp", "rb").read()))
これにより、ファイルの先頭3バイトに BOM が入っているのを見てるわけですな。
それから、標準的 utf-8 (test1.cpp) を BOM 付き utf-8 に変換している部分は、
1 import codecs
2 codecs.getwriter("utf-8-sig")(open("test3.cpp", "wb")).write(
3 open("test1.cpp", "rb").read().decode("utf-8"))
としてます。
動画で一気にみせるがためにこんなプログラムにしてますが、無論
1 import codecs
2 with codecs.getwriter("utf-8-sig")(open("test3.cpp", "wb")) as fo:
3 fo.write(open("test1.cpp", "rb").read().decode("utf-8"))
とかして読みやすく書くのだぞ。さすれば「一括処理」の道は開かれん、っと。
移植性、の話
自分で検証はしていないが、今の gcc は utf-8-sig を知っているらしく、なので、「移植性のために utf-8-sig にするのが現状は良い」と言っている人はいた。苦肉の策だよな。
ちなみに、動画では emacs-24.2-20121208 (Windows 版バイナリ) を使っているために、emacs が utf-8-sig を知ってますが、Meadow 2 も 3 も(ワタシの知っている unicode 環境では) utf-8-sig を知らないくせになまじ制御文字を表示しちゃうがために、ファイルの先頭にゴミが入ってるようにみえます。
つまりな、「utf-8-sig を知らないエディタ」のうち、非文字をなんらか表示してしまうエディタがあるので、誤って編集で消してしまう可能性が高いのね。だので、個人的には「移植性のために utf-8-sig にするのが現状は良い」はどうかなぁ、と思う。
前提を書き忘れた
デフォルトのエンコーディング、つまり日本語版Windowsでの「cp932」(コードページ932)で困らないなら困らなくて良いのれす。あくまでも「utf-8を使いたい」ときの話ね。



![[MSC v.1500 64 bit (AMD64)]的な出力](http://hhsprings.pinoko.jp/site-hhs/wp-content/plugins/related-posts/static/thumbs/10.jpg)