なんだか pygments ばかりやってる。色んなもんほったらかしにして。
本当に欲しいのは lex/yacc の lexer。でもこやつはそう易々とは完成しない。けどあんまし誰から必要とされるもんでもないから、慌ててもいない、と。
本題にがっつり入る前に色々経験しときたいなと思って、bcに続く、割と簡単なお題はないかしら、と思ってさ。
最初色んな記憶をたぐって、なんかないか、なんかないか、と思ってたんだけど、ふと自分の本棚をみてオライリーの「termcap & terminfo」が目に入った。を、こんなんなんで買ったんだっけ? と思ったら、どうやら神田の古本屋(明倫館書店)で買った形跡。この手の技術書を古本屋で購入した記憶なんか、学生時代のものしかないので、ひょっとしたら、東京に用事があった際についでに神田に寄って、めぼしいものがなかったけれども何も買わないのも悔しいので、くらいのことで買ったに違いない。これを「あえて」買う動機が思い当たらないもん。(当時だって別に termcap/terminfo で「困ってた」記憶ないし。あるとすれば多分 curses 関係だろうな。)
termcap/terminfo だってイマドキ需要ほとんどないわけで、幸いまだ lexer 書かれてなかった。やった、これにしよっと。
と思って、「termcap & terminfo」本をざーっと拾い読みして、あぁ、これなら簡単だ、と思ってすぐに書き始めた。
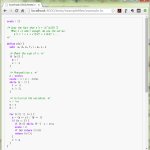
結局のところ簡単は簡単だったんだけど、「書き始める前」に思ってたよりはずっとチマチマ簡単じゃなくて、一日かかっちゃった。出来上がったのはこんなです:
1 # -*- coding: utf-8 -*-
2 """
3 pygments.lexers.configs
4 ~~~~~~~~~~~~~~~~~~~~~~~
5
6 Lexers for configuration file formats.
7
8 :copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
9 :license: BSD, see LICENSE for details.
10 """
11
12 import re
13
14 from pygments.lexer import RegexLexer, default, words, bygroups, include, using
15 from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
16 Number, Punctuation, Whitespace, Literal, Generic
17 from pygments.lexers.shell import BashLexer
18
19 __all__ = ['IniLexer', 'RegeditLexer', 'PropertiesLexer', 'KconfigLexer',
20 'Cfengine3Lexer', 'ApacheConfLexer', 'SquidConfLexer',
21 'NginxConfLexer', 'LighttpdConfLexer', 'DockerLexer',
22 'TerraformLexer', 'TermcapLexer', 'TerminfoLexer']
23
24 # ...
25 class TermcapLexer(RegexLexer):
26 """
27 Lexer for termcap database source.
28
29 This is very simple and minimal.
30
31 .. versionadded:: 2.1
32 """
33 name = 'Termcap'
34 aliases = ['termcap',]
35
36 filenames = ['termcap',]
37 mimetypes = []
38
39 # NOTE:
40 # * multiline with trailing backslash
41 # * separator is ':'
42 # * to embed colon as data, we must use \072
43 # * space after separator is not allowed (mayve)
44 tokens = {
45 'root': [
46 (r'^#.*$', Comment),
47 (r'^[^\s#:\|]+', Name.Tag, 'names'),
48 ],
49 'names': [
50 (r'\n', Text, '#pop'),
51 (r':', Punctuation, 'defs'),
52 (r'\|', Punctuation),
53 (r'[^:\|]+', Name.Attribute),
54 ],
55 'defs': [
56 (r'\\\n[ \t]*', Text),
57 (r'\n[ \t]*', Text, '#pop:2'),
58 (r'(#)([0-9]+)', bygroups(Operator, Number)),
59 (r'=', Operator, 'data'),
60 (r':', Punctuation),
61 (r'[^\s:=#]+', Name.Class),
62 ],
63 'data': [
64 (r'\\072', Literal),
65 (r':', Punctuation, '#pop'),
66 (r'.', Literal),
67 ],
68 }
69
70
71 class TerminfoLexer(RegexLexer):
72 """
73 Lexer for terminfo database source.
74
75 This is very simple and minimal.
76
77 .. versionadded:: 2.1
78 """
79 name = 'Terminfo'
80 aliases = ['terminfo',]
81
82 filenames = ['terminfo',]
83 mimetypes = []
84
85 # NOTE:
86 # * multiline with leading whitespace
87 # * separator is ','
88 # * to embed comma as data, we can use \,
89 # * space after separator is allowed
90 tokens = {
91 'root': [
92 (r'^#.*$', Comment),
93 (r'^[^\s#,\|]+', Name.Tag, 'names'),
94 ],
95 'names': [
96 (r'\n', Text, '#pop'),
97 (r'(,)([ \t]*)', bygroups(Punctuation, Text), 'defs'),
98 (r'\|', Punctuation),
99 (r'[^,\|]+', Name.Attribute),
100 ],
101 'defs': [
102 (r'\n[ \t]+', Text),
103 (r'\n', Text, '#pop:2'),
104 (r'(#)([0-9]+)', bygroups(Operator, Number)),
105 (r'=', Operator, 'data'),
106 (r'(,)([ \t]*)', bygroups(Punctuation, Text)),
107 (r'[^\s,=#]+', Name.Class),
108 ],
109 'data': [
110 (r'\\[,\\]', Literal),
111 (r'(,)([ \t]*)', bygroups(Punctuation, Text), '#pop'),
112 (r'.', Literal),
113 ],
114 }
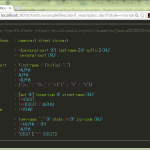
いつも使ってるお気に入りの emacs スタイルだとあんまり効果わからないので、monokai で:
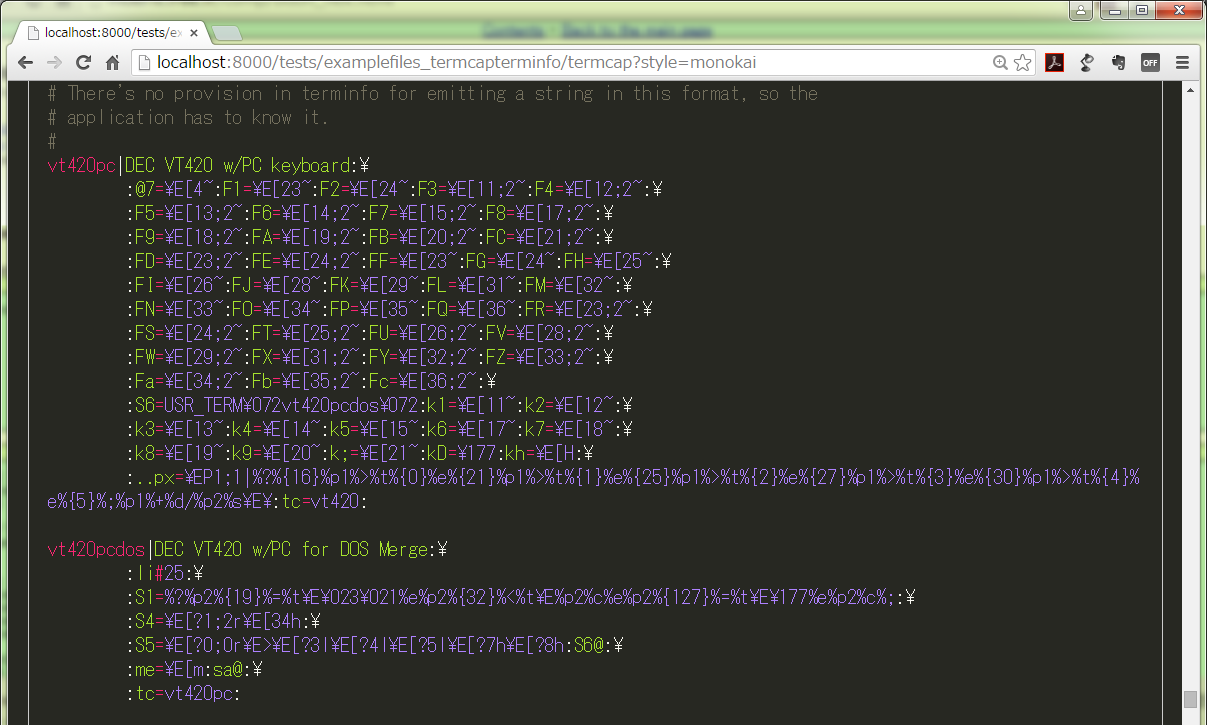
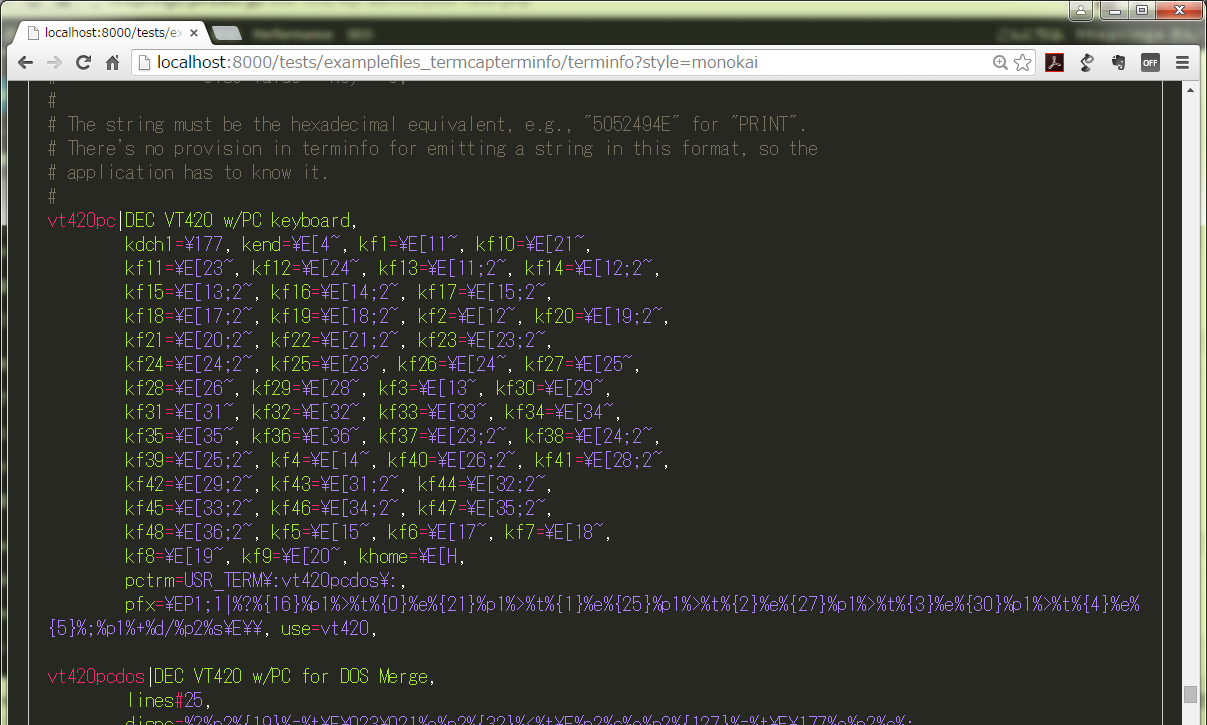
えらく黒魔術なこれを読み書き出来る人を尊敬しますわ。
にしてもあれだ。これを喜んで活用する人が今いるとしたらどんな人たちか、てことだ。だいたい自分でこれを保守する必要に迫られる人なんか、極々限られてて、さらにいえばこれを「読む必要に迫られる」人でさえも滅茶苦茶少ないだろう。だから「何某かのサーバ管理」の UI としてこの lexer で「読みやすくなったぜ」としたところで、それは「読みやすくなったところでワガランモンハワガランし、どーせ更新しないしな」となるだけだろ、ってことである。
まぁ所詮はワタシの excercise である。誰も嬉しくなくても知ったことではない。