Pygments の話のような、Python の話のような。
こんなこと夢想したことない?
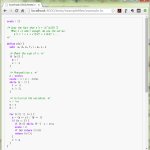
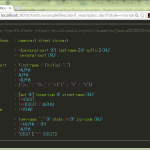
やりたいことがこんなだとして:
1 import re
2 # ...
3 m = re.match(r"abc|def|ghi", text)
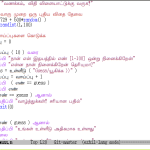
こうしたいんだよなぁ:
1 import re
2 # ...
3 m = re.match(r"[adg][beh][cfi]", text)
こんなのを自動でやりたいよね、なんてことだ。
いくつか自作の Pygments lexer を作って PR 投げて、レビュー受けてる中で、2つほど「このケースでは words 使っちくれ」てな指摘が入った。
言われるがままに words() に置き換えるとさ、「速い」んだよねこれが。1.3倍高速化、みたいな。
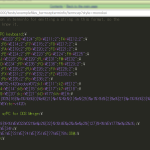
この「words()」は Pygments 2.0 からの機能なんだけれども、これに関係するのが実はこれ:
1 Version 2.0rc1
2 --------------
3 (released Oct 16, 2014)
4
5 ...
6
7 - Added a helper to "optimize" regular expressions that match one of many
8 literal words; this can save 20% and more lexing time with lexers that
9 highlight many keywords or builtins.
words()は内部でこの「a helper to “optimize” regexp」を呼び出してる。
Pygments lexer で words を使うの図:
1 # ...
2
3 class BCLexer(RegexLexer):
4 """
5 A `BC <https://www.gnu.org/software/bc/>`_ lexer.
6
7 .. versionadded:: 2.1
8 """
9 name = 'BC'
10 aliases = ['bc']
11 filenames = ['*.bc']
12
13 tokens = {
14 'root': [
15 (r'/\*', Comment.Multiline, 'comment'),
16 (r'"(?:[^"\\]|\\.)*"', String),
17 (r'[{}();,]', Punctuation),
18 (words(('if', 'else', 'while', 'for', 'break', 'continue',
19 'halt', 'return', 'define', 'auto', 'print', 'read',
20 'length', 'scale', 'sqrt', 'limits', 'quit',
21 'warranty'), suffix=r'\b'), Keyword),
22 (r'\+\+|--|\|\||&&|'
23 r'([-<>+*%\^/!=])=?', Operator),
24 # bc doesn't support exponential
25 (r'[0-9]+(\.[0-9]*)?', Number),
26 (r'\.[0-9]+', Number),
27 (r'.', Text)
28 ],
29 'comment': [
30 (r'[^*/]+', Comment.Multiline),
31 (r'\*/', Comment.Multiline, '#pop'),
32 (r'[*/]', Comment.Multiline)
33 ],
34 }
最初のワタシの BCLexer は words() 使ってなかった。是非較べてみてくれ。
でね。ここまでは「Pygments 依存」の話ではあるんだけれども、この「a helper to “optimize” regular expressions」がね、「小さくて気が利くヤツだ」。
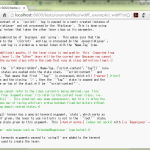
Pygments 2.0 を持ってる人は是非動かしてみて:
1 >>> from pygments.regexopt import regex_opt
2 >>> regex_opt(['elif', 'else', 'except', 'exec', 'try', 'while', 'yield', 'yield from'])
3 '(e(?:l(?:if|se)|x(?:cept|ec))|try|while|yield(?:(?:\\ from)?))'
4 >>>
まさに冒頭の「夢想」そのもの、ですやん。
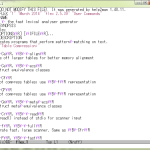
じゃぁこの「regex_opt」とは何者なのか? これだけなのね:
これだけっつったって結構アレだ
1 # -*- coding: utf-8 -*-
2 """
3 pygments.regexopt
4 ~~~~~~~~~~~~~~~~~
5
6 An algorithm that generates optimized regexes for matching long lists of
7 literal strings.
8
9 :copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
10 :license: BSD, see LICENSE for details.
11 """
12
13 import re
14 from re import escape
15 from os.path import commonprefix
16 from itertools import groupby
17 from operator import itemgetter
18
19 CS_ESCAPE = re.compile(r'[\^\\\-\]]')
20 FIRST_ELEMENT = itemgetter(0)
21
22
23 def make_charset(letters):
24 return '[' + CS_ESCAPE.sub(lambda m: '\\' + m.group(), ''.join(letters)) + ']'
25
26
27 def regex_opt_inner(strings, open_paren):
28 """Return a regex that matches any string in the sorted list of strings."""
29 close_paren = open_paren and ')' or ''
30 # print strings, repr(open_paren)
31 if not strings:
32 # print '-> nothing left'
33 return ''
34 first = strings[0]
35 if len(strings) == 1:
36 # print '-> only 1 string'
37 return open_paren + escape(first) + close_paren
38 if not first:
39 # print '-> first string empty'
40 return open_paren + regex_opt_inner(strings[1:], '(?:') \
41 + '?' + close_paren
42 if len(first) == 1:
43 # multiple one-char strings? make a charset
44 oneletter = []
45 rest = []
46 for s in strings:
47 if len(s) == 1:
48 oneletter.append(s)
49 else:
50 rest.append(s)
51 if len(oneletter) > 1: # do we have more than one oneletter string?
52 if rest:
53 # print '-> 1-character + rest'
54 return open_paren + regex_opt_inner(rest, '') + '|' \
55 + make_charset(oneletter) + close_paren
56 # print '-> only 1-character'
57 return make_charset(oneletter)
58 prefix = commonprefix(strings)
59 if prefix:
60 plen = len(prefix)
61 # we have a prefix for all strings
62 # print '-> prefix:', prefix
63 return open_paren + escape(prefix) \
64 + regex_opt_inner([s[plen:] for s in strings], '(?:') \
65 + close_paren
66 # is there a suffix?
67 strings_rev = [s[::-1] for s in strings]
68 suffix = commonprefix(strings_rev)
69 if suffix:
70 slen = len(suffix)
71 # print '-> suffix:', suffix[::-1]
72 return open_paren \
73 + regex_opt_inner(sorted(s[:-slen] for s in strings), '(?:') \
74 + escape(suffix[::-1]) + close_paren
75 # recurse on common 1-string prefixes
76 # print '-> last resort'
77 return open_paren + \
78 '|'.join(regex_opt_inner(list(group[1]), '')
79 for group in groupby(strings, lambda s: s[0] == first[0])) \
80 + close_paren
81
82
83 def regex_opt(strings, prefix='', suffix=''):
84 """Return a compiled regex that matches any string in the given list.
85
86 The strings to match must be literal strings, not regexes. They will be
87 regex-escaped.
88
89 *prefix* and *suffix* are pre- and appended to the final regex.
90 """
91 strings = sorted(strings)
92 return prefix + regex_opt_inner(strings, '(') + suffix
Pygments 以外からでも使いたくならない?
まぁアレだけどな、「結構大きめの入力ファイルに対し、結構多めの種類のキーワードマッチングをしたい」という場合に限って嬉しい、という類のもんであって、なんでもかんでもこれで高速化出来るわけではないけどな。