「重傷者数は二週間遅れなのです」と言われましても、とな。
「専門家にご意見をうかがいますのです」のだけでねくて、実際に可視化してくれ、なんてことを思うんだよねぇ。ニュースやワイドショーがそれをやってみせているのはほとんど見たことがないが、専門家の先生方は都度「重傷者数は二週間遅れて出てくる」ことを説明してくれている。専門家が重視しているものを「見える化」しようという発想は、少しくらいないもんなんだろうか、もう一年経つんだからさ、てことね。
csvを自分の都合のいいデータに加工するスクリプト(4’’)(東洋経済オンラインのもの)
1 # -*- coding: utf-8-unix -*-
2 import io
3 import csv
4 import datetime
5 import numpy as np
6
7
8 _PREFCODE = {
9 '北海道': 1,
10 '青森県': 2,
11 '岩手県': 3,
12 '宮城県': 4,
13 '秋田県': 5,
14 '山形県': 6,
15 '福島県': 7,
16 '茨城県': 8,
17 '栃木県': 9,
18 '群馬県': 10,
19 '埼玉県': 11,
20 '千葉県': 12,
21 '東京都': 13,
22 '神奈川県': 14,
23 '新潟県': 15,
24 '富山県': 16,
25 '石川県': 17,
26 '福井県': 18,
27 '山梨県': 19,
28 '長野県': 20,
29 '岐阜県': 21,
30 '静岡県': 22,
31 '愛知県': 23,
32 '三重県': 24,
33 '滋賀県': 25,
34 '京都府': 26,
35 '大阪府': 27,
36 '兵庫県': 28,
37 '奈良県': 29,
38 '和歌山県': 30,
39 '鳥取県': 31,
40 '島根県': 32,
41 '岡山県': 33,
42 '広島県': 34,
43 '山口県': 35,
44 '徳島県': 36,
45 '香川県': 37,
46 '愛媛県': 38,
47 '高知県': 39,
48 '福岡県': 40,
49 '佐賀県': 41,
50 '長崎県': 42,
51 '熊本県': 43,
52 '大分県': 44,
53 '宮崎県': 45,
54 '鹿児島県': 46,
55 '沖縄県': 47,
56 }
57 _COLSNM = (
58 "testedPositive",
59 "peopleTested",
60 "hospitalized",
61 "serious",
62 "discharged",
63 "deaths",
64 "effectiveReproductionNumber",
65 )
66 def _tonpa(fn):
67 # 元データ prefectures.csv の著作権:
68 # 『東洋経済オンライン「新型コロナウイルス 国内感染の状況」制作:荻原和樹』
69 #
70 # 1. 開始日が NHK まとめと違う
71 # 2. 更新のない都道府県は省略してある
72 # 3. 日付は一応抜けなく連続している、今のところ
73 #
74 # NHKまとめのほうで密行列として扱った同じノリにしたい、ここでは面倒だけど。
75 # つまり、列方向に都道府県、行方向に日付。
76 result = {
77 k: np.zeros((1, 47))
78 for k in _COLSNM}
79 reader = csv.reader(io.open(fn, encoding="utf-8-sig"))
80 next(reader)
81 def _f(d):
82 if not d or d == "-":
83 # 不明とか未報告の意味だと思う。
84 return float("nan")
85 return float(d)
86
87 era = datetime.datetime(2020, 1, 16) # NHKまとめのほうの起点日
88 curdate = era
89 for line in reader:
90 date = datetime.datetime(*map(int, line[:3]))
91 dadv = (date - curdate).days
92 data = list(map(_f, line[5:]))
93 p = _PREFCODE[line[3]]
94 for i, k in enumerate(_COLSNM):
95 for _ in range(dadv):
96 result[k] = np.vstack((result[k], np.zeros((1, 47))))
97 result[k][-1, p - 1] = data[i]
98 curdate = date
99 # 元データについて、どうやら厚労省のオープンデータそのものを転記しただけの
100 # 項目は累積でのみ管理しているらしく、この csv 全体では「累積だったりそうで
101 # なかったり」と大変使いにくい。ゆえ、累積のものは読み替えておく。
102 for k in ("testedPositive", "peopleTested", "discharged", "deaths",):
103 result[k][1:] = (
104 result[k] - np.roll(result[k], 1, axis=0))[1:]
105 #
106 # peopleTested の最新2日分はゴミ:
107 # ---
108 # 2021,1,28,東京都,Tokyo, 97571, 1303823.0, 14957.0, 150, 81767.0, 847, 0.74
109 # 2021,1,29,東京都,Tokyo, 98439, 1309999.0, 13807.0, 147, 83768.0, 864, 0.76
110 # 2021,1,30,東京都,Tokyo, 99208, 1309999.0, 13383.0, 141, 84942.0, 883, 0.77
111 # 2021,1,31,東京都,Tokyo, 99841, 1309999.0, 13257.0, 140, 85698.0, 886, 0.78
112 # ---
113 # 集計が3日遅れ、てこと、だろう。
114 result["peopleTested"][np.where(result["peopleTested"] == 0.0)] = float("nan")
115 # 移動平均
116 for k in ("testedPositive", "peopleTested", "hospitalized", "serious", "deaths"):
117 k1, k2 = k, k + "_movavg"
118 result[k2] = np.zeros(result[k1].shape)
119 for dt in range(len(result[k1])):
120 result[k2][dt, :] = result[k1][
121 max(0, dt - 6):dt + 1, :].mean(axis=0)
122 #
123 np.savez(io.open("toyokeizai_online_covid19.npz", "wb"), **result)
124
125
126 if __name__ == '__main__':
127 _tonpa("prefectures.csv")
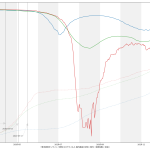
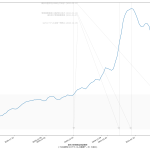
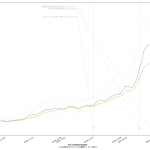
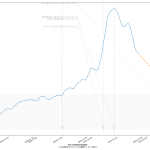
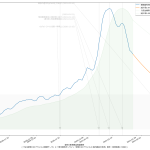
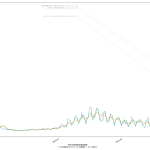
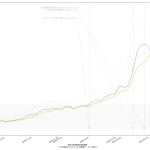
今回の可視化は「波の推移のタイムラグ」を観察するのが目的なので、縦軸は無次元(最大値を1.0とした比):
上のスクリプトでセーブしたデータを読み込ん可視化を行うやーつ
1 # -*- coding: utf-8 -*-
2 import io
3 import datetime
4 import functools
5 import numpy as np
6 import matplotlib as mpl
7 import matplotlib.pyplot as plt
8 import matplotlib.font_manager
9 import random
10
11
12 def _vis(dattko):
13 fontprop = matplotlib.font_manager.FontProperties(
14 fname="c:/Windows/Fonts/meiryo.ttc")
15
16 era = "2020/1/16" # 木曜日
17 era = datetime.datetime(*map(int, era.split("/")))
18 (wh_sl, wh_n) = (slice(12, 12+1), "東京")
19
20 #
21 fig, ax1 = plt.subplots(tight_layout=True)
22 lines = []
23 fig.set_size_inches(16.53 * 1.4, 11.69)
24 T = np.array([era + datetime.timedelta(t)
25 for t in range(len(dattko["testedPositive_movavg"][:,wh_sl].sum(axis=1)))])
26 for k in ("testedPositive_movavg", "serious_movavg", "deaths_movavg"):
27 X = dattko[k][:,wh_sl].sum(axis=1)
28 l, = ax1.plot(T, X / np.nanmax(X), linestyle="dashed")
29 #print(T[np.nanargmax(X)])
30 lines.append((l, k))
31 #
32 ax1.legend([l for l, t in lines], [t for l, t in lines], shadow=True, prop=fontprop)
33 for evdt in (
34 datetime.datetime(2020, 4, 14),
35 datetime.datetime(2020, 5, 3),
36 datetime.datetime(2020, 5, 17),
37 datetime.datetime(2021, 1, 11),
38 datetime.datetime(2021, 1, 25),
39 #datetime.datetime(2021, 1, 30),
40 ):
41 ax1.annotate("{}".format(str(evdt)[:len("????-??-??")]),
42 xy=(evdt, 0.1), xycoords='data',
43 xytext=(
44 ((evdt - era).days / (T[-1] - era).days),
45 0.05 + (random.random() / 5)),
46 textcoords='axes fraction',
47 arrowprops=dict(facecolor='black', width=0.0001, alpha=0.1),
48 horizontalalignment='right', verticalalignment='top',
49 alpha=0.8,
50 fontproperties=fontprop)
51 ax1.vlines([evdt], 0, 1, transform=ax1.get_xaxis_transform(), alpha=0.3)
52 df = datetime.datetime
53 ax1.axvspan(df(2020, 2, 1), df(2020, 3, 1), facecolor="lightgray", alpha=0.3)
54 ax1.axvspan(df(2020, 4, 1), df(2020, 5, 1), facecolor="lightgray", alpha=0.3)
55 ax1.axvspan(df(2020, 6, 1), df(2020, 7, 1), facecolor="lightgray", alpha=0.3)
56 ax1.axvspan(df(2020, 8, 1), df(2020, 9, 1), facecolor="lightgray", alpha=0.3)
57 ax1.axvspan(df(2020, 10, 1), df(2020, 11, 1), facecolor="lightgray", alpha=0.3)
58 ax1.axvspan(df(2020, 12, 1), df(2021, 1, 1), facecolor="lightgray", alpha=0.3)
59 ax1.axvspan(df(2021, 2, 1), T[-1], facecolor="lightgray", alpha=0.3)
60 ax1.set_xlabel(
61 "「東洋経済オンライン「新型コロナウイルス 国内感染の状況」制作:荻原和樹」を加工",
62 fontproperties=fontprop)
63 #ax1.grid(True)
64 #fig.autofmt_xdate()
65 #plt.show()
66 fig.savefig("tko.png")
67 plt.close(fig)
68
69
70 if __name__ == '__main__':
71 fn2 = "toyokeizai_online_covid19.npz"
72 _vis(np.load(io.open(fn2, "rb")))
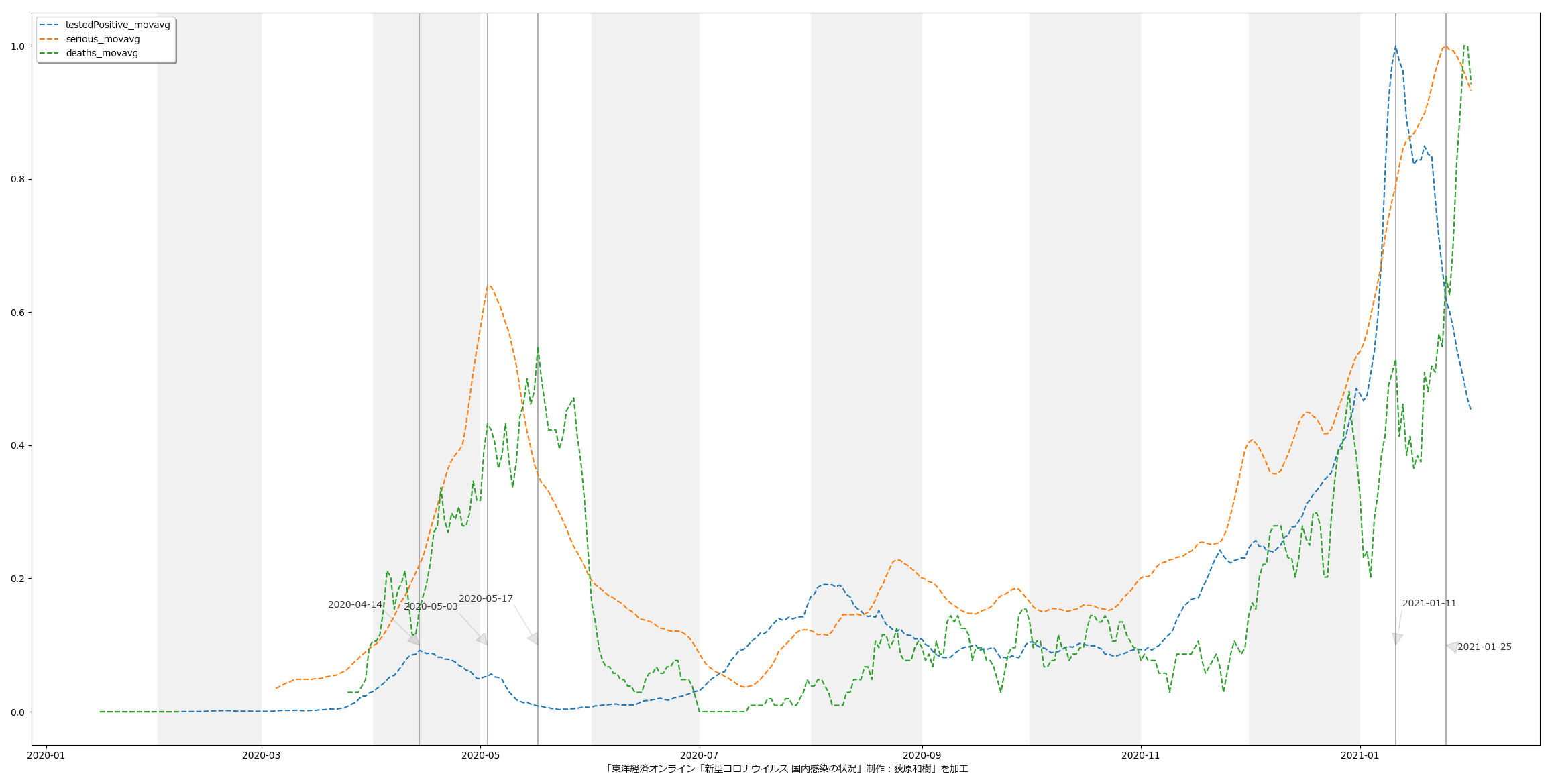
第一波のときには、「新規陽性判明」から二週間のタイムラグで重傷者が増え、そこからさらに二週間のタイムラグで死亡者が増えていったことがわかる。今回の第三波が完全にそれをトレースするかはわからないが、少なくとも重症者については似た推移を辿りそうである。死亡者については、たぶんまだピークアウトし始めてない、ということだろう。
3月7日までの解除の際は、これも目安にすると良い、ということである。なのだが、第四波を想定し、そこでもこの観察結果がそのまま通用するかどうかは、これは第四波がいつかによる。ワクチンが間に合わないうちに第四波が来てしまった場合は、今回とまったく同じことになるし、ワクチン接種が始まっている時期であれば、少しは楽観的に考えてもよくなるかもしれない。あと当然だけど山の高さにも依存する。第一波と第三波は規模感がそんなに変わらなかったので、タイムラグも似通ったということになるんだと思う。が、例えば感染者数が今回の10倍とかになったときにどうなるかは、はっきりいって想像は出来ない。