ここまでくるともはや蛇足。
1 # -*- coding: utf-8 -*-
2 import io
3 import sys
4 import csv
5 import datetime
6 import numpy as np
7
8
9 def _tonpa(fn):
10 # rownum=2020/1/16からの日数, colnum=都道府県コード-1
11 result = {
12 "newpat": np.zeros((1, 47)),
13 "newpatmovavg": np.zeros((1, 47)), # 週平均
14 "newpatmovavg2": np.zeros((1, 47)), # 2週平均
15 "newdeath": np.zeros((1, 47)),
16 "newdeathmovavg": np.zeros((1, 47)),
17 "newdeathmovavg2": np.zeros((1, 47)),
18 }
19 era = "2020/1/16"
20 era = datetime.datetime(*map(int, era.split("/")))
21 reader = csv.reader(io.open(fn, encoding="utf-8-sig"))
22 next(reader)
23 for row in reader:
24 dt, (p, c, d) = row[0], map(int, row[1::2])
25 dt = (datetime.datetime(*map(int, dt.split("/"))) - era).days
26 if dt > len(result["newpat"]) - 1:
27 for k in result.keys():
28 result[k] = np.vstack((result[k], np.zeros((1, 47))))
29 result["newpat"][dt, p - 1] = c
30 result["newpatmovavg"][dt, p - 1] = result["newpat"][max(0, dt - 7):dt + 1, p - 1].mean()
31 result["newpatmovavg2"][dt, p - 1] = result["newpat"][max(0, dt - 14):dt + 1, p - 1].mean()
32 result["newdeath"][dt, p - 1] = d
33 result["newdeathmovavg"][dt, p - 1] = result["newdeath"][max(0, dt - 7):dt + 1, p - 1].mean()
34 result["newdeathmovavg2"][dt, p - 1] = result["newdeath"][max(0, dt - 14):dt + 1, p - 1].mean()
35 np.savez(io.open("nhk_news_covid19_prefectures_daily_data.npz", "wb"), **result)
36
37
38 if __name__ == '__main__':
39 fn = "nhk_news_covid19_prefectures_daily_data.csv"
40 _tonpa(fn)
スクリプトをマジメに読んだ人は気付いたかもしれない。「8日平均」と「15日平均」を計算しちゃってる。一連の「主張」の本題とはあまり関係ないとはいえ、さすがにもうちょっと慎重にやるべきでした、すまぬ。正しくは「dt – 6」「dt – 5」…「dt – 1」「dt」の7エレメントでの平均を取らなければならないので、「slice(dt – 6, dt + 1)」。8日平均が役に立たないわけではないけれど、やりたいこととやってることが違うので、間違いは間違い。グラフは滑らかさが若干減って、もうほんの少しだけガタガタになる。
1 # -*- coding: utf-8 -*-
2 import io
3 import datetime
4 import numpy as np
5 import matplotlib as mpl
6 import matplotlib.pyplot as plt
7 import matplotlib.font_manager
8
9
10 def _vis(dat):
11 era = "2020/1/16" # 木曜日
12 era = datetime.datetime(*map(int, era.split("/")))
13 npat = dat["newpat"][:,12] # 12: 東京 (都道府県コード13)
14 npatma = dat["newpatmovavg"][:,12]
15 npatma2 = dat["newpatmovavg2"][:,12]
16
17 fontprop = matplotlib.font_manager.FontProperties(fname="c:/Windows/Fonts/meiryo.ttc")
18
19 T = [era + datetime.timedelta(t) for t in range(len(npat))]
20 fig, ax1 = plt.subplots(tight_layout=True)
21 fig.set_size_inches(16.53, 11.69)
22 skip = 7*4*7
23 lines = []
24 for dow in range(7):
25 l, = ax1.plot(T[skip:][dow::7], npat[skip:][dow::7], linestyle="dotted", alpha=0.2)
26 lines.append(l)
27 l, = ax1.plot(T[skip:], npatma[skip:])
28 lines.append(l)
29 l, = ax1.plot(T[skip:], npatma2[skip:])
30 lines.append(l)
31 ax1.legend(lines, [
32 dow + "曜日" for dow in [
33 "木", "金", "土", "日", "月", "火", "水"]] + ["週平均", "2週平均"],
34 shadow=True, prop=fontprop)
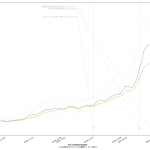
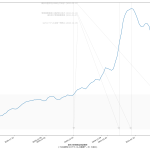
35 ax1.set_xlabel("東京の新規感染者数推移\n(「NHK新型コロナウイルス関連データ」を加工)", fontproperties=fontprop)
36 fig.autofmt_xdate()
37 #
38 for evtxt, evdt in (
39 ("GoToトラベル全国一時停止", datetime.datetime(2020, 12, 15)),
40 ("1都3県に緊急事態宣言", datetime.datetime(2021, 1, 7)),
41 ("緊急事態宣言11都府県に拡大", datetime.datetime(2021, 1, 13)),
42 ):
43 ax1.annotate("{} ({})".format(evtxt, str(evdt)[:len("????-??-??")]),
44 xy=(evdt, 0), xycoords='data',
45 xytext=(
46 0.5,
47 (evdt - era).days / (T[-1] - era).days),
48 textcoords='axes fraction',
49 arrowprops=dict(facecolor='black', width=0.0001, alpha=0.1),
50 horizontalalignment='right', verticalalignment='top',
51 alpha=0.3,
52 fontproperties=fontprop)
53 ax1.vlines([evdt], 0, 1, transform=ax1.get_xaxis_transform(), alpha=0.1)
54 #
55 #plt.show()
56 fig.savefig("nhk_news_covid19_prefectures_daily_data2.png")
57 plt.close(fig)
58
59
60 if __name__ == '__main__':
61 fn = "nhk_news_covid19_prefectures_daily_data.npz"
62 _vis(np.load(io.open(fn, "rb")))
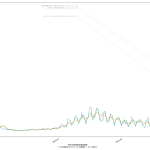
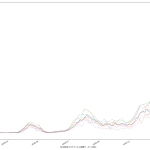
またしても曜日間違えとかしてたらゴメン。「公式なもの」のつもりが皆目ないもんで、雑なのよ。
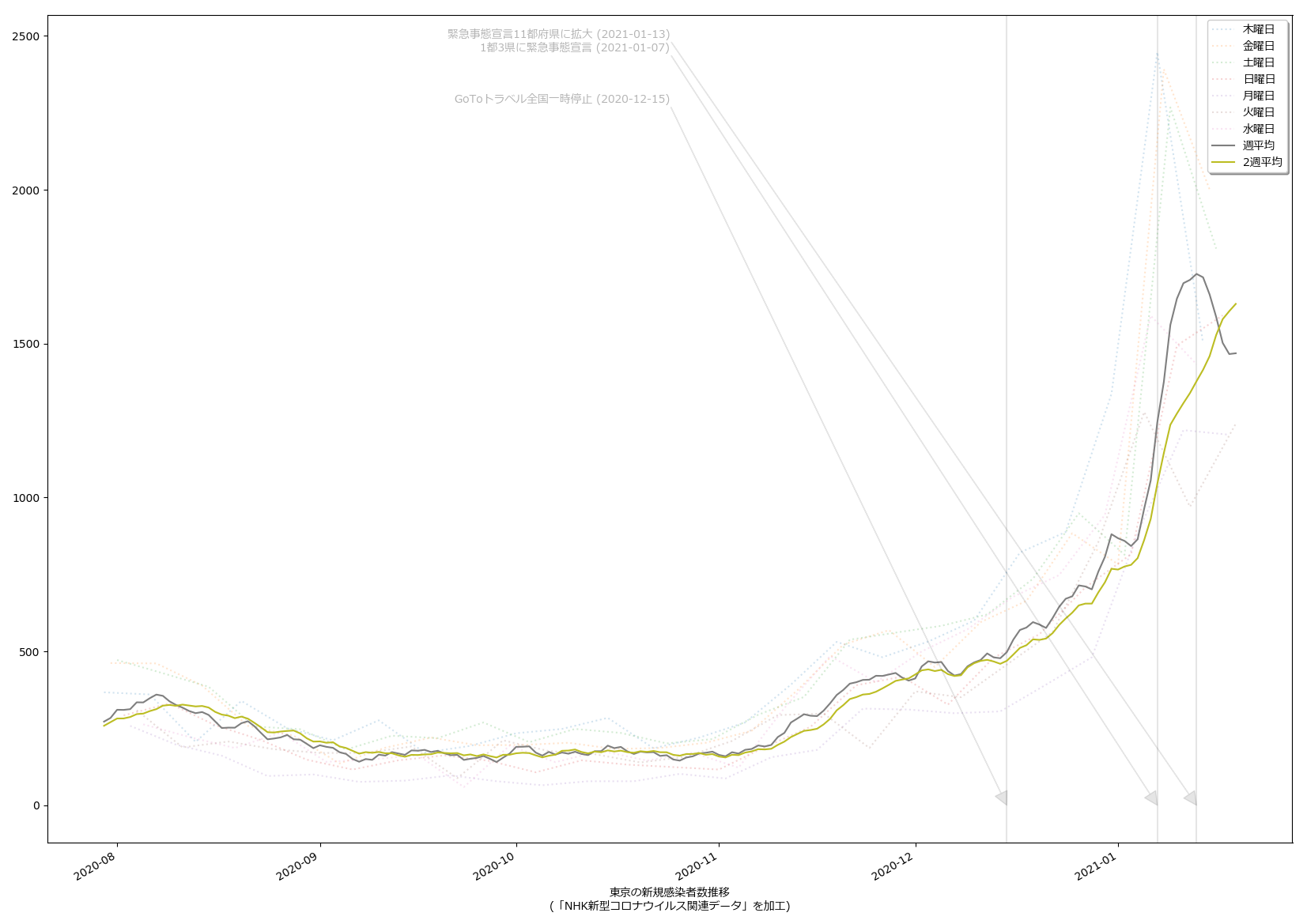
前回のに二週間平均のプロットを追加した、てのが本質的な違いなんだけれども、だとして、今回のは何をしたかったかというと。
夕方のニュース番組での岡田先生発言が個人的に気になったもんでな。
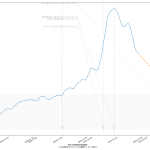
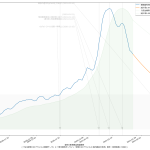
おそらく一般人の感覚としては、「感染拡大速度が鈍化してる」なんだと思うわけね。岡田さんは「いやいやまだそれってば早計なのぞ」と警鐘を鳴らすために「二週間平均は増加傾向である」ことを根拠にしてたのよ。まぁ今やってみたように、「おっしゃる通り」ではあるよ。けど、この説明はちとマズイんじゃないのかな、とワタシは思ったの。
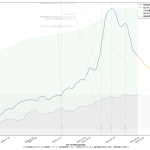
ここ数日強調してた通り、また、メディアがしつこく伝える通り、日々の新規感染判明数は「二週間前の行動の反映である、と考えるのが実情に合う」ことになっている。これは、潜伏期間と、感染者が感染を自覚してから検査を受けて判明するまでのタイムラグをかんがみて、二週間くらいだから。だからこそ「今日の結果に基づいて行動を決めるのでは必ず手遅れる」てのがワタシの主張だし、合理的な判断をする専門家やジャーナリストほどワタシと同じ考えに立ってる。
この際に注意しなければならないのは、「週平均」という算術そのものにも問題がある、てことなのね。日常的に使っている技術者には常識だし、そうでないなら wikipedia でもみてもらえれば良いんだけど、「週平均」(というか移動平均)はその仕組み上、「一週間遅れ」の傾向を見ることになるわけね。だから、「新型コロナウィルス感染症の新規感染者報告数の週平均」というのは、「3週間前の行動の反映」ということなわけ。この「3週間前の行動の反映」という傾向を「一週間延長」すればようやく「二週間前の行動の反映」の観察につながるわけなのよ。わかるかな、「二週間後予測」ですらもう「一週間前の行動の通信簿」でしかないわけ。
岡田さんが、国民に対して「喜ぶのはまだ早い」と警告するのは、行為としては正しいと思うよ。けどね、「二週間平均」を直接根拠にするのはあまりに乱暴で説明不足に過ぎると思う。これは本日時点での二週間平均は「一か月前の行動に対する通信簿」。これを根拠にしたいならさすがに「なぜ?」をちゃんと説明しないといけないと思う。
「喜ぶのはまだ早い」と警告したいなら、ワタシは素直に減少予測曲線を根拠にしたらいいと思う。西浦さんがやってるまさにソレだね。北村先生もここ数日それをやってた。「この落ち方では足りない」と言えばいいのであって、「二週間平均では増加傾向」には説得力はない。これ、「減少し始め」の傾向を二週間遅れでみることそのものなので、「そりゃそーだ」てことなのよ。