これがわかりやすいのかどうか、てことだ。
(10)までの主張の論旨は、「皆が納得出来て、なおかつ「良い」見える化を皆で共有すべし、未来予測もそえて」てことだったわけだね。その意味で、「実効再生産数」と「倍加時間」は微妙だと思っている。特に前者。ただ、後者の可視化をそういえば見たことないなぁと思ってなぁ。
1 # -*- coding: utf-8-unix -*-
2 import io
3 import csv
4 import datetime
5 import numpy as np
6
7
8 _PREFCODE = {
9 '北海道': 1,
10 '青森県': 2,
11 '岩手県': 3,
12 '宮城県': 4,
13 '秋田県': 5,
14 '山形県': 6,
15 '福島県': 7,
16 '茨城県': 8,
17 '栃木県': 9,
18 '群馬県': 10,
19 '埼玉県': 11,
20 '千葉県': 12,
21 '東京都': 13,
22 '神奈川県': 14,
23 '新潟県': 15,
24 '富山県': 16,
25 '石川県': 17,
26 '福井県': 18,
27 '山梨県': 19,
28 '長野県': 20,
29 '岐阜県': 21,
30 '静岡県': 22,
31 '愛知県': 23,
32 '三重県': 24,
33 '滋賀県': 25,
34 '京都府': 26,
35 '大阪府': 27,
36 '兵庫県': 28,
37 '奈良県': 29,
38 '和歌山県': 30,
39 '鳥取県': 31,
40 '島根県': 32,
41 '岡山県': 33,
42 '広島県': 34,
43 '山口県': 35,
44 '徳島県': 36,
45 '香川県': 37,
46 '愛媛県': 38,
47 '高知県': 39,
48 '福岡県': 40,
49 '佐賀県': 41,
50 '長崎県': 42,
51 '熊本県': 43,
52 '大分県': 44,
53 '宮崎県': 45,
54 '鹿児島県': 46,
55 '沖縄県': 47,
56 }
57 _COLSNM = (
58 "testedPositive",
59 "peopleTested",
60 "hospitalized",
61 "serious",
62 "discharged",
63 "deaths",
64 "effectiveReproductionNumber",
65 )
66 def _tonpa(fn):
67 # 元データ prefectures.csv の著作権:
68 # 『東洋経済オンライン「新型コロナウイルス 国内感染の状況」制作:荻原和樹』
69 #
70 # 1. 開始日が NHK まとめと違う
71 # 2. 更新のない都道府県は省略してある
72 # 3. 日付は一応抜けなく連続している、今のところ
73 #
74 # NHKまとめのほうで密行列として扱った同じノリにしたい、ここでは面倒だけど。
75 # つまり、列方向に都道府県、行方向に日付。
76 result = {
77 k: np.zeros((1, 47))
78 for k in _COLSNM}
79 reader = csv.reader(io.open(fn, encoding="utf-8-sig"))
80 next(reader)
81 def _f(d):
82 if not d or d == "-":
83 # 不明とか未報告の意味だと思う。
84 return float("nan")
85 return float(d)
86
87 era = datetime.datetime(2020, 1, 16) # NHKまとめのほうの起点日
88 curdate = era
89 for line in reader:
90 date = datetime.datetime(*map(int, line[:3]))
91 dadv = (date - curdate).days
92 data = list(map(_f, line[5:]))
93 p = _PREFCODE[line[3]]
94 for i, k in enumerate(_COLSNM):
95 for _ in range(dadv):
96 result[k] = np.vstack((result[k], np.zeros((1, 47))))
97 result[k][-1, p - 1] = data[i]
98 curdate = date
99 # 元データについて、どうやら厚労省のオープンデータそのものを転記しただけの
100 # 項目は累積でのみ管理しているらしく、この csv 全体では「累積だったりそうで
101 # なかったり」と大変使いにくい。ゆえ、累積のものは読み替えておく。
102 for k in ("testedPositive", "peopleTested", "discharged", "deaths",):
103 result[k][1:] = (
104 result[k] - np.roll(result[k], 1, axis=0))[1:]
105 #
106 # peopleTested の最新2日分はゴミ:
107 # ---
108 # 2021,1,28,東京都,Tokyo, 97571, 1303823.0, 14957.0, 150, 81767.0, 847, 0.74
109 # 2021,1,29,東京都,Tokyo, 98439, 1309999.0, 13807.0, 147, 83768.0, 864, 0.76
110 # 2021,1,30,東京都,Tokyo, 99208, 1309999.0, 13383.0, 141, 84942.0, 883, 0.77
111 # 2021,1,31,東京都,Tokyo, 99841, 1309999.0, 13257.0, 140, 85698.0, 886, 0.78
112 # ---
113 # 集計が3日遅れ、てこと、だろう。
114 result["peopleTested"][np.where(result["peopleTested"] == 0.0)] = float("nan")
115 # 移動平均
116 for k in ("testedPositive", "peopleTested", "hospitalized", "serious", "deaths"):
117 k1, k2 = k, k + "_movavg"
118 result[k2] = np.zeros(result[k1].shape)
119 for dt in range(len(result[k1])):
120 result[k2][dt, :] = result[k1][
121 max(0, dt - 6):dt + 1, :].mean(axis=0)
122 #
123 np.savez(io.open("toyokeizai_online_covid19.npz", "wb"), **result)
124
125
126 if __name__ == '__main__':
127 _tonpa("prefectures.csv")
基本的に今回のは累計ベースで、なおかつ前回と同じく、最大値を1.0とした比で。
1 # -*- coding: utf-8 -*-
2 import io
3 import datetime
4 import functools
5 import numpy as np
6 import matplotlib as mpl
7 import matplotlib.pyplot as plt
8 import matplotlib.font_manager
9 import random
10
11
12 def _vis(dattko):
13 fontprop = matplotlib.font_manager.FontProperties(
14 fname="c:/Windows/Fonts/meiryo.ttc")
15
16 era = "2020/1/16" # 木曜日
17 era = datetime.datetime(*map(int, era.split("/")))
18 (wh_sl, wh_n) = (slice(12, 12+1), "東京")
19
20 #
21 fig, ax1 = plt.subplots(tight_layout=True)
22 lines = []
23 fig.set_size_inches(16.53 * 1.4, 11.69)
24 ax2 = ax1.twinx()
25 ax2.invert_yaxis()
26
27 clrs = ["tab:blue", "tab:green", "tab:red"]
28 T = np.array([era + datetime.timedelta(t)
29 for t in range(len(dattko["testedPositive_movavg"][:,wh_sl].sum(axis=1)))])
30
31 for c, k in enumerate(("testedPositive", "serious", "deaths")):
32 X = dattko[k][:,wh_sl].sum(axis=1)
33 X = np.array([np.nansum(X[:t1]) for t1 in range(len(T))])
34 #
35 l, = ax1.plot(T, X / np.nanmax(X), linestyle="dashed", alpha=0.3, color=clrs[c])
36 lines.append((l, "{} (累積)".format(k)))
37 #
38 t0 = np.where(X > 0)[0][0]
39 dblt = [
40 (t1 - max(t0, (t1 - 60))) * np.log(2) / np.log(
41 X[t1] / X[max(t0, (t1 - 60))])
42 for t1 in range(len(T))]
43 dt = -int(dblt[-1])
44 l, = ax2.plot(T, dblt, color=clrs[c])
45 lines.append((l, "doubling time of {}".format(k)))
46 #
47 ax1.legend([l for l, t in lines], [t for l, t in lines], shadow=True, prop=fontprop)
48 for evdt in (
49 datetime.datetime(2020, 4, 14),
50 datetime.datetime(2020, 5, 3),
51 datetime.datetime(2020, 5, 17),
52 datetime.datetime(2021, 1, 11),
53 datetime.datetime(2021, 1, 25),
54 #datetime.datetime(2021, 1, 30),
55 ):
56 ax1.annotate("{}".format(str(evdt)[:len("????-??-??")]),
57 xy=(evdt, 0.1), xycoords='data',
58 xytext=(
59 ((evdt - era).days / (T[-1] - era).days),
60 0.05 + (random.random() / 5)),
61 textcoords='axes fraction',
62 arrowprops=dict(facecolor='black', width=0.0001, alpha=0.1),
63 horizontalalignment='right', verticalalignment='top',
64 alpha=0.8,
65 fontproperties=fontprop)
66 ax1.vlines([evdt], 0, 1, transform=ax1.get_xaxis_transform(), alpha=0.3)
67 df = datetime.datetime
68 ax1.axvspan(df(2020, 2, 1), df(2020, 3, 1), facecolor="lightgray", alpha=0.3)
69 ax1.axvspan(df(2020, 4, 1), df(2020, 5, 1), facecolor="lightgray", alpha=0.3)
70 ax1.axvspan(df(2020, 6, 1), df(2020, 7, 1), facecolor="lightgray", alpha=0.3)
71 ax1.axvspan(df(2020, 8, 1), df(2020, 9, 1), facecolor="lightgray", alpha=0.3)
72 ax1.axvspan(df(2020, 10, 1), df(2020, 11, 1), facecolor="lightgray", alpha=0.3)
73 ax1.axvspan(df(2020, 12, 1), df(2021, 1, 1), facecolor="lightgray", alpha=0.3)
74 ax1.axvspan(df(2021, 2, 1), T[-1], facecolor="lightgray", alpha=0.3)
75 ax1.set_xlabel(
76 "「東洋経済オンライン「新型コロナウイルス 国内感染の状況」制作:荻原和樹」を加工",
77 fontproperties=fontprop)
78 #ax1.grid(True)
79 #fig.autofmt_xdate()
80 #plt.show()
81 fig.savefig("dblt.png")
82 plt.close(fig)
83
84
85 if __name__ == '__main__':
86 fn2 = "toyokeizai_online_covid19.npz"
87 _vis(np.load(io.open(fn2, "rb")))
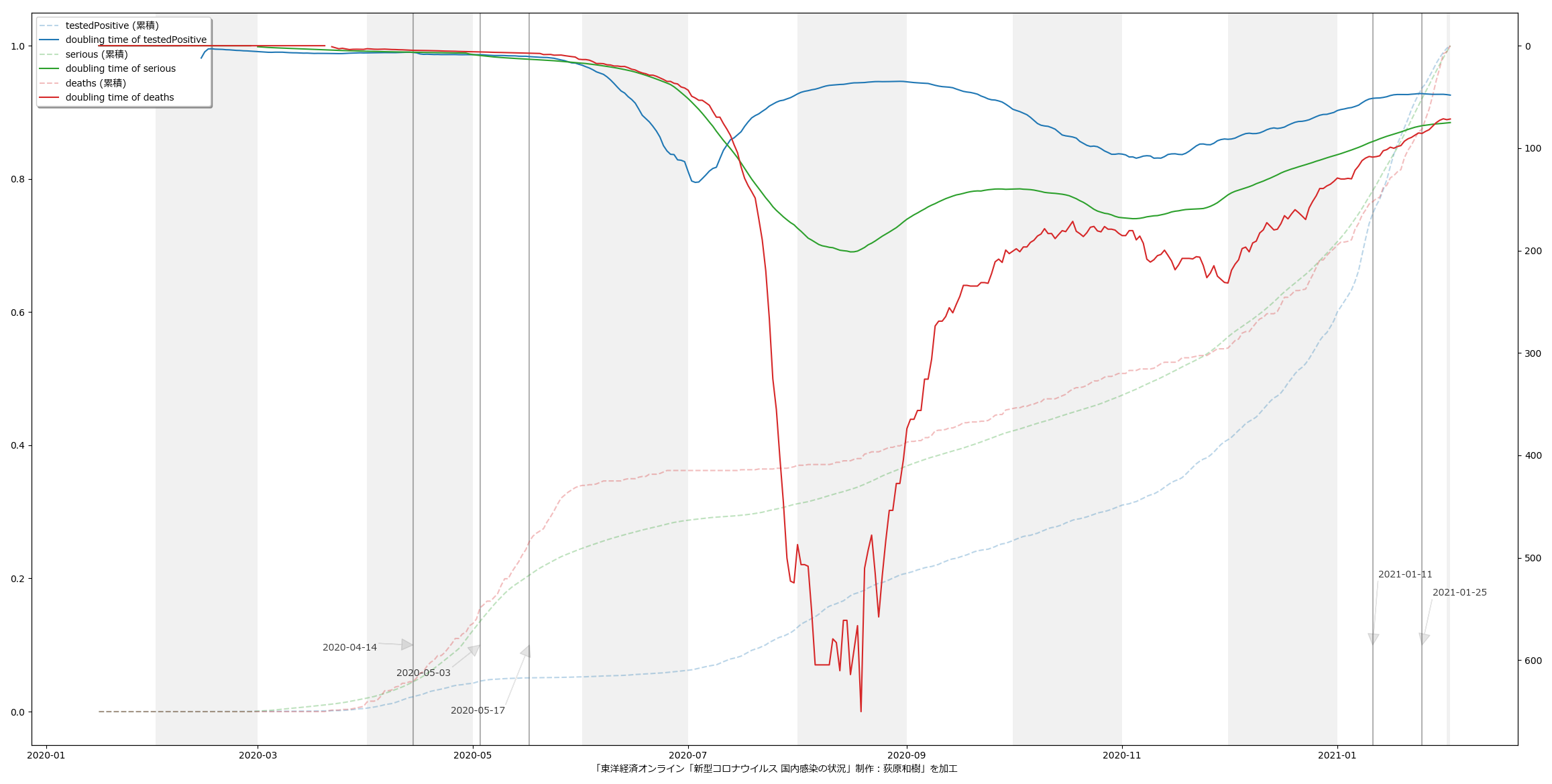
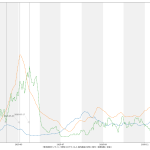
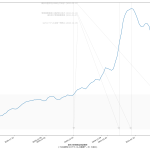
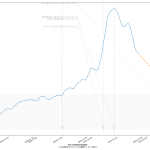
なんとなく合ってそうではあるけど、信用はしないでね。これが正しいとしたら、やはり皆がやべーと感じだした去年12月から倍加時間が短くなっていったのが見て取れる。(ちなみに t1 – 60 として2か月をみている部分は汎用的な考え方ではないので注意。確実に増減がある範囲として適当に選んだだけ。)
実効再生産数、倍加時間の両方に共通で言えることなのだが、注意すべきは、これらはともに、「それそのものは過去実績が辿ってきた傾向でしかない」、てこと。文字通り「過去グラフの傾き」そのものを求めているのと本質的に完全に同じ。(実効再生産数については、真の値の話ではなくて、感染者数推移から求められた推計の計算の話ね、念のため。)
だから、これらはともに「単にグラフの傾きを求める」ことの別の見方・アプローチであり、そしてそれが「わかりやすいかどうか」てことさね。言い換えると「何かを言いやすいかどうか」(主張のインパクト足り得るか、とかね)。指数関数的に増加している傾きが「増えてる増えてるぅ」てのはグラフからなかなか正確には読み取りにくいが、倍加時間であればよりクリアにみえる、てことね。
だからね、実効再生産数、倍加時間ともに、「過去の傾向に基づくこのトレンドが続くとするならば、あと~日で倍になる、ヤバい」ということを言いたいときにはいいんだけれど、まさに今日時点のように、新規感染者数が既にピークアウトしていることが明らかで、そこから一か月後に死亡者数のピークアウトすると想定可能である状態の場合、「死亡者数の倍加速度が上がり続けています」という注意喚起は的外れなのよね。「死亡者数の倍加速度が上がり続けてきた」という過去形なの、過去をみてるの、これは。
あと、もう一つ問題。そもそも分母の数によって世界が違う、てこと。実効再生産数の話であれば、感染者数が100人の場合の1.0と10万人の場合の1.0がどう違うかは、説明されれば小学生でも理解できる。100人が100人に感染させるのなら、新規の増加は100人、対して、10万人が10万人に感染させるのだから、新規の増加は10万人、どちらも実効再生産数は1.0。それを理解しないでこれを使って議論することが大変危険。てことね。
なんでもそうなんだけれど、こうしたものをみる場合は、最後にはやっぱり「自分事」という目線が必要なのだと思うよ。自分が医療者だとして、「明日10万人感染者が増えるとしたら、ワタシのクリニックには何十人も患者が押し寄せる」という「現実」があるわけだ、「実効再生産数=1.0」だけではそこに至ることは絶対に出来ない。「「実効再生産数=1.0」、なので」の先が必要だ、てこと。
2021-02-05追記?:
「追記」としてわざわざ書き直すような内容ではないんだけれど、スクリプトのアホさがちょっぴり気になっていたので:
1 # -*- coding: utf-8 -*-
2 import io
3 import datetime
4 import functools
5 import numpy as np
6 import matplotlib as mpl
7 import matplotlib.pyplot as plt
8 import matplotlib.font_manager
9 import random
10
11
12 def _vis(dattko):
13 fontprop = matplotlib.font_manager.FontProperties(
14 fname="c:/Windows/Fonts/meiryo.ttc")
15
16 era = "2020/1/16" # 木曜日
17 era = datetime.date(*map(int, era.split("/")))
18 (wh_sl, wh_n) = (slice(12, 12+1), "東京")
19
20 #
21 fig, ax1 = plt.subplots(tight_layout=True)
22 lines = []
23 fig.set_size_inches(16.53 * 1.4, 11.69)
24 ax2 = ax1.twinx()
25 ax2.invert_yaxis()
26
27 clrs = ["tab:blue", "tab:green", "tab:red"]
28 T = np.array([era + datetime.timedelta(t)
29 for t in range(len(dattko["testedPositive_movavg"][:,wh_sl].sum(axis=1)))])
30
31 for c, k in enumerate(("testedPositive", "serious", "deaths")):
32 X = dattko[k][:,wh_sl].sum(axis=1)
33 X = np.array([np.nansum(X[:t1]) for t1 in range(len(T))])
34 #
35 l, = ax1.plot(T, X / np.nanmax(X), linestyle="dashed", alpha=0.3, color=clrs[c])
36 lines.append((l, "{} (累積)".format(k)))
37 #
38 t0 = np.where(X > 0)[0][0]
39 dblt = [
40 (t1 - max(t0, (t1 - 60))) * np.log(2) / np.log(
41 X[t1] / X[max(t0, (t1 - 60))])
42 for t1 in range(len(T))]
43 dt = -int(dblt[-1])
44 l, = ax2.plot(T, dblt, color=clrs[c])
45 lines.append((l, "doubling time of {}".format(k)))
46 #
47 ax1.legend([l for l, t in lines], [t for l, t in lines], shadow=True, prop=fontprop)
48 for evdt in (
49 datetime.date(2020, 4, 14),
50 datetime.date(2020, 5, 3),
51 datetime.date(2020, 5, 17),
52 datetime.date(2021, 1, 11),
53 datetime.date(2021, 1, 25),
54 #datetime.date(2021, 1, 30),
55 ):
56 ax1.annotate("{}".format(str(evdt)),
57 xy=(evdt, 0.1), xycoords='data',
58 xytext=(
59 ((evdt - era).days / (T[-1] - era).days),
60 0.05 + (random.random() / 5)),
61 textcoords='axes fraction',
62 arrowprops=dict(facecolor='black', width=0.0001, alpha=0.1),
63 horizontalalignment='right', verticalalignment='top',
64 alpha=0.8,
65 fontproperties=fontprop)
66 ax1.vlines([evdt], 0, 1, transform=ax1.get_xaxis_transform(), alpha=0.3)
67 for m in range(0, int(np.ceil((T[-1] - T[0]).days / 30)), 2):
68 dts = datetime.date(2020, 2, 1) + m * datetime.timedelta(days=31)
69 dts = dts.replace(day=1)
70 dte = dts + datetime.timedelta(days=31)
71 dte = dte.replace(day=1)
72 if dts <= T[-1] and T[-1] <= dte:
73 dte = T[-1]
74 ax1.axvspan(dts, dte, facecolor="lightgray", alpha=0.3)
75 ax1.set_xlabel(
76 "「東洋経済オンライン「新型コロナウイルス 国内感染の状況」制作:荻原和樹」を加工",
77 fontproperties=fontprop)
78 #ax1.grid(True)
79 #fig.autofmt_xdate()
80 #plt.show()
81 fig.savefig("dblt.png")
82 plt.close(fig)
83
84
85 if __name__ == '__main__':
86 fn2 = "toyokeizai_online_covid19.npz"
87 _vis(np.load(io.open(fn2, "rb")))
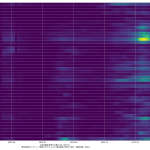
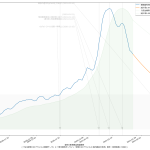
見ての通り(?)dateの使い方と「縞々ing」の件、な。絵は最新データを使った以外は当然おんなじ:
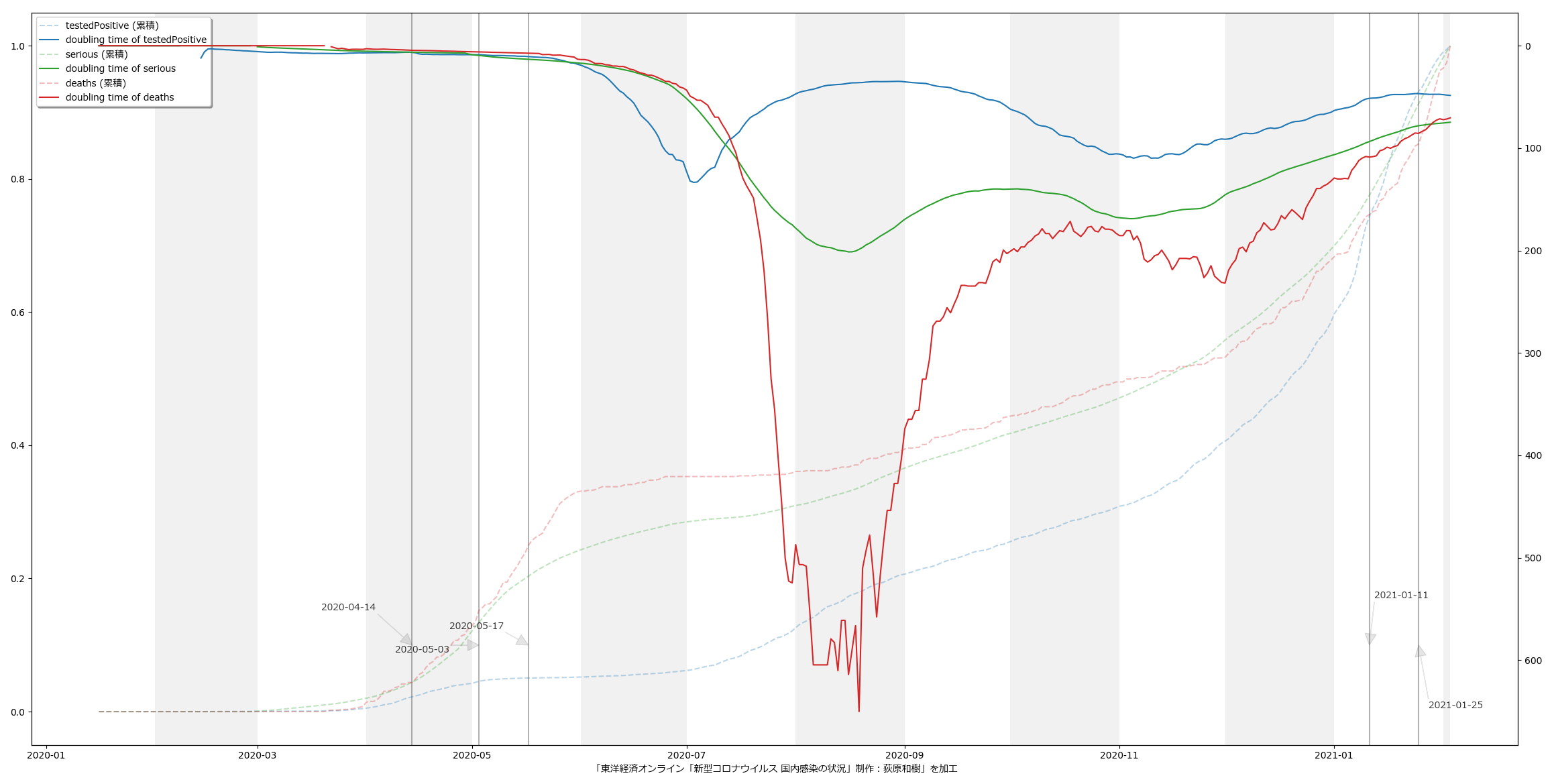
これだけだとあんまりなので、昨日した話をもう少し。
実際、昨日のは、まさしく昨日のワイドショー(Nスタかひるおびかどっちかだったか?)に反応して書いたのよ。「倍加時間」という言葉を使わずに、「これまで死者数が~人になるのに~日かかっていましたが、今では~人に到達するのに~日しかかかっていないぴょーん、びっくりびっくり」てな具合。つまりさ、「それ、今言うことじゃなく12月頭に言うこと」てこと。今それを言うのは「イマサラ」なわけよ、わかるよね、だってこれ「成績発表」なんだから。注意喚起に使いたい場合は、ほかの指標とセットで。具体的には最新の傾向。上昇傾向とセットで倍加時間を示すのはいいけど、減少傾向に転じている場合は、誤解を招くので倍加時間で説明するのは慎重になったほうがよろしい。
2021-03-05追記:
話としてはむしろこれに対する追記かもしらん。「倍加時間、実効再生産数、前週比のいずれも、計算的には単に過去グラフの傾きを求める行為と本質的には大差なし」みたいなことを口走った。「ならばこいつら全部一気にみるとどう見えるんだい?」てのがちょっと気になった、てだけの話:
1 # -*- coding: utf-8 -*-
2 import io
3 import datetime
4 import numpy as np
5 import matplotlib.pyplot as plt
6 import matplotlib.font_manager
7
8
9 def _vis(dattko):
10 fontprop = matplotlib.font_manager.FontProperties(
11 fname="c:/Windows/Fonts/meiryo.ttc")
12
13 era = "2020/1/16" # 木曜日
14 era = datetime.date(*map(int, era.split("/")))
15 (wh_sl, wh_n) = (slice(12, 12+1), "東京")
16
17 k = "testedPositive_movavg"
18 T = np.array([era + datetime.timedelta(t)
19 for t in range(len(dattko[k][:,wh_sl].sum(axis=1)))])
20
21 # 前週比
22 Z1 = dattko[k][:,wh_sl].sum(axis=1)
23 # 1.「100%」となるケースにおいて、純然たるゴミといえるパターン:
24 # 前週も今週も(限りなく)0
25 # このケースは「無意味」ということで nan としておく。としないと、まったく問題が
26 # ない「一人が一人になった!」として「前週比1倍未満ではない」ものとしてピックアップ
27 # することになり、馬鹿げている。
28 # 2.「前週比」の計算で、分母が1未満だと発散してウザいので、シンプルに1としておく。
29 Z1[np.where(np.logical_and(Z1 < 1, np.roll(Z1, 7, axis=0) < 1))] = np.nan
30 Z1[np.where(Z1 < 1)] = 1
31 Z1 /= np.roll(Z1, 7, axis=0)
32 Z1[np.where(np.isnan(Z1))] = 0
33
34 # 実効再生産数
35 Z2 = dattko["effectiveReproductionNumber"][:,wh_sl].sum(axis=1)
36
37 # 倍加時間
38 _accum = dattko[k][:,wh_sl].sum(axis=1)
39 _accum = np.array([np.nansum(_accum[:t1]) for t1 in range(len(T))])
40 #
41 t0 = np.where(_accum > 0)[0][0]
42 Z3 = np.array([
43 (t1 - max(t0, (t1 - 60))) * np.log(2) / np.log(
44 _accum[t1] / _accum[max(t0, (t1 - 60))])
45 for t1 in range(len(T))])
46
47 #
48 fig, ax1 = plt.subplots(tight_layout=True)
49 lines = []
50 fig.set_size_inches(16.53 * 1.4, 11.69)
51 ax2 = ax1.twinx()
52 ax2.invert_yaxis()
53 clrs = ["tab:blue", "tab:green", "tab:red"]
54 #
55 l, = ax1.plot(T, Z1, color=clrs[0])
56 lines.append((l, "前週比"))
57 #
58 l, = ax1.plot(T, Z2, color=clrs[1])
59 lines.append((l, "実効再生産数"))
60 #
61 l, = ax2.plot(T, Z3, color=clrs[2])
62 lines.append((l, "倍加時間"))
63 #
64 ax1.set_xlabel(
65 "「東洋経済オンライン「新型コロナウイルス 国内感染の状況」」を加工",
66 fontproperties=fontprop)
67 ax1.set_ylabel(
68 "前週比, 実効再生産数",
69 fontproperties=fontprop)
70 ax2.set_ylabel(
71 "倍加時間(日)",
72 fontproperties=fontprop)
73 #
74 ax1.legend([l for l, t in lines], [t for l, t in lines], shadow=True, prop=fontprop)
75 ax1.grid(True)
76 fig.savefig("{}_{}_{}.png".format(k, "dblt_etc", str(T[-1])))
77 #plt.show()
78 plt.close(fig)
79
80
81 if __name__ == '__main__':
82 fn2 = "toyokeizai_online_covid19.npz"
83 _vis(np.load(io.open(fn2, "rb")))
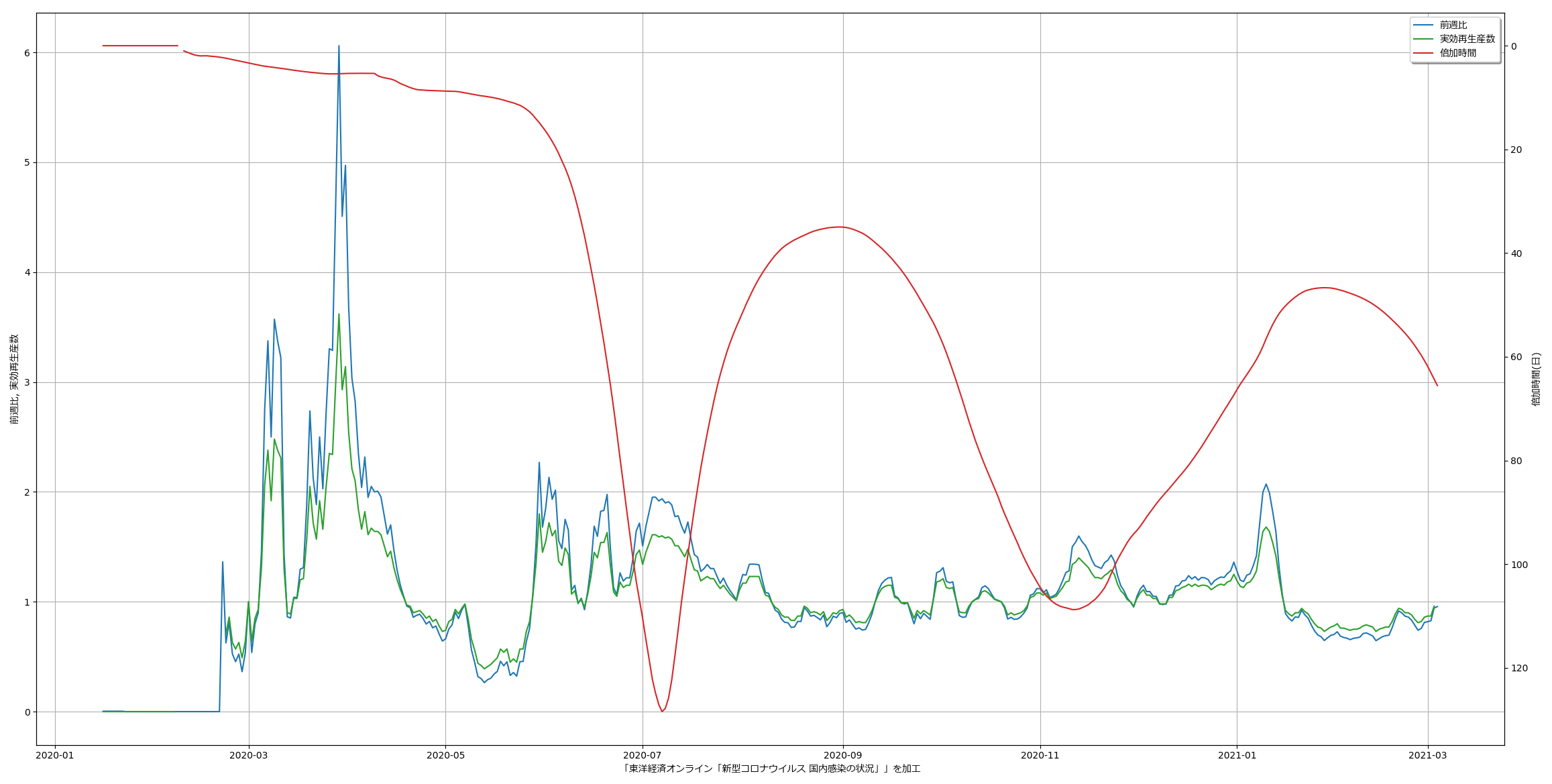
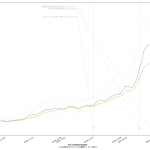
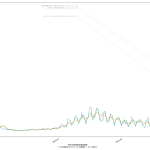
改めて繰り返しておきたい。「これらは紛らわしいので見せないほうが良い」と言いたくもなるほどにちょいと厄介な指標たちである。なぜに厄介かというと、「複数の指標を組み合わせることが大前提となる議論のうちの、第二以下優先」なのにも関わらず、たぶん「かっこいい」みたいな、いわゆる雰囲気重視で主張が行われる場合に「一番目立ってしまう」てことだったりする。実際問題「実効再生産数=1.2」という値そのもので言えることは実は言うほど多くなくて、「増えていく」という一語しか言えない。前週比と本質的に同じであることが理解できるならわかるだろうと思うのだが、「先週が1人でした」に対して「なんとっっ、200% の増加ですっ」と驚くことは「バカがすること」だとわかる、よね? その先、「200%増加すると~人になる」という実数の把握を同時に行うなどしないと、ほとんどの議論は意味がない。つまり重要なのは200%という値そのものではなくて、200%の「効果」てこと。てことがなかなか理解しにくいよなぁと思う。
2021-03-07追記:
一つ前の追記と同じく、これに対する追記かもしらん、のではあるけれど、一つ前の追記で口走った「説明しづらい」の件について、「だったら両方同時に見ちゃえばいいんでは」をやってみたかったの:
1 # -*- coding: utf-8-unix -*-
2 import io
3 import datetime
4 import numpy as np
5 import matplotlib.pyplot as plt
6 import matplotlib.font_manager
7 import matplotlib.ticker as ticker
8 from matplotlib.colors import BoundaryNorm, Normalize
9
10
11 class MidpointNormalize(Normalize):
12 def __init__(self, vmin=None, vmax=None, vcenter=None, clip=False):
13 self.vcenter = vcenter
14 Normalize.__init__(self, vmin, vmax, clip)
15
16 def __call__(self, value, clip=None):
17 # I'm ignoring masked values and all kinds of edge cases to make a
18 # simple example...
19 x, y = [self.vmin, self.vcenter, self.vmax], [0, 0.5, 1]
20 return np.ma.masked_array(np.interp(value, x, y))
21
22
23 def _vis(dattko):
24 #
25 era = datetime.date(2020, 1, 16)
26 #
27 fontprop = matplotlib.font_manager.FontProperties(
28 fname="c:/Windows/Fonts/meiryo.ttc")
29
30 era = "2020/1/16" # 木曜日
31 era = datetime.date(*map(int, era.split("/")))
32 (wh_sl, wh_n) = (slice(12, 12+1), "東京")
33
34 k = "testedPositive_movavg"
35 T = np.array([era + datetime.timedelta(t)
36 for t in range(len(dattko[k][:,wh_sl].sum(axis=1)))])
37
38 # -----
39 # 新規陽性者, 前週比
40 Z0 = dattko[k][:,wh_sl].sum(axis=1)
41 Z1 = np.array(Z0)
42 Z1[np.where(np.logical_and(Z1 < 1, np.roll(Z1, 7, axis=0) < 1))] = np.nan
43 Z1[np.where(Z1 < 1)] = 1
44 Z1 /= np.roll(Z1, 7, axis=0)
45 Z1[np.where(np.isnan(Z1))] = 0
46 # -----
47
48 # ---------------------------------------------------
49 # 案1
50 # 失敗作。alpha を指定した振る舞いがよろしくない。matplotlib v3.0.3(windows 版)以外
51 # 試してないが、縞模様になってしまうのはバグのような気がする。
52 fig, ax1 = plt.subplots(tight_layout=True)
53 fig.set_size_inches(16.53 * 1.2, 11.69)
54 ax1.plot(T, Z0)
55 ax1.set_xlim((T[0], T[-1]))
56 ax2 = ax1.twinx()
57 Y = np.arange(2)
58 X, Y = np.meshgrid(T, Y)
59 norm = MidpointNormalize(vcenter=0.9, vmax=2.0)
60 ax2.pcolor(X, Y, [Z1], norm=norm, cmap="coolwarm", alpha=0.4)
61 ax2.set_yticks([])
62 ax2.set_xlabel(
63 "{}\n「東洋経済オンライン「新型コロナウイルス 国内感染の状況」」を加工".format(
64 "新規陽性者数(7日移動平均)"),
65 fontproperties=fontprop)
66 ax1.grid(True)
67 fig.savefig("{}_{}_withcpw_{}_1.png".format(k, wh_n, str(T[-1])))
68 #plt.show()
69 plt.close(fig)
70
71 # ---------------------------------------------------
72 # 案2 (重ねてダメなら並べてみろ)
73 fig, (ax1, ax2) = plt.subplots(
74 2, 1, gridspec_kw={'height_ratios': [20, 1]}, tight_layout=True)
75 fig.set_size_inches(16.53 * 1.2, 11.69)
76 ax1.plot(T, Z0)
77 ax1.set_xlim((T[0], T[-1]))
78 Y = np.arange(2)
79 X, Y = np.meshgrid(T, Y)
80 norm = MidpointNormalize(vcenter=0.9, vmax=2.0)
81 ax2.pcolor(X, Y, [Z1], norm=norm, cmap="coolwarm")
82 ax1.tick_params(
83 axis="x", bottom=False, top=True, labelbottom=False, labeltop=True)
84 #ax1.tick_params(
85 # axis="y", right=True, labelright=True)
86 ax2.set_yticks([])
87 ax2.set_xlabel(
88 "{}\n「東洋経済オンライン「新型コロナウイルス 国内感染の状況」」を加工".format(
89 "新規陽性者数(7日移動平均)"),
90 fontproperties=fontprop)
91 ax1.grid(True)
92 fig.savefig("{}_{}_withcpw_{}_2.png".format(k, wh_n, str(T[-1])))
93 #plt.show()
94 plt.close(fig)
95 # -----
96
97
98 if __name__ == '__main__':
99 _vis(np.load(io.open("toyokeizai_online_covid19.npz", "rb")))
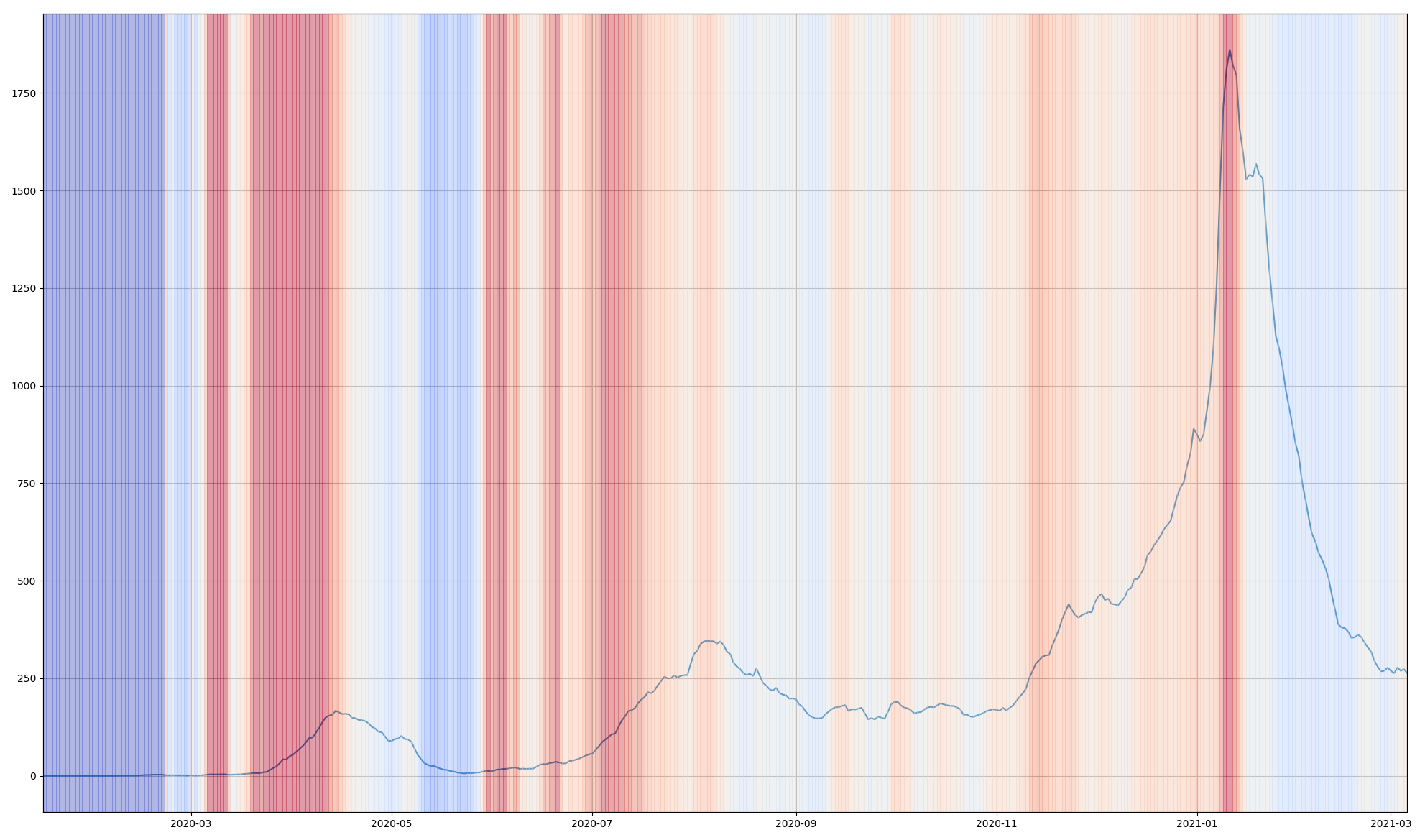
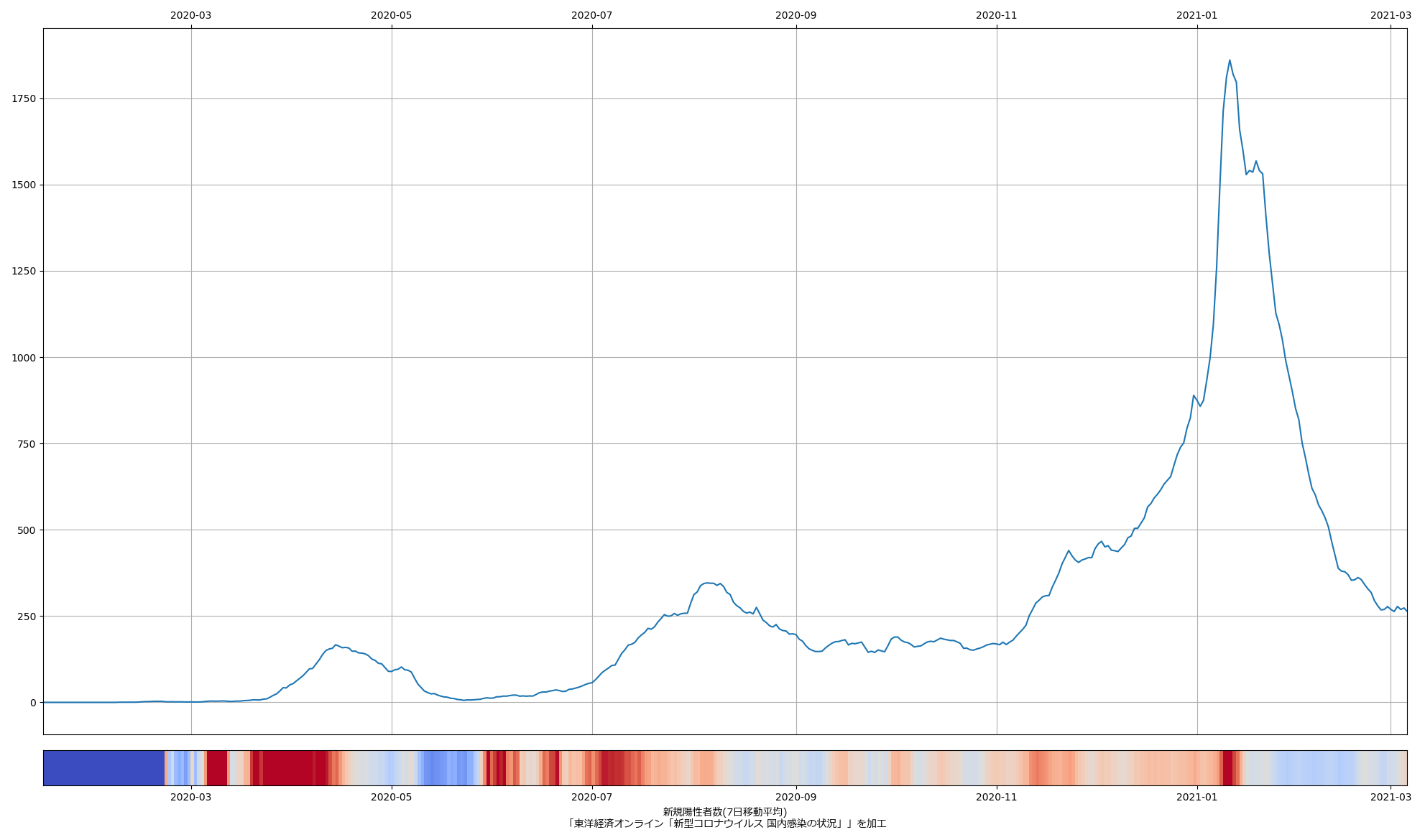
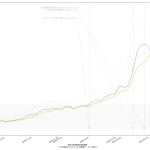
「前週比」だけをみてると上述の誤解を招きやすく、また、シンプルに新規感染者数と前週比を二つの折れ線で描画するのも、これはこれでそそっかしい読み手は誤解してしまうが、この見せ方であれば、まぁ割とわかりやすいかもしれんねと思う。
なお、本日時点は「下げ止まりどころか横ばい」であり、このことを根拠にして緊急事態宣言が延長されたわけだが、それ自体は前週比を見なくてもわかることである。
2021-03-10追記:
今朝だったか昨日だったか、内容はみてないんだけれど、朝の情報番組(TBS)の番組情報見出しが「新規感染者数下げ止まりか?」みたいなのだったのが、やっぱりとてつもなく違和感でな。
ワタシがここ何週間かで主張してきたことってのは、「良い見える化を共有せよ」ということであった。これは、報道機関に向けての主張ということになるんだけれど、そうすることによって「政府の動き」を早めることが出来るのではないのか、てことが動機なわけね。だけどさ…、「新規感染者数下げ止まりか?」みたいなことを今言われると、だな…。
「いや、それ、最低でも2週間前に言うこと」なの。というか専門家はとっくに指摘してたし、なんなら「キミらも言っとったやろが」。結局「同じものをみてない」問題に行き着くんだと思うんだよなぁ。TBS のその情報番組が言いたいのはきっと「新規感染者数下げ止まりと専門家が言ってたことはどうやら本当のようだぜ、おれらが考えてみたところによれば、と、今更ながらちゃんと自分ごととして実感できましたぜ」てことなのであろ? つまり、「これまではそうまでは思ってなかった」と。前回追記の絵で既にちゃんと「間違いなく下げ止まってる」ことが自明なはずなわけ。昨日までのデータで可視化すればこんな:
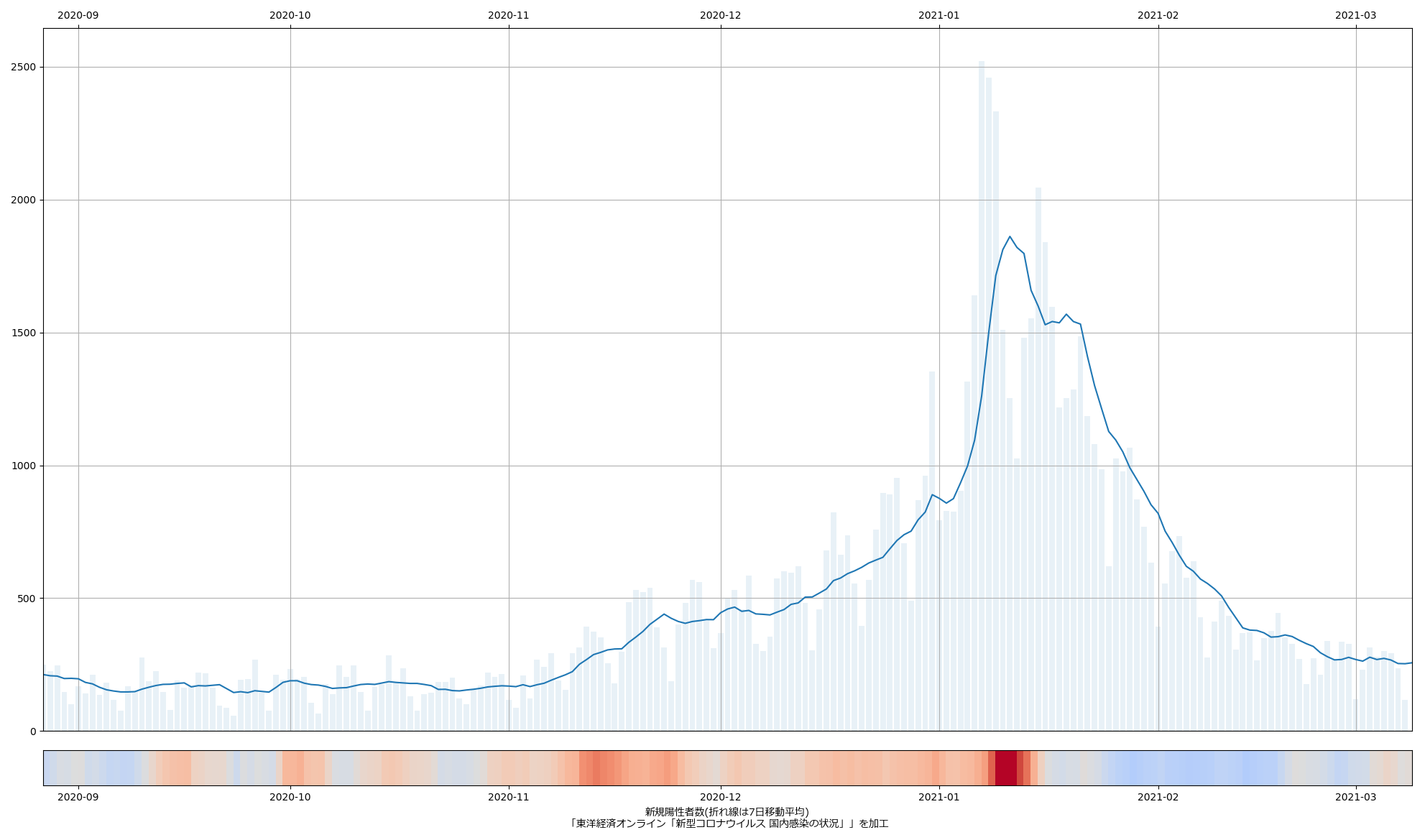
このグラフをみて「下げ止まってるわけねーだろヴァーカヴァーカ」というやつぁいねいのであって、これこそが「見える化」の効果、ね。これこそ「エビデンス」であろうよ。(この可視化に基づく「判断」が人によって違うことは構わないのである。そうではなくて、そもそもこの状態を「見てない/見ようとしてない」ならば問題だ、てこと。)
「政府の動きは、見える化の共有を進めれば、最低でも一週間は早められる」というのはつまり「最低でも一週間遅い」ということを言いたいということなわけだが、だとするなら、報道も一週間遅い、てこと。ほかのとこで、「二週間先を予測して行動することでやっと周回、一週間先予測で動くのは周回遅れ、本日までの過去データのみに基づいて動くのは二周回遅れ」と言った。政府の動きを指してそういったのだが、ということは「TBS、お前もか」てことに。
一年経って、随分良くなったとは思うんだけれど、このコロナ禍が始まってすぐの頃に最も不満を感じてたのって、実は政府の動きなんかではなくて、「報道機関の他人事感」(あるいは「上級国民意識」)だったんだよ。「お前らが率先しろ」と。それが影響力が強い「公人」の役目ではないのか、と。確かに「見える化を報道が率先して行え」てのは、こうしたことが手に入りやすい(実現しやすい)という水面下で起こっていた技術革新に気づいていない限り、実践する発想に行きにくいのかもしれないんだけれど、だけどさ、いろいろなことにアンテナ張るのが仕事なんでしょうよ、「デジタル化を推し進めよ」というふうに「政権批判」出来るのなら、「だったら自分たちも」と出来るはずなのだよ、本来。結局他人事なんだろうなぁと思う。