まぁ毎度悩みの種なのよねこれ。
「chrome でブラウズ出来とるやんけ、なんで wget で持ってくると違う内容なんだ?」なんてことはまぁ、ほんとうに良く起こる。wget、curl、python の urllib などなど、クライアントの数に応じて違う振る舞いを承るハメになる。けれども「chrome で出来てることが出来ないとは何事だ」に関して、ただの html ページそのものだった場合に、もっとも怒り心頭になる。https の認証だぁなんだといった複雑で難しいものがあるなら、致し方ないと諦めもつくのだが、たとえば Open Music Archive の tag=folk ページは、ブラウザで見る結果と wget 等で取得する結果が全然違う。さっぱり意味がわからない。
サーバは何らかクライアントからのリクエストを区別しているのではあろうが、これをたとえば python のライブラリのレベルでコントロールするのは簡単なことではなくて、実際 User-Agent の詐称くらいはすぐにでも出来るけれど、それをしても Open Music Archive の例は解決できない。サーバは php で動的に結果を返しているが、まぁ何かをしてるんだろうが、よくわからんのは、同じ Open Music Archive サイト内で wget でも問題ない場合もあるってこと。ほんと何がなんだかわからない。
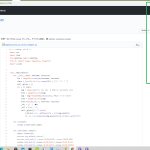
ふと、headless chrome が救世主になるよなぁと思って。今の場合は「--dump-dom」が目的のもの:
1 #! /bin/sh
2 export PATH="/c/Program Files/MPC-HC/:${PATH}"
3
4 oma_in="${1:-http://openmusicarchive.org/browse_tag.php?tag=Memphis}"
5 oma_out=/tmp/tmp$$
6 "/c/Program Files (x86)/Google/Chrome/Application/chrome" --headless \
7 --disable-gpu \
8 --dump-dom "${oma_in}" > "${oma_out}"
9 mpplgen.py \
10 --from_l="${oma_out}" \
11 --li=BSHTML_READER \
12 --additional_reader_params='{
13 "bsreader_bs4_features": "lxml",
14 "bsreader_findcriterias": [{
15 "name": "a",
16 "text": "Download MP3",
17 "attrs": {"class": "link", "target": "_blank"}
18 }],
19 "bsreader_fngetter": "attrs, href",
20 "bsreader_fnpattern": ".*\\.mp3",
21 "bsreader_base": "http://openmusicarchive.org"}' \
22 --exec_p=mpc-hc64
mpplgen.py はエロから始まった異世界スクリプト…。18禁ネタを読みたくないならこちら。18禁に抵抗ないならこちら。元は大したスクリプトじゃなかったんだけど、今ではかなりの力作、我ながら気に入っている。例えば:
1 $ mpplgen.py --from_l="https://podcasts.files.bbci.co.uk/p02nq0gn.rss" --exec_p=mpc-hc64
VLC Media Player とは違って、Media Player Classic は RSS を直接読み込むことは出来ない。けれども over http のメディア再生そのものは出来るので、mpplgen.py が RSS から .m3u8 形式のプレイリストに変換して Media Player Classic に喰わせる、てこと。RSS はね、経路が SSL でない限りは読み込みで問題を起こすことはあまり多くないので、python だけでまかなえることが多い。けれど、先の Open Music Archive は普通の html なので、こうしたもので困りがちで、そのための headless chrome 、てことね。
いやぁハッピーだ、万事おk、となれば良かったんだけれど、そうは問屋がなんとやら。これさ、「html」の場合はこれでいいわけよ、「--dump-dom」でね。だけれどもこれ、chrome が内部でメモリ内に持ってる「document.body.innerHTML」をダンプするわけよ。だから、rss みたいに、XML そのものが欲しい場合には非常に弱った事態になる。何の問題もなく urlretrieve で取得できるものばかりではなくて、やはりサーバでクライアントに制限をかけて 403 を返してくるのは多くて、そうした相手向けに headless に期待したかったんだけれど、この場合は「xml を相応しい見栄えにレンダリングするための html」に変換されたものが「document.body.innerHTML」になってる。xslt スタイルシートが指定されてればご丁寧にそれで処理されたもの。いや、欲しいのはそれじゃのーて…。(ブラウザでみてる場合はそれでいいんだよ、念の為。)
てわけで、救世主度は半減。なかなかうまくいかんもんであるよ。