日本人は日本語でしか検索するわけねーじゃんヴぁーかヴぁーか、という妙な思い込みがこんなアンバランスを生んでいるのではないのかな?
google がこれの基礎を全て持っているのだから、なにゆえにこの機能を実装しないのかがほんとに不思議なのだけれど。
私はまぁヘンなのかもしれんけれど、とにかくワタシ自身のサイトも含め、日本語サイトがヒットしない検索を是が非でも試みようとするわけよ。理由の何割かは「誤訳マター」ね、大抵の日本語で書かれた情報のガセは、誤訳がトリガーになっている。これが稀ならいいけど稀じゃないから、どんなにいいサイトがあるのを知ってようが、英語サイトを優先したい、というマインドなわけだ。だから検索ボックスには、めったなことでは日本語を入力してない。少なくとも技術的なことを調べたい場合はね。割合としては、おそらく日本語を入れて検索してるのは 5% 未満だと思う。
けれども、別にワタシは英語が得意なわけじゃあないわけで、すなわち、「英語サイトから情報を引っ張ってくるための英語」を書くのは、何割かは Google 翻訳のお世話になるわけね。この「検索のためのテキスト(日本語) → Google 翻訳に入力 → これの翻訳結果を選択して右クリックで「~を duckduckgo で検索」」という一連が、時としてダルいわけね。特に「Google 翻訳のページを開く」のがうっとうしいことが多い。ワタシの chrome は、調べもの真っ最中なら30も40もタブを開いていることが多く、そこから google 翻訳のタブを開く(のともともと開いてたタブに戻る)のは、かなり小さなストレスとなって溜まっていく。ひょっとしたら、google 検索の内部では翻訳に基づいた検索結果も拾ってる可能性はあるけれど、ワタシのニーズであるところの「日本語はいらない」のためには、やはり英語を検索ワードにしてしまうのが手っ取り早いの。
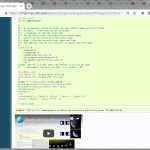
そしてこういう馬鹿げたスクリプトを今さら書こうと思った:
1 #! py -3
2 # sorry, this script is only for windows.
3 # -*- coding: utf-8 -*-
4 import re
5 import urllib.parse
6 import time
7 from contextlib import contextmanager
8 import ctypes
9
10 import bs4
11 from selenium import webdriver
12 from selenium.webdriver.common.by import By
13
14
15 class _GT:
16 def __init__(self):
17 import sys
18 from selenium.webdriver.chrome.options import Options
19
20 opts = Options()
21 opts.add_argument("--disable-gpu")
22 opts.add_argument("--disable-extensions")
23 opts.add_argument("--headless")
24 # opts.add_argument('--log-level=3')
25 opts.add_experimental_option("excludeSwitches", ["enable-logging"])
26 self._driver = webdriver.Chrome(options=opts)
27
28 @contextmanager
29 def _wait(self, sleep_time=0.2, **kwargs):
30 def _pagehash():
31 dom = self._driver.find_element(
32 By.TAG_NAME, 'html').get_attribute('innerHTML')
33 return hash(dom.encode('utf-8'))
34 yield
35 ph0, ph1 = "empty", ""
36 while ph0 != ph1:
37 ph0 = _pagehash()
38 time.sleep(sleep_time)
39 ph1 = _pagehash()
40
41 def dotrans(self, text, sl="ja", tl="en"):
42 tbase = "https://translate.google.com"
43 url = f"{tbase}/?sl={sl}&tl={tl}&text={urllib.parse.quote(text)}&op=translate"
44 with self._wait(2.0):
45 self._driver.get(url)
46 soup = bs4.BeautifulSoup(self._driver.page_source, "html.parser")
47 for s in soup.find_all(re.compile(r"(head|script|svg|iframe|ul|h\d)")):
48 s.decompose()
49 e = soup.find("body").find("span", {"lang": f"{tl}", "jsname": "jqKxS"})
50 e = e.find("span").find("span")
51 param = re.sub(r"\s+", " ", e.text.strip())
52 return urllib.parse.quote_plus(param)
53
54
55 if __name__ == '__main__':
56 import argparse
57 ap = argparse.ArgumentParser()
58 ap.add_argument("text", nargs="*")
59 ap.add_argument("--st", choices=["ja-en", "en-ja"], default="ja-en")
60 ap.add_argument("--engine", choices=["google", "duckduckgo", "ecosia"], default="duckduckgo")
61 args = ap.parse_args()
62 if args.text:
63 text = " ".join(args.text)
64 else:
65 text = ""
66 while not text:
67 text = input("? ")
68 s = _GT()
69 sl, tl = args.st.split("-")
70 q = s.dotrans(text, sl, tl)
71 page = {
72 "duckduckgo": f"https://duckduckgo.com/?q={q}",
73 "google": f"https://www.google.com/search?q={q}",
74 "ecosia": f"https://www.ecosia.org/search?q={q}",
75 }[args.engine]
76 #
77 ctypes.windll.shell32.ShellExecuteW(
78 0,
79 "open",
80 "chrome",
81 " ".join(["-newtab", '"{}"'.format(page)]),
82 "",
83 1) # 1: SW_SHOWNORMAL
たとえば「postgresql から「The database system is starting up.」と言われている際に、私は何をすべきですか?」という問いに対して、What should I do when PostgreSQL says “The Database System is Starting Up.”という検索に読み替える。
冷静に読めばわかる通り「python → headless chrome → python → ctypes.windll.shell32.ShellExecuteW で chrome」というとても非効率な処理フローだけど、まぁ仕方ないわ。あと、ワタシのように、コマンドラインにいる時間が長い人にはこのスクリプトはそれなりに快適になりえるけれど、そうでない人にはかえって面倒になるんで、ほんとこれがありがたいかは人によりけり。
もっと早く書いておきたかったとも思うのだけれど、スクリプトを見てもらえればわかる通り、selenium のように javascript を処理出来る能力があるものを使わないといけないので、言うほど簡単じゃなかったのでね、面倒に感じてこれまでやってこなかったの。けど最近 selenium のお世話になることが個人的に多かったもんで、まぁ今やっとこうかと思った次第。