「Tabulator らしい」話をしようと書き始めたら、なんか一般論的な話になってしまった。
前回までで作ってきている「声優世代表のおとも」でずっと「使いにくいなぁ」と思ってたことがあったのである。「このレコードは確かに声優か?」のフィルタリングがどうしても使いやすくならんのである。どうしたもんかと思っていた。
「声優世代表のおとも」は、wikipedia ページをスクレイプするのだけれど、(基礎情報収集としてとともに)「声優であるかどうかの判定に使えるかもしれない」というフィールドとしての「職業/職種/ジャンル」という情報を収集するのに、ページ内でこれらを拾う:

そもそも、「wikipedia ページから声優と思われるページを収集するスクレイパ」(お見せしてない)で声優一覧を抽出しているのだが、それが抽出条件にしているのがページの一番下の「カテゴリ:日本の女性声優」というタグと infobox。なのだが、タグ付けの基準はバラバラなので、多くの人が「柳原可奈子が声優??」と違和感を感じる抽出を行ってしまう原因になる。
なので得られた表を読む際に「本業の声優だけみたい」のようなフィルタリングがどうしても欲しい、「端役で一言二言参加をたった一回だけしたことがあるお笑い芸人」には、普段はほとんど興味がないわけだ。
この日笠さんのページは非常に「手厚い」ので豊富な情報を取れるが、当然ページによって情報量に非常にバラつきがある。右側の箱(infobox)がないページ、本業が声優なのになぜか infobox で歌手業の方だけ手厚いページ、お笑い芸人が一回端役で一瞬参加しただけなのに「声優」と記述されているページ、infobox で「声優」をあげているのに、本文要約で「声優である」と言わないページ、なぜかカテゴリでのみ「声優」とマークされているページ、などなど。
「wikipedia による判定」以前の問題として「声優とは何か」の判断は、その役者によっても我々受け手によっても違うというのはいいだろう。たとえば木村拓哉。声優業をガッツリやったことがあるか、という意味では、ハウルの動く城でメインキャストとして演じたので、wikipedia で声優業に言及するのはこれは当然である。この場合に、wikipedia 執筆者が上の絵で挙げた箱の部分に「声優」とマークするかどうか、の話。これがまぁ、本当にバラバラ。
たとえば、元宝塚トップスターで、最近声優を本業にし始めた七海ひろきの記述は、本日時点では、infobox では声優とマークされているのに、本文冒頭の要約には「声優である」と言わない。少なくとも彼女は着実に声優業を増やしているので、たぶん多くの人々は彼女が声優であることに異論はないと思う。ゆえに、七海ひろきが声優と思っている状態で「お笑い芸人を省きたい」としてのフィルタとして(本文冒頭要約は本業以外が省略されるという理由で)「本文冒頭要約に声優が含まれるかどうか」を使いたくても使えない、というのがとても困るわけだ。
これに対する完全な解は、残念ながら、「ない」。どういう検索をしても、完全に満足なフィルタにはならず、七海ひろきを上手に迂回しながらお笑い芸人を省くのは、これは出来ない。
今回したいのは、こうした「出来ないこと」を出来るように頑張る話ではない。そうではなくて、このフィルタリングの自由度に関し、どうしても最初は忘れがちになること、について言及することである。それは「列フィルタの OR」についてだ。
今、ワタシのツールが抽出した情報に基づいて「本業の声優と思われるレコードだけ選びたい」と考える。この際に、全部使うと煩雑なのでとカテゴリタグを除いて、「本文要約」と infobox からの情報の2つに基づいて行うとしても、本当にやりたいのは実は最低でも以下4つのバリエーションなのだ:
- 本文要約に含まれるかどうかだけを選択条件にする
- infobox に含まれるかどうかだけを選択条件にする
- 本文要約と infobox の両方に含まれることを選択条件にする(AND)
- 本文要約と infobox のどちらかに含まれることを選択条件にする(OR)
ちゃんと設計から始めるんでない限り案外最初は気付かず、なおかつ実は一番悩ましい問題なのは、この 3. と 4. を同時に提供するのが簡単でないこと、である。テーブルの2つの列だけ提供している限りは、これは「AND」の提供にしかならない。やってみて初めて気付く、てことが多いんだよね、これ。七海ひろき問題はともかくとして、この OR がないことは、結構ストレスに感じることが多い。もっと正確に言うとビットフラグ表現でいうところの「00, 01, 10, 11」の4つの状態「の OR」が欲しい、ということ。(「本文要約」と infobox のどちらかには「声優」を含まない、という条件を使いたいこともあるということ。)
「「00, 01, 10, 11」の4つの状態を表現する列」そのものを使えば一応完全なんだけれど、表の UI としてはちょっと使いにくいので、折衷案として「条件1と条件2の和」を使うのがいいかなぁと思う:
1 var actor_basinf_data = Array();
2 actor_basinf_data_csv.trim().split("\n").forEach(function (row, i) {
3 let r = jQuery.csv.toArray(row);
4 let bymd = r[2];
5 if (bymd) {
6 bymd = bymd.slice(0, 4) + "-" + bymd.slice(4, 6) + "-" + bymd.slice(6, 8);
7 }
8 let dymd = r[3];
9 if (dymd) {
10 dymd = dymd.slice(0, 4) + "-" + dymd.slice(4, 6) + "-" + dymd.slice(6, 8);
11 }
12 actor_basinf_data.push({
13 "by": r[0], /* 生誕年度 */
14 "as": r[1], /* 活動開始年? */
15 "bymd": bymd, /* 生年月日 */
16 "dymd": dymd, /* 没年月日 */
17 "gen": r[4], /* 性別 */
18 "wp": r[5], /* wikipedia */
19 "redi": r[6], /* リダイレクト先 */
20 "nm": r[7], /* 名前 */
21 "bld": r[8], /* 血液型 */
22 "bor": _B[r[9]], /* 出生地・出身地 */
23 "nn": r[10], /* 愛称 */
24 "tw": r[11], /* 身長/体重 */
25 "bel": r[12], /* 事務所・レーベル */
26 "fst": r[13], /* デビュー作 */
27 "tea": r[14], /* 共同作業者 */
28 "occ": r[15], /* 職業/職種/ジャンル */
29 "occ2": r[16], /* 本文最初のセンテンスの要約に書かれている職種 */
30 "cin": r[17], /* 「出典」の過不足: 0:警告なし, -1:「不足」, -2:「皆無」 */
31
32 "occ_hasva": r[15].includes("声優"),
33 "occ2_hasva": r[16].includes("声優"),
34 "hasva": r[15].includes("声優") + r[16].includes("声優"),
35 })
36 })
ここらあたりまで書いてきて、うん、Tabulator 関係ないよなこの話題、と思ったわけだ。MS Excel とかのワークシートで作業してても頻出でしょ、こういうの。この種のことをしたければ、ワークシート的発想では冗長列を上手に追加することを検討するわけだ。
一応 Tabulator 固有のネタとしては、「boolean 列には「tickCross」がオイシイ」ということと、「こうやって必要になるたびに冗長列を追加してけば、どんどん列が増えていって、表が読みにくくなるのでColumn Groups を使うのがええぞ」、の2つ。(Column Groups はワタシは既にたとえば sparklines の話をしてるこれとかでコッソリ使ってる。tickCross はワタシのサイトで紹介するのは初だが、「Header Filtering」でライブデモに登場してるので、機能としては結構目玉で、少なくともドキュメントを読む人ならあまりこれに気付かない人はいないであろう。)
そういうわけで、Tabulator のセットアップはこんな感じ:
1 var table = new Tabulator("#actor_basinf", {
2 /* ... (snip) ... */
3 "columns": [
4 /* ... (snip) ... */
5 {
6 "field": "nm",
7 "title": "名前",
8 "headerFilter": "input",
9 "headerFilterFunc": "regex",
10 },
11 /* ... (snip) ... */
12 {
13 "title": "声優?",
14 "columns": [
15 {
16 "title": "職業/職種/ジャンル",
17 "columns": [
18 {
19 "field": "occ",
20 "headerFilter": "input",
21 "headerFilterFunc": "regex",
22 },
23 {
24 "field": "occ_hasva",
25 "title": "声優?(1)",
26 "formatter": "tickCross",
27 "headerFilter": "tickCross",
28 "headerFilterParams": {
29 "tristate": true
30 },
31 },
32 ]
33 },
34 {
35 "title": "wikipediaページ本文冒頭での要約に書かれている職業",
36 "columns": [
37 {
38 "field": "occ2",
39 "headerFilter": "input",
40 "headerFilterFunc": "regex",
41 },
42 {
43 "field": "occ2_hasva",
44 "title": "声優?(2)",
45 "formatter": "tickCross",
46 "headerFilter": "tickCross",
47 "headerFilterParams": {
48 "tristate": true
49 },
50 },
51 ]
52 },
53 {
54 "field": "hasva",
55 "title": "(1) + (2)",
56 "headerFilter": "input",
57 "headerFilterFunc": "regex",
58 },
59 ]
60 }
61 ],
62 /* ... (snip) ... */
63 "data": actor_basinf_data
64 });
「条件1と条件2の和」のヘッダフィルタは単に regex としたので、「どちらか一方には声優を含む」なら「[12]」を、「どちらか一方には声優が含まれない」なら「[01]」を指定すればいい。わかりやすいとは言えないかもしれんけれど、まぁワタシがしたいことは概ね出来るかな。
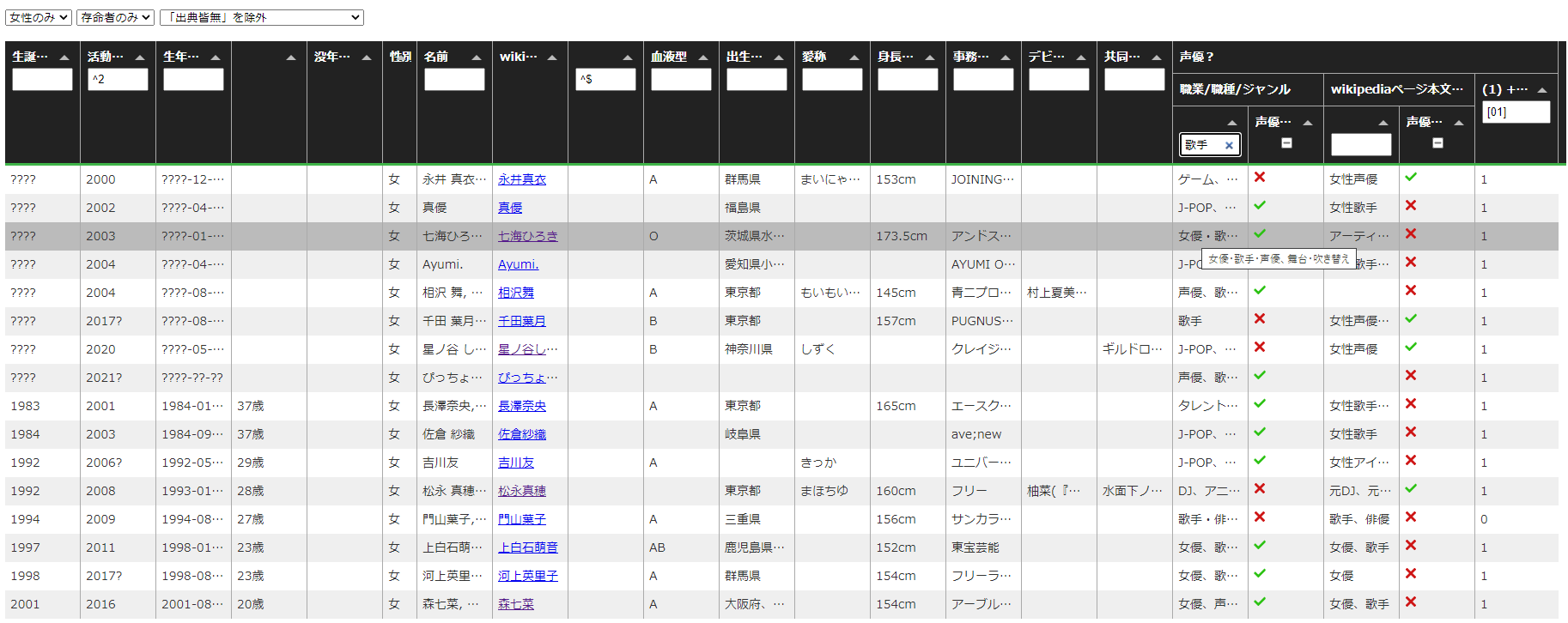
てふわけで「wikipedia をスクレイプして「声優世代表のおとも html」、な、おそらく ver 13」:
例によって入力データ、結果の html 含め全部入ってて、扱ってる人数も膨大になってて、これまで言ってきた「data-uri の形でダウンロードリンクを WordPress 記事に貼り付ける」のが zip では WordPress の制限を超えるほどデカくなったので、昨日ネタでやってみせた tar + bz2 で。展開で困る人、いる? まぁいたとしても「頑張ってくれ」としか言わんけれどね。













