(3)まででも一部やってはいたんだけどね。
さてもさても。ひとつまえで貼り付けた 4139 レコードからさらに増やして 4163 レコードで処理した結果を zip にして WordPress に貼り付けようとすると、(1)で説明した MySQL の列サイズ超過エラーが再び起こる。「MySQL の列サイズの制約がうんぬん」てのはワタシ固有の問題なわけだけれど、誰にとっても共通なのは、「量が増えてくればいずれにしてもシェイプアップはいずれは必要になる」てこと。大きなデータを一気にブラウザに読み込めば、ハングアップすらしかねない、とかね、色々。
むろん「zip でなくもっと圧縮率の高い bzip2 だの 7zip にして貼り付け」しようとすれば、当座の制限からは逃れられるけれど、そうではなくてもっと抜本的にコンパクトにしたい、という際に、当然のごとく俎上に上がるのは「データの正規化」である。(3)まででも実は「性別」でそれをしてたが、それを「もっと」やろうぜ、て話。
なんでこうやって独立したネタとしてわざわざ書こうというのか? それは。
(3)では、「「的」を消してモノホンの csv るぞ」なかった。そう、「csv ファイル」というファイル形式は採用せずに、「javascript 的である」ことをそのまま残した。その決断を活用する話をいっしょにしたいから、である。
まずは先に、性別でやってるのとほぼ同じ普通の正規化、つまり、データベース志向の設計では常識的に考えるタイプの普通の正規化から。「普通の」といっているのは、データベースで言うところの「列」の値そのものが直接他のコードテーブル等のキーとして使えるようなパターン、という意味。性別がまさにそうで、ワタシのでは、csv の性別カラムに「1」が収められていればこれを男性と翻訳し、「2」が収められていれば女性と翻訳している。設計は確かに「普通」だが、「「javascript 的である」ことをそのまま残」していることを活かすことが出来て、例えばこういう data.js を構築する手がある:
1 /* 「出生地/出身地」の集合 */
2 var borns = [
3 "福岡県福岡市(東京育ち)",
4 "千葉県",
5 "関東地方",
6 "愛知県",
7 "青森県",
8 "東京都",
9 "大阪府",
10 ];
11
12 var actor_basinf_data_csv = `
13 0,1987?,????0607,,2,,,"川口 雅代, かわぐち まさよ",,0,,,,,,ジャーナリスト、レポーター、女優、シンガーソングライター、歌手、タレント、DJ、声優,,-2
14 0,1987?,????0726,,1,,,"橋本浩志, はしもと ひろし",,1,,,,,,俳優・声優,男性俳優、声優、司会者,0
15 0,1988,????0502,,2,,,"押谷 芽衣, おしたに めい",,2,,,フリー,,,声優,女性声優,-2
16 0,1988?,????0912,,1,,,"布目 貞雄, ぬのめ さだお",,3,,,,,,,男性声優,0
17 0,1988?,????1126,,2,,,"斉藤 千恵子, さいとう ちえこ",,4,,160cm,オフィスPAC,,,声優,女性声優,-2
18 0,1989,????0304,,1,,,"小林 俊夫, こばやし としお",A,5,,162cm,青二プロダクション,,,声優、ナレーター,男性声優、ナレーター,0
19 0,1989,????0728,,2,,,"中村 尚子, なかむら なおこ",O,6,,160cm,青二プロダクション,,,声優、ナレーター,女性声優、ナレーター,0
20 0,1989?,????1128,,1,,,"真砂 勝美, まさご かつみ",A,5,,,,,,,元男性俳優、声優,-1
21 0,1990,????1105,,2,,,"鈴木 渢, すずき ふう",,3,,,青二プロダクション,,,声優、ナレーター,女性声優、ナレーター,0
22 0,1990?,????0725,,2,,,"永堀 美穂, ながほり みほ",A,5,,,フリー,,,声優,女性声優、ナレーター,0
23 `;
24
25 var actor_basinf_data = Array();
26 actor_basinf_data_csv.trim().split("\n").forEach(function (row, i) {
27 let r = jQuery.csv.toArray(row);
28 let bymd = r[2];
29 if (bymd) {
30 bymd = bymd.slice(0, 4) + "-" + bymd.slice(4, 6) + "-" + bymd.slice(6, 8);
31 }
32 let dymd = r[3];
33 if (dymd) {
34 dymd = dymd.slice(0, 4) + "-" + dymd.slice(4, 6) + "-" + dymd.slice(6, 8);
35 }
36 actor_basinf_data.push({
37 "by": r[0], /* 生誕年度 */
38 "as": r[1], /* 活動開始年? */
39 "bymd": bymd, /* 生年月日 */
40 "dymd": dymd, /* 没年月日 */
41 "gen": r[4], /* 性別 */
42 "wp": r[5], /* wikipedia */
43 "redi": r[6], /* リダイレクト先 */
44 "nm": r[7], /* 名前 */
45 "bld": r[8], /* 血液型 */
46 "bor": borns[r[9]], /* 出生地・出身地 */
47 "nn": r[10], /* 愛称 */
48 "tw": r[11], /* 身長/体重 */
49 "bel": r[12], /* 事務所・レーベル */
50 "fst": r[13], /* デビュー作 */
51 "tea": r[14], /* 共同作業者 */
52 "occ": r[15], /* 職業/職種/ジャンル */
53 "occ2": r[16], /* 本文最初のセンテンスの要約に書かれている職種 */
54 "cin": r[17], /* 「出典」の過不足: 0:警告なし, -1:「不足」, -2:「皆無」 */
55 })
56 })
性別は Tabulator の Formatter 機能での読み替えをしてたが、今の例は「csv 形式のテキスト」を Tabulator が読み込むための javascript Object に翻訳する処理内での変換をする例。
今やったように「配列とインデクス」を使うのか、あるいは辞書を使うのかはまぁ本質ではなくて、今考えたいのは「列の値そのものをキーとする」ことの是非である。
たとえば ISO で定めている都道府県コードからの変換を行うのと違って、今の場合は「wikipedia のページ執筆者に委ねられているフリーダム書式に基づく様々な出生地・出身地表現」をコード化する話。「福岡県福岡市(東京育ち)」なんて出身地はおそらく一人とか二人みたいなごく少数でしか使われない、「正規化した甲斐がない」もの。こうしたことを許容できるかどうか、である。これについては、「wikipedia で人物についての情報を列挙する」範囲内であれば、「都道府県だけ書くケースがとても多い」などの条件がわりと整うので、まぁそんなに無価値とまでは言えない、と思う。
ここまではまぁ普通だ。「csv ファイルそのものを使う」のと違って確かに「スクリプト」そのものを同梱出来る、というのはあるけれど、発想そのものは、普通のデータベースアプリケーションで普通に考えるのとなんにも違わない。
一方、データベースアプリケーションではその設計を採ることはあまり多くない、「変数置換」のような仕組みを考えるケース。テーブルの列にたとえば「${tbl_owner[this[“登録記号”]]}」と記述すると、所有者テーブルから当該レコードの登録記号列をキーに所収者を出力する、みたいなこと。こうしたことには「DBMS そのもの」のなんらかサポートが普通は期待できないのであまり採用されないわけだが、「DBMS 以外のインフラを大活躍させる」(たとえばなんらかのテンプレートエンジン)ことをするなど、やろうと思えば出来ることなので、やりたいときはやる、そんなアプローチである。
このパターンが、そう、ワタシは今「Template Literals を使っている」のである。そう、変数置換の仕組みを既に使える状態になってる。とするならばたとえば:
1 /* この名前が長すぎると余計肥大するので短い名前に */
2 var _P = [
3 "EARLY WING",
4 "EARLY WING SUZAKU",
5 "5pb.Records",
6 "MAGES.",
7 "Beyond the Music",
8 "青二プロダクション",
9 "flying DOG",
10 "TOKYO LOGIC MUSIC"
11 "東京俳優生活協同組合",
12 ];
13
14 var actors_csv = `
15 0,2000,????1109,,2,,,"笠原 あきら, かさはら あきら",O,東京都,,156cm,${_P[0]}、自主制作,,V.S UNION、☆Twinkle☆Girls☆,声優、歌手、作曲家、アニメ、ゲーム、歌手、作詞家、作曲家,女性声優、歌手、作曲家,0
16 0,2009?,????0729,,2,,,"笹本 菜津枝, ささもと なつえ",O,埼玉県,,,${_P[0]},,,声優、アニメ・ゲーム,女性声優,0
17 1977,1997,19770727,,2,,,"水野 愛日, みずの まなび",A,群馬県,まなびぃ(表記はマナビィ、まなびぃ、まなびーなど色々ある),152cm,${_P[0]}、${_P[1]}(2011年 -),菅野(『新・天地無用!』),今までに焼肉娘、ばななちっぷす、とりおまてぃっく、らいむ隊Army、Plume(2006年 - 2009年)、plume petite,声優、歌手、アニメ、ゲーム、ラジオ、J-POP、アニメソング、ゲームソング、歌手,女性声優、歌手,0
18 1977,1999,19770516,,2,,,"今井 麻美, いまい あさみ",O,東京都渋谷区、山口県徳山市(現・周南市),ミンゴス,158cm,${_P[0]}、${_P[2]}、${_P[3]}、${_P[4]},伝説の少女(ドラマCD『刻の大地〜花の王国の魔女〜』)、舞台『剣ヶ崎』石見志津子,SPガールズ、らいむ隊Army、A.I.E.N、DG-10、ARTERY VEIN,声優、歌手、舞台女優、アニメ、ゲーム、ラジオ、ナレーション、舞台、J-POP、ゲームソング、アニメソング、キャラクターソング、歌手,声優、歌手、舞台女優,0
19 1977,2000年代,19770509,,1,,,"山本 兼平, やまもと かねひら",O,東京都,,174cm,${_P[0]},,,声優、舞台俳優,声優、舞台俳優,0
20 1987,2010年代,19871228,,1,,,"喜多田 悠, きただ ゆう",B,兵庫県,,173cm,${_P[0]}(準所属),,,声優,男性声優,0
21 0,1960年代,????????,,2,,,"小串 容子, おぐし ようこ",,,,,${_P[8]}→${_P[5]}(最終),,,声優、女優,元声優、女優,0
22 1987,2007,19880210,,2,,,"山村 響, やまむら ひびく",O,福岡県,ひびび、ひびくん,160cm,${_P[8]}、${_P[6]}、${_P[7]},,Trident,声優、歌手、アニメ、ゲーム、吹き替え、歌手,女性声優、歌手,0
23 `
24
25 console.log(actors_csv);
という感じ。うまくやれば、actor_basinf_data.js のファイルサイズはこれによっても結構減らせる、かな? コメントに書いた通り「変数名の長さ」が影響してしまうのが一番の問題で、そこは考え方次第。(あと javascript の名前空間を汚す問題についても、これもうまくやる必要はある。)
ワタシのケースでは、いまのところ上にあげたとおりの対象に対し上にあげた通りのアプローチで正規化するのが効くような気がしたので、それでいくことにしてみた。つまり、あげた両方のアプローチを採用する。
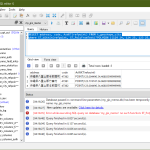
そもそもコードテーブルを生成する部分は、前者はともかく、後者はそれなりに面倒なタスクではあるが、まぁ使ってるのが Python だからさ、まぁなんとかなるべと。どれだけシェイプアップ出来るかはやってみないとわからん、てところで、なので実際やってみたのが「wikipedia をスクレイプして「声優世代表のおとも html」、な、ver 12 らしきもの」:
(3)での件数よりもさらに増やして 4315 レコード、ご覧の通り WordPress 制限にひっかからないサイズには出来た、つまり「結構圧縮できた」。ただ。…覚悟はしてたけど、やっぱり「前者」のほう(出生地・出身地)があまり効果的とは言えない。案外市町村まで書いてるんだなぁ…。まぁとりあえず今回はワタシの場合は「やってみた、ワタシのケースの場合は、事務所・レーベルの正規化は上々、ケド出生地・出身地のほうはもう一声必要」となった、てことで。あとは裏でこっそり考えとくわ。(出生地・出身地のほうも後者のアプローチのほうがいい可能性はある、とか、まだ色々出来ることはあると思う。)
ちなみに一応いっておくと、ワタシが今やってる圧縮は、ワタシのように WordPress に zip で圧縮して貼り付けるのではなくて「WEB に公開するページ」が目的の場合は、「HTTP GET での転送サイズを減らす」という部分に相当する。最終的にブラウザ内に展開されるメモリ削減とは関係ないし、ページロード時間の削減には、つながるかもしれないしつながらないかもしれない。でもたとえ目的が「WEB に公開するページ」であろうと、正規化の発想と今回やってみた Template Literals の活用は、きっと役に立つ、ハズ。