「ハイレベル API」が、もともと取れるはずの情報を落としていってしまうのは、まぁよくあることだけれども。
やりたいことはこの絵でわかるよね:
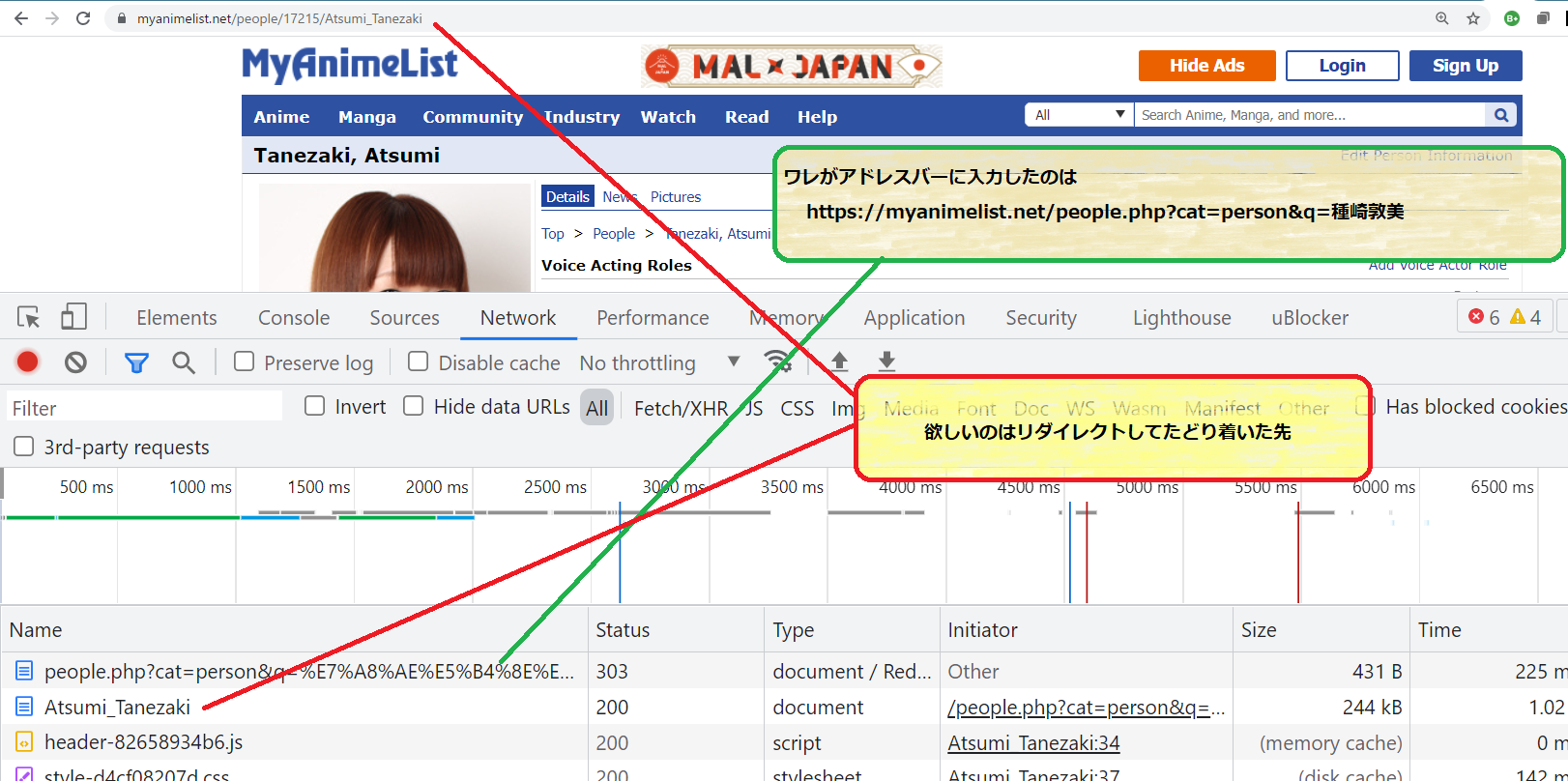
ターゲットとしている MyAnimelist のこの例そのものに対するワタシのニーズは「検索した結果が一意に求まったならば、検索の url ではなく結果の url をデータベースに記録しておきたい」ということ。記録したそれをたとえば「声優関連図」なんぞの元ネタにしたい、てわけだね。オレ的、でない一般的なニーズでいえばたとえば「移動しました。ブックマークを変更してください。」という行為に相当するので、まぁわかるよね。
下層、つまり HTTP プロトコルのシーケンスとしては、「オレ」のリクエスト「GET /people.php?cat=person&q=種崎敦美」に対してサーバが 303 でいったん返してきて、そこには転送先がレスポンスに含まれていて、なのでクライアントは改めてそこに書き込まれている url である「Atsumi_Tanezaki」を GET して、めでたくレンダリング対象となるページを得る、て流れ。
Python でも「ローレベル API」を使って、ブラウザがやってるまさにその通りの「303を返してきたのでリダイレクト先を取りに行く」という流れを「そのままプログラミングすることが出来る」。ので今ワタシが欲しいと思っている「リクエストしたページの url ではなくリダイレクト先ページの url が欲しい」というのはこの一連の流れで必然的に知ることになる。
一方で、Python には「urllib.request.urlretrieve」なんてステキなハイレベル API が提供されていて、こちらは「303なのでお取り寄せ直さねばならぬ」の部分をやってくれる上に、ページ内容つまり「Content」をファイルに書き出してくれる。これがまぁ標準添付ライブラリの範囲内ではかなり便利なものなので、ワタシはとにかくよく使うんだけれども。
今回これが欲しいと思って初めて気付いたんだけど、「リダイレクト先 url」情報を捨てている犯人は urlretrieve そのもので、実はその一つだけ下層の「URLopener#open (などの opener)」は「303 なのでリダイレクト先を取りに行く」ということをやってくれた上で、リダイレクト先の url も返してくれるんだよねこれが…。問題の部分はこれ:
220 _url_tempfiles = []
221 def urlretrieve(url, filename=None, reporthook=None, data=None):
222 """
223 Retrieve a URL into a temporary location on disk.
224
225 Requires a URL argument. If a filename is passed, it is used as
226 the temporary file location. The reporthook argument should be
227 a callable that accepts a block number, a read size, and the
228 total file size of the URL target. The data argument should be
229 valid URL encoded data.
230
231 If a filename is passed and the URL points to a local resource,
232 the result is a copy from local file to new file.
233
234 Returns a tuple containing the path to the newly created
235 data file as well as the resulting HTTPMessage object.
236 """
237 url_type, path = _splittype(url)
238
239 with contextlib.closing(urlopen(url, data)) as fp:
240 headers = fp.info()
241
242 # Just return the local path and the "headers" for file://
243 # URLs. No sense in performing a copy unless requested.
244 if url_type == "file" and not filename:
245 return os.path.normpath(path), headers
246
247 # Handle temporary file setup.
248 if filename:
249 tfp = open(filename, 'wb')
250 else:
251 tfp = tempfile.NamedTemporaryFile(delete=False)
252 filename = tfp.name
253 _url_tempfiles.append(filename)
254
255 with tfp:
256 result = filename, headers
257 bs = 1024*8
258 size = -1
259 read = 0
260 blocknum = 0
261 if "content-length" in headers:
262 size = int(headers["Content-Length"])
263
264 if reporthook:
265 reporthook(blocknum, bs, size)
266
267 while True:
268 block = fp.read(bs)
269 if not block:
270 break
271 read += len(block)
272 tfp.write(block)
273 blocknum += 1
274 if reporthook:
275 reporthook(blocknum, bs, size)
276
277 if size >= 0 and read < size:
278 raise ContentTooShortError(
279 "retrieval incomplete: got only %i out of %i bytes"
280 % (read, size), result)
281
282 return result
「URLopener#open などの opener」と言っているのが「urlopen(url, data)」ね、ここでは「fp」。そこから「.info()」をとってそれを返してくれる、てことをしている、のだけれども。
をーい…。「.info()」が余計なんだよなぁ。つまりこれは違う:
1 base = "https://myanimelist.net/people.php?cat=person&q="
2 fn, resp = urlretrieve(base + quote("種崎敦美"))
3 print(resp)
1 Content-Type: text/html; charset=utf-8
2 Transfer-Encoding: chunked
3 Connection: close
4 Date: Sun, 07 Nov 2021 11:33:11 GMT
5 Server: Apache
6 Set-Cookie: MALSESSIONID=cfft4sv7kdmoqb99r80a82uaj0; expires=Wed, 05-Nov-2031 11:33:11 GMT; Max-Age=315360000; path=/; secure; HttpOnly
7 Set-Cookie: MALHLOGSESSID=7cfb42533a2eb6b5a9e8c5917b7d01c0; expires=Fri, 06-Nov-2026 11:33:11 GMT; Max-Age=157680000; path=/
8 Cache-Control: no-cache
9 Vary: User-Agent
10 Referrer-Policy: same-origin
11 X-XSS-Protection: 1; mode=block
12 X-Content-Type-Options: nosniff
13 X-Frame-Options: SAMEORIGIN
14 Strict-Transport-Security: max-age=63072000; includeSubDomains; preload
15 X-Cache: Miss from cloudfront
16 Via: 1.1 82060a14395d18b7dfd087d8b759d083.cloudfront.net (CloudFront)
17 X-Amz-Cf-Pop: KIX50-P1
18 X-Amz-Cf-Id: AIpyh9STUOnlL65y8s18ximwD4TKnqnTcuTfH6uDmXtxO3C3dpvxjA==
openner#open は実は「info (headers)、status (code)、url」を返してくれている。ソレ、ソレ。欲しいのはこの url。つまりは以下のようにすることで「リダイレクト先 url が取れる」:
1 # -*- coding: utf-8 -*-
2 # require: python 3
3 import io
4 import re
5 import json
6 import ssl
7 import os
8 import time
9 import urllib.request
10 from urllib.error import HTTPError
11 from urllib.request import quote as urllib_quote
12
13
14 __USER_AGENT__ = "\
15 Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
16 AppleWebKit/537.36 (KHTML, like Gecko) \
17 Chrome/91.0.4472.124 Safari/537.36"
18 _htctxssl = ssl.create_default_context()
19 _htctxssl.check_hostname = False
20 _htctxssl.verify_mode = ssl.CERT_NONE
21 https_handler = urllib.request.HTTPSHandler(context=_htctxssl)
22 opener = urllib.request.build_opener(https_handler)
23 opener.addheaders = [('User-Agent', __USER_AGENT__)]
24 urllib.request.install_opener(opener)
25
26
27 if __name__ == '__main__':
28 def _str(s):
29 # すまん、これは Windows のコンソール向けの措置なので本質じゃないぞ
30 return s.encode("cp932", errors="xmlcharrefreplace").decode("cp932")
31 actors = []
32 # ... 省略。
33 # ... actors をどこかから取ってくる。中身は ["中田 譲治", "緒方 恵美", ...]) ...
34
35 result = {}
36 # 結果を malpages.json に書き出す。
37 if os.path.exists("malpages.json"):
38 result = json.load(io.open("malpages.json", encoding="utf-8"))
39 baseq = "https://myanimelist.net/people.php?cat=person&q="
40 for i, pn in enumerate(actors):
41 if pn in result:
42 continue
43 q = baseq + urllib_quote(pn, encoding="utf-8")
44 try:
45 resp = urllib.request.urlopen(q)
46 except HTTPError as e:
47 print(_str(pn), e)
48 if "404" in str(e):
49 result[pn] = None
50 time.sleep(5)
51 else:
52 # Forbidden とかはサーバの DOS 対応としての反応のこともあるので、
53 # ここで余計に待つだけでなく「後日リトライ」みたいなことが必要。
54 time.sleep(30)
55 else:
56 # そう、欲しいのはこの「resp.url」
57 print(_str(pn), resp.url)
58 result[pn] = resp.url
59 # 大人数を処理したいので、その際に Ctrl-C とかで止めると最初から
60 # やり直しになるのを避けるために「都度都度書き出す」。
61 json.dump(
62 result,
63 io.open("malpages_.json", "w", encoding="utf-8"),
64 indent=4, ensure_ascii=False, sort_keys=True)
65 if os.path.exists("malpages.json"):
66 os.remove("malpages.json")
67 os.rename("malpages_.json", "malpages.json")
(ちなみにユーザエージェント詐称、cert エラーの無視、の部分はまぁ必要ではあり、今は本題ではないけれど、一応省略せずに入れといた。)
これにより、「今日のワレのニーズ」である「リダイレクト先を知る」には耐えている:
1 {
2 "つぶやきシロー": null,
3 "てらそま まさき": "https://myanimelist.net/people/563/Masaki_Terasoma",
4 "中村 悠一": "https://myanimelist.net/people.php?cat=person&q=%E4%B8%AD%E6%9D%91%20%E6%82%A0%E4%B8%80"
5 }
けれどもこのコードだけでは「Content の書き出し」は出来てない。「Content の書き出し」もしつつリダイレクト先も欲しい、のだよ。これは urlretrieve を書き直すしかないよなぁ…、あるいはリダイレクトハンドラを置き換えるんでもいいのかな? 気が向いたらやってみる、かも。今日はいいや。今はリダイレクト先がわかればいいだけだから。