ここで見せる動画をみて誤解されちゃいそうで怖いんだけれど。
以下再生前にちょっとボリュームを下げといて、ちとボリューム大きいので:
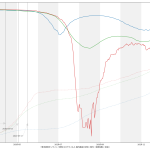
まぁなんだか「凄そう」に見える人もいるかもしれんけれど、そうじゃないので注意。つまり「リアルタイムでやってない」。
リアルタイムでこの手のことをしたい人は、ワタシのものよりかは この人がやってること とかから真似してった方が近いんじゃないかな、多分。自分でやってないからわからんけど。
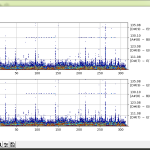
俺的興味は単に「自分がやってることが正しいかどうか」の検証だけ。つまり「ちゃんと FFT してそこから音階拾えてますかいね」てこと。だけど(3)のような「動かない」解析だと確証持ちずらいでしょ、だから「擬似的でもリアルタイム「的」」なことをして、実際に鳴ってる音との対応で見たいわけよね。
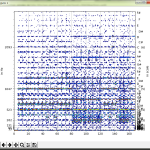
あ、(3) でちょっと触れた「本当は contour を使いたくない」の理由がわかる事象が出てるよね? 縦の青線が引かれちゃうようにみえてるのはこれは無論 contour を使っているからで。
さて。どうやってこの動画を作ったかは単純で、
- (3)を連続静止画を吐くように書き換え
- 出来た静止画を ffmpeg で mp4 動画に
- 1. の入力音声と 2. の結果動画を ffmpeg で結合して mp4 動画に
これだけ。1. はこれ:
1 import numpy as np
2 import matplotlib.pyplot as plt
3 import matplotlib.ticker as ticker
4 from tiny_wave_wrapper import WaveReader, WaveWriter
5
6 #
7 _SCALES_L = ["C", "C#", "D", "D#", "E", "F", "F#", "G", "G#", "A", "A#", "B"]
8
9 def _nn2scale(d):
10 return int(d / 12) - 2, _SCALES_L[int(d) % 12]
11
12 def _nn2freq(d):
13 return np.power(2, (d - 69) / 12.) * 440
14
15 def _freq2nn(f):
16 return 69 + 12 * np.log2(f / 440.)
17
18 class _nnformat(object):
19 def __init__(self, minor):
20 if minor:
21 self._fmt = lambda oc, sc: " " * (_SCALES_L.index(sc) % 2) + sc
22 else:
23 self._fmt = lambda oc, sc: "%s (%d)" % (sc, oc)
24
25 def __call__(self, f, pos):
26 if f > 0:
27 nn = int(_freq2nn(f))
28 oc, sc = _nn2scale(nn)
29 return self._fmt(oc, sc)
30 return ""
31
32 def _setup_locator(ax):
33 _all = np.arange(24, 144)
34 _maj = np.array([v for v in _all if v % 12 == 0])
35 _min = np.array([v for v in _all if v % 12 in (2, 4, 5, 7, 9, 11)])
36 ax.yaxis.set_major_locator(ticker.FixedLocator(_nn2freq(_maj)))
37 ax.yaxis.set_minor_locator(ticker.FixedLocator(_nn2freq(_min)))
38
39 def _saveasgraph(F, fnum, args):
40 freq = np.fft.fftfreq(F[0].shape[1], 1./rate)
41 X = np.arange(F[0].shape[0])
42
43 fig, ax_ = plt.subplots()
44 for chn in range(2):
45 ax = plt.subplot(1, 2, chn + 1)
46
47 Y = freq[:len(freq) // 2]
48 Z = F[chn].T[:len(freq) // 2,:]
49 if args.upper_limit_of_view:
50 ind = (Y <= args.upper_limit_of_view)
51 Y, Z = Y[ind], Z[ind, :]
52 if args.lower_limit_of_view:
53 ind = (Y >= args.lower_limit_of_view)
54 Y, Z = Y[ind], Z[ind, :]
55
56 ax.contour(X, Y, Z, cmap='jet')
57 ax.yaxis.set_major_formatter(ticker.FuncFormatter(_nnformat(False)))
58 ax.yaxis.set_minor_formatter(ticker.FuncFormatter(_nnformat(True)))
59 ax.set_xticks([])
60 _setup_locator(ax)
61 ax.grid(True)
62
63 fig.tight_layout()
64 fig.savefig("out_%05d.jpg" % (fnum))
65 plt.close(fig)
66
67
68 if __name__ == '__main__':
69 import argparse
70 parser = argparse.ArgumentParser()
71 parser.add_argument("-s", "--step", type=int)
72 parser.add_argument("-u", "--upper_limit_of_view", help="Hz", type=int)
73 parser.add_argument("-l", "--lower_limit_of_view", help="Hz", type=int)
74 parser.add_argument("target")
75 args = parser.parse_args()
76
77 with WaveReader(args.target) as fi:
78 nchannels, width, rate, nframes, _, _ = fi.getparams()
79 raw = np.fromstring(fi.readframes(nframes), dtype=np.int16)
80 channels = raw[::2], raw[1::2]
81
82 if args.step:
83 step = args.step
84 else:
85 step = rate // 8
86 nframes = len(channels[0])
87 nframes -= (nframes % step) # drop the fraction frames
88 tmp = np.fft.fft(channels[0][:step]) # FIXME: to be more smart.
89 F = np.array([
90 np.zeros((rate // step * 10, len(tmp))),
91 np.zeros((rate // step * 10, len(tmp)))
92 ])
93 p = 0
94 for i in range(0, nframes, step):
95 for chn in range(len(channels)):
96 channel = channels[chn]
97 f = np.abs(np.fft.fft(channel[i:i + step]))
98 f = f / f.max()
99 F[chn][p] = f
100 _saveasgraph(F, i // step, args)
101 p += 1
102 if p >= F[0].shape[0]:
103 p = 0
104 F[:,:,:] = 0
(3)より少し単純化した部分もあるけど、基本的には「時間の進行の都度静止画に」という構造に変えている。
で、今の場合「step = rate // 8」、つまりフレームレート 8 の動画相当の静止画が出来る。のでこんなで動画に:
1 me@host: ~$ ffmpeg -framerate 8 -i out_%05d.jpg -c:v libx264 out.mp4
入力の音声 test_CEG_with_adsr.wav と out.mp4 を結合:
1 me@host: ~$ ffmpeg -i out.mp4 -i test_CEG_with_adsr.wav omix.mp4
ちぅわけで、「だからどーした」って言われると困っちゃうんだけれど、よーするに「オレ的に何度かは必要になりそうだけど、都度編み出すのはさすがにそこそこ大変なのでメモメモ」ってだけのハナシ。(matplotlib もしばらく離れるとすぐに思い出せなくなるし、ffmpeg は複雑だし。)