生まれて始めて、というのは極端なんだけれども。
「生まれて始めて正規表現を学んだ頃」というのは学生の頃であるから、20年近く前のこと。当然「貪欲マッチ・非貪欲マッチ」の話なんかは基礎的な話として出てくる。そしてそれだけではなくて日常的に「やり過ぎ!」との格闘はするにはする。
なんでだろうかと思ったんだけど、ワタシがあんまし正規表現だけに頼らずにロジックで済ませる傾向が強いからなんだろう、これまで正規表現そのものでこれを制御しようと思って来なかった。
今ここいらのことを、こっそりやってる。苦しみながらも楽しみつつ。
「スキャナー生成用コードジェネレータのソースのスキャナー」は、頭痛くなってくる。日本語も意味わからんでしょ。「正規表現の解析が必要かもよ」と言えば通じる?
タイトルの「non-greedy」は7.2.1. 正規表現のシンタクスに書かれてる「*?, +?, ??」ね。lex のこんな仕様:
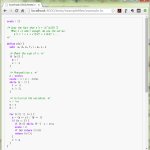
1 %{
2 /* c/c++ へのトランスレート後ソースにそのまま複写したいコードを書く */
3 // ...
4 %}
5
6 /* ここは c/c++ ではなく「c/c++の元」 */
7 pattern1 { action }
8 pattern2 { action }
9 ...
10
11 %{
12 /* c/c++ へのトランスレート後ソースにそのまま複写したいコードを書く */
13 // ...
14 %}
この「%{~%}」の中を Pygments に元からいる CLexer、CppLexer に解析させてやれ、と。このときにね、こんな正規表現書いたらダメなの:
オレオレ lexer 内 (誤)
1 tokens = {
2 'root': [
3 inherit,
4 (r'^%\{\s*', Generic.Heading, 'literal-block'),
5
6 (r'^[a-zA-Z0-9_]+\s+', ptndef_cb),
7 (r'^%[^\s{}]+', Generic.Subheading),
8
9 (r'.', Text)
10 ],
11 'literal-block': [
12 (r'(.+)(\n%\}\s*)',
13 bygroups(using(CppLexer), Generic.Heading),
14 '#pop'),
15 ],
16 }
オレオレ lexer 内 (正)
1 tokens = {
2 'root': [
3 inherit,
4 (r'^%\{\s*', Generic.Heading, 'literal-block'),
5
6 (r'^[a-zA-Z0-9_]+\s+', ptndef_cb),
7 (r'^%[^\s{}]+', Generic.Subheading),
8
9 (r'.', Text)
10 ],
11 'literal-block': [
12 (r'(.+?)(\n%\}\s*)',
13 bygroups(using(CppLexer), Generic.Heading),
14 '#pop'),
15 ],
16 }
なんだか超初心者ぶり発揮しとるの。
html とか xml の「不真面目な解析」するのに便利よ、これ。(真面目なパーサを使って苦しまずにインチキパースを正規表現でやっちゃいたいとき。)