こんなことしたいこと、多くないです?

どぞ。
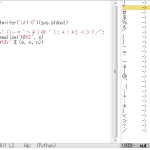
1 # -*- coding: utf-8 -*-
2 import re
3
4
5 #
6 #
7 #
8 def _split_into_words(s):
9 result = []
10 spl = re.split(r"[ _]", s)
11 for w in spl:
12 inner = \
13 re.sub(
14 r"([A-Z]+)([A-Z])([a-z0-9]+)",
15 r"\1,\2\3",
16 re.sub(r"([a-z0-9])([A-Z])", r"\1,\2", w)
17 ).split(",")
18 for i, ins in enumerate(inner):
19 if not re.match(r"^[A-Z]+$", ins):
20 inner[i] = ins.lower()
21 result.extend(inner)
22 return result
23
24
25 #
26 #
27 #
28 class BaseNameMangler(object):
29 def __init__(self, s):
30 self._splitted = _split_into_words(s)
31
32 def convert(self, dest_type="capWords"):
33 """
34 >>> c = BaseNameMangler("simpleHTTPServer")
35 >>> c.convert("CapWords")
36 'SimpleHTTPServer'
37 >>> c.convert("capWords")
38 'simpleHTTPServer'
39 >>> c.convert("lower_underscore")
40 'simple_HTTP_server'
41 >>> c.convert("upper_underscore")
42 'SIMPLE_HTTP_SERVER'
43 >>> c.convert("CapWords_force")
44 'SimpleHttpServer'
45 >>> c.convert("capWords_force")
46 'simpleHttpServer'
47 >>> c.convert("lower_underscore_force")
48 'simple_http_server'
49 >>> c = BaseNameMangler("simple_HTTP_Server")
50 >>> c.convert("CapWords")
51 'SimpleHTTPServer'
52 >>> c.convert("capWords")
53 'simpleHTTPServer'
54 >>> c.convert("lower_underscore")
55 'simple_HTTP_server'
56 >>> c.convert("upper_underscore")
57 'SIMPLE_HTTP_SERVER'
58 >>> c.convert("CapWords_force")
59 'SimpleHttpServer'
60 >>> c.convert("capWords_force")
61 'simpleHttpServer'
62 >>> c.convert("lower_underscore_force")
63 'simple_http_server'
64 >>> c = BaseNameMangler("HTTP_Server")
65 >>> c.convert("CapWords")
66 'HTTPServer'
67 >>> c.convert("capWords")
68 'HTTPServer'
69 >>> c.convert("lower_underscore")
70 'HTTP_server'
71 >>> c.convert("upper_underscore")
72 'HTTP_SERVER'
73 >>> c.convert("CapWords_force")
74 'HttpServer'
75 >>> c.convert("capWords_force")
76 'httpServer'
77 >>> c.convert("lower_underscore_force")
78 'http_server'
79 """
80 if dest_type == "CapWords":
81 return "".join([
82 s.title() if s[0].islower() else s
83 for s in self._splitted])
84 elif dest_type == "capWords":
85 return "".join([
86 s.title() if i > 0 and s[0].islower() else s
87 for i, s in enumerate(self._splitted)])
88 elif dest_type == "lower_underscore":
89 return "_".join(self._splitted)
90 elif dest_type == "upper_underscore":
91 return "_".join([
92 s.upper()
93 for s in self._splitted])
94 elif dest_type == "CapWords_force":
95 return "".join([
96 s.title()
97 for s in self._splitted])
98 elif dest_type == "capWords_force":
99 return "".join([
100 s.title() if i > 0 else s.lower()
101 for i, s in enumerate(self._splitted)])
102 elif dest_type == "lower_underscore_force":
103 return "_".join([
104 s.lower()
105 for s in self._splitted])
106
107
108 if __name__ == "__main__":
109 import doctest
110 import sys
111 doctest.testmod(sys.modules[__name__], verbose=False)
あんましスマートではないとは思うんだけどね。とにかくアタシは、何度もこやつを書いた。なんでか「設計書からコード自動生成」的なことをやたらやるもんで。和英混在文書の表記ゆれ統一のために unicodedata.normalizeとセットな、大抵。
2015-03-02 15:16
この時刻以前に運悪く見てしまったお方へ。
「”capWords_force”」が間違えてました。
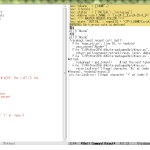
before:
1 elif dest_type == "capWords_force":
2 return "".join([
3 s.title() if i > 0 else s
4 for i, s in enumerate(self._splitted)])
after:
1 elif dest_type == "capWords_force":
2 return "".join([
3 s.title() if i > 0 else s.lower()
4 for i, s in enumerate(self._splitted)])
2021-06-11追記:
お互いにお互いの存在は知らなかったのだとは思うけれど、日本人の方がかなり同時期(一応ワタシがここに書いた方が少し早かったみたいだけれど)に、まったく同じ目的のものを作って pypi に登録し、そして今では結構使われてるみたい。全然関係ないものを pip インストールしたら依存物としてこれがインストールされた。









![[kivy] Is there a way to collapse all the tabs in an Accordion?](http://hhsprings.pinoko.jp/site-hhs/wp-content/uploads/2016/08/img_57a3ea3273a4d-150x150.png)
