Contents
和英混在の文章を PowerShell に喋らせる
ヤスタカの続き。
ハルカさんだけじゃなく
貧乏性と収集癖を駆使して:
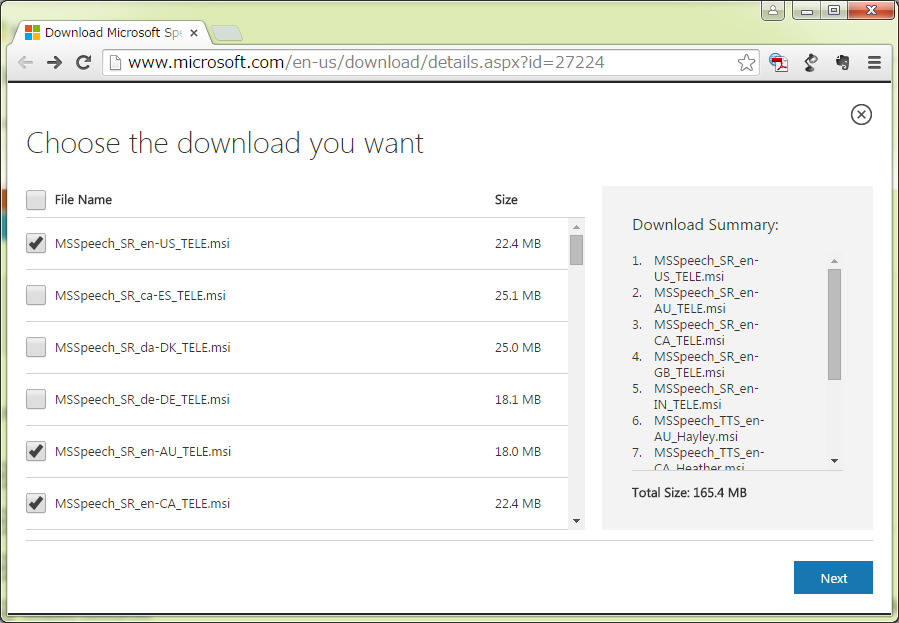
165.4MB。んなことしてなんになる。
SRとTTSの違いはなんだろう? ハルカさんは TTS だったので、TTS だけでいいのかも。なお、わかると思いますが一応:
1. en-US -> American English (US: United States)
2. en-AU -> Australian English
3. en-CA -> Canadian English
4. en-GB -> British English (GB: Great Britain)
5. en-IN -> Indian English
ハルカさんだけじゃなくなったので
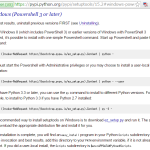
音声の選択をするわけね。その前に、プログラムから列挙してみねばならん:
1 PS C:\Users\hhsprings> [Reflection.Assembly]::LoadWithPartialName("Microsoft.Speech")
2
3 GAC Version Location
4 --- ------- --------
5 True v2.0.50727 C:\Windows\assembly\GAC_MSIL\Microsoft.Speech\11.0.0.0__31bf3856ad364e35\Microsoft.Speech.dll
6
7
8 PS C:\Users\hhsprings> $speak = New-Object Microsoft.Speech.Synthesis.SpeechSynthesizer
9 PS C:\Users\hhsprings> foreach ($vi in $speak.GetInstalledVoices()) { [Console]::WriteLine($vi.VoiceInfo.Name) }
10 Microsoft Server Speech Text to Speech Voice (en-AU, Hayley)
11 Microsoft Server Speech Text to Speech Voice (en-CA, Heather)
12 Microsoft Server Speech Text to Speech Voice (en-GB, Hazel)
13 Microsoft Server Speech Text to Speech Voice (en-IN, Heera)
14 Microsoft Server Speech Text to Speech Voice (en-US, Helen)
15 Microsoft Server Speech Text to Speech Voice (en-US, ZiraPro)
16 Microsoft Server Speech Text to Speech Voice (ja-JP, Haruka)
17 PS C:\Users\hhsprings>
音声の切り替えは SelectVoice:
1 PS C:\Users\hhsprings> $speak.SelectVoice('Microsoft Server Speech Text to Speech Voice (en-US, ZiraPro)')
2 PS C:\Users\hhsprings> $speak.Voice
3
4
5 Gender : Female
6 Age : Adult
7 Name : Microsoft Server Speech Text to Speech Voice (en-US, ZiraPro)
8 Culture : en-US
9 Id : TTS_MS_en-US_ZiraPro_11.0
10 Description : Microsoft Server Speech Text to Speech Voice (en-US, ZiraPro)
11 SupportedAudioFormats : {Microsoft.Speech.AudioFormat.SpeechAudioFormatInfo}
12 AdditionalInfo : {[, ], [Age, Adult], [AudioFormats, 18], [Gender, Female]...}
13
14
15
16 PS C:\Users\hhsprings>
なお、このまま対話的に「確認」したいなら、
1 $speak.SetOutputToDefaultAudioDevice()
として、スピーカーに向けておく。の上で
1 $speak.Speak("Hello")
で、ZiraProお嬢が喋ってくれる。
英語部分と日本語部分の分離
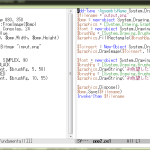
PowerShell はまだ不慣れなので、これは Python でやってしまう。こんな感じかな:
1 # -*- coding: utf-8 -*-
2 #import sys
3 #import codecs
4 import unicodedata
5 #sys.stdout = codecs.getwriter('utf-8')(sys.stdout)
6
7 def _split(s):
8 wc = False
9 st = 0
10 for i, c in enumerate(s):
11 wc_c = unicodedata.east_asian_width(c) in ('W', 'F')
12 if wc != wc_c:
13 r = s[st:i].strip()
14 if r:
15 yield r, wc
16 wc = wc_c
17 st = i
18 r = s[st:].strip()
19 if r:
20 yield r, wc
21
22
23 #s = open(sys.argv[1], "rb").read().decode("utf-8").strip()
24 #for sp in _split(s):
25 # print(sp[0], sp[1])
なんか「もっさり」しててダサくもみえるが、まぁよかろう。(もっさりというか、C/C++ならともかく、スクリプト言語で一文字ずつ処理って、オーバヘッド高いしさ。)
全体あわせて
です:
Acronym を PowerShell に喋らせる、(裏)Acronym を PowerShell に喋らせるからの流れで、Python 側に多くの処理がいるのは一緒。で、吐き出す ps1 はこうしたいのです:
1 [Reflection.Assembly]::LoadWithPartialName("Microsoft.Speech")
2 $speak = New-Object Microsoft.Speech.Synthesis.SpeechSynthesizer
3 $speak.Rate = 3 # from -10 to 10, default is zero.
4 $speak.SetOutputToWaveFile("C:\Users\hhsprings\mmm.txt.mp3")
5 $speak.SelectVoice("Microsoft Server Speech Text to Speech Voice (ja-JP, Haruka)")
6 $speak.Speak("かしゆかです。のっちです。あぁちゃんです。三人合わせて")
7 $speak.SelectVoice("Microsoft Server Speech Text to Speech Voice (en-US, Helen)")
8 $speak.Speak("Perfume")
9 $speak.SelectVoice("Microsoft Server Speech Text to Speech Voice (ja-JP, Haruka)")
10 $speak.Speak("です。よろしくお願いします。")
11 $speak.Dispose()
ので、スクリプト全体通して:
1 # -*- coding: utf-8 -*-
2 from os import path
3 import sys
4 import codecs
5 import subprocess
6
7
8 #
9 def _split(s):
10 import unicodedata
11
12 wc = False
13 st = 0
14 for i, c in enumerate(s):
15 wc_c = unicodedata.east_asian_width(c) in ('W', 'F')
16 if wc != wc_c:
17 r = s[st:i].strip()
18 if r:
19 yield r, wc
20 wc = wc_c
21 st = i
22 r = s[st:].strip()
23 if r:
24 yield r, wc
25
26
27 # =============================================
28 ifn = sys.argv[1]
29 fn = "tmp.ps1"
30 fo = codecs.getwriter('cp932')(open(fn, "w"))
31
32 # ---------------------------------------------
33 fo.write("""\
34 [Reflection.Assembly]::LoadWithPartialName("Microsoft.Speech")
35 $speak = New-Object Microsoft.Speech.Synthesis.SpeechSynthesizer
36 $speak.Rate = 3 # from -10 to 10, default is zero.
37 $speak.SetOutputToWaveFile("{}.mp3")
38 """.format(path.join(path.abspath("."), path.basename(ifn))))
39 # ---------------------------------------------
40
41 #
42 _voice = {
43 True: "Microsoft Server Speech Text to Speech Voice (ja-JP, Haruka)",
44 False: "Microsoft Server Speech Text to Speech Voice (en-US, Helen)",
45 }
46
47 # ---------------------------------------------
48 s = open(ifn, "rb").read().decode("cp932").strip()
49 for sp in _split(s):
50 fo.write(u"""\
51 $speak.SelectVoice("{}")
52 $speak.Speak("{}")
53 """.format(_voice[sp[1]], sp[0]))
54 # ---------------------------------------------
55 fo.write("""$speak.Dispose()
56 """)
57 fo.close()
58 # ---------------------------------------------
59
60 # =============================================
61 subprocess.call([
62 "C:/WINDOWS/SysWOW64/WindowsPowerShell/v1.0/powershell",
63 path.abspath(fn)])
64 # =============================================
なお、「あ~ちゃん」は「アカラチャン」と読んでしまいます。切ない。
2022-01-17追記というか、Haruka さんが…
最初に書いてからほんとに稀にしか必要としてこなかったネタで、完全に塩漬けしちゃってたもんだから、Windows 10 になってからはじめてこれをやり直し、して、ハマっちまった。
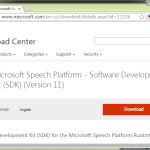
まず、上で「貧乏性と収集癖を駆使して」の下にあるリンクからダウンロードして…という流れは一緒なのだけれど、「Install Instructions」の指示を読み忘れないように、てこと。上で書いた状態は、そもそもランタイムを先にインストールしてたんだと思う。覚えてないけど。
その上で、なんだけれど、なんかさー、もう「Speak error ‘8000FFFF’.」で先に進まんのだわ。しかも Haruka さんのだけ。つまり日本語環境がダメなの。わからん…のだが、あんまり突き止めようとも思ってなくてなぁ…。確かにこういう術を持っておくこと自体は有用なんだけれど、「完璧な音声合成環境を Windows にタダでほしい」がワタシのゴールではないからさ。本気用途なら金出してでもちゃんとしたの買えよ、とも思うし、そもそも「Windows で」に執着する意味もないし。一番大きな動機は「手軽にテスト検証用の音声が作れる」ことなので、であれば英語で全然いい…のでね。
てわけで Microsoft.Speech についてはこれだけなんだけれど、実は半年ほど前になかなかのオンラインツールを見つけてたんで、ちょっとばかし紹介。CoreFontね。
実は最初に紹介された時点では何も手続きなく無料で使えたんで試せて、UI はそれほど使いやすくはないものの必要最小限は出来て、結構いい感じだな、と思ったんだよね。数人の声を切り替えながら会話を組み立てていく要領でテキストを埋めていく、って感じのインターフェイスで、抑揚の調整が出来て、音声ファイル(MP3だったかな)にしてダウンロードも出来た。
今これをやろうとすると、無料でもユーザ登録が必要なのよ。それも電話番号を要求しちゃうやつ。まぁほんとに氏名と電話番号だけなんで大したこともないんだけれど、今ワタシはそこまでやりたくはないのでやってない。けど記憶が正しいなら全然悪いものじゃなくて、手軽に音声合成する選択肢の一つとして間違いなくちゃんと機能する、ハズ。(実はこれを紹介されたのはとあるエロ関連。実際これで作った音声を公開してて、直接そこに誘導すればこのツールの出来を想像できろうからそうする手もあるんだけれど、ちょっとエロはエロでも扱いが繊細なやつなんでここでは紹介しない。)
もうひとつ、今探して見つけてみたこれも良いわね:
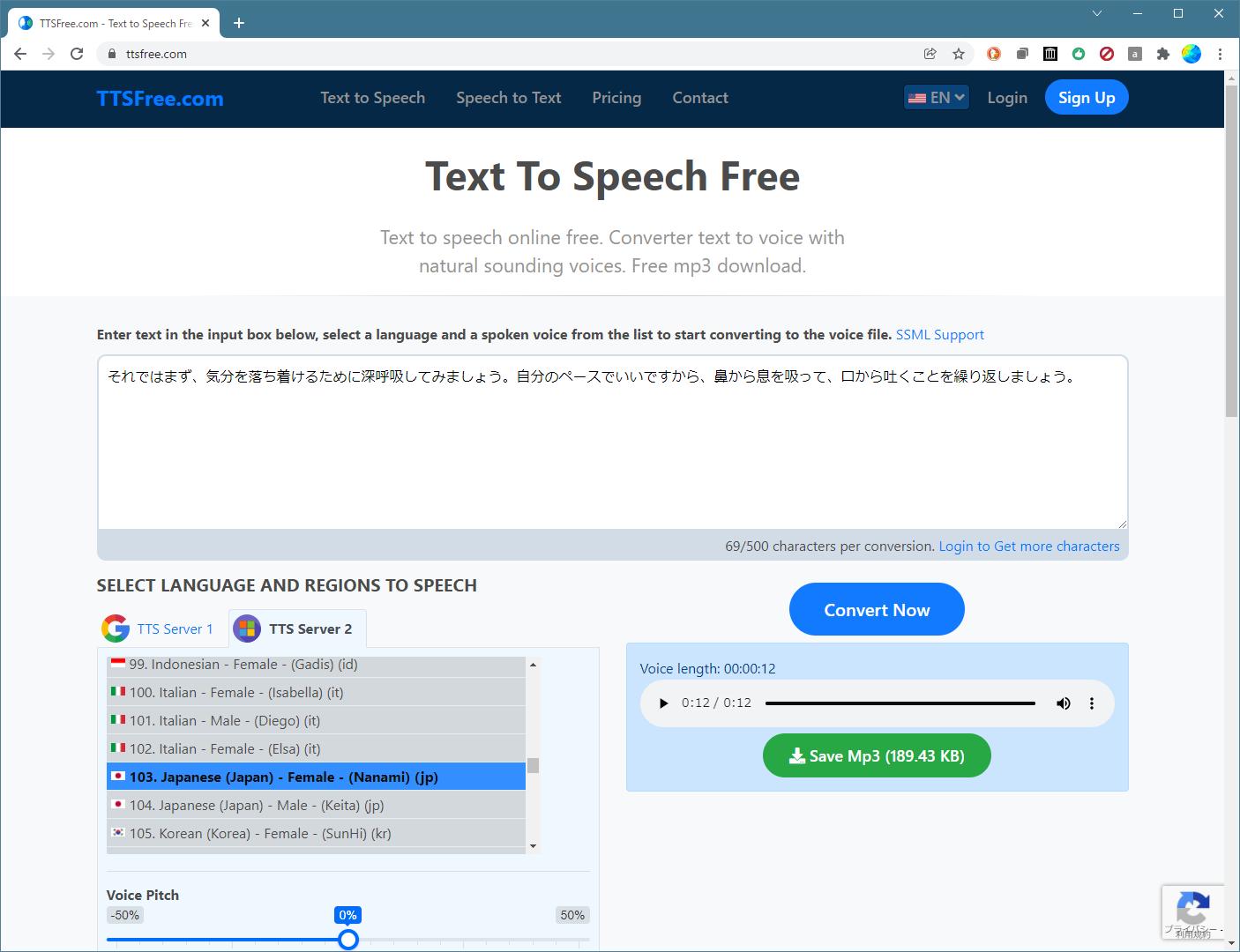
500文字までしか入らないのと、ほんとにテキストボックス一個で全文を変換するだけ、という単純極まりない(単純過ぎる)インターフェイスは場合によってはストレスとなるではあろうが、ただこれ、非常に驚異的なのは、日本語の読み間違えをほとんどしない、ということ。すごい辞書を持ってるみたいだ。なんかサーバに接続して実現してるみたいだから、これはひょっとしたら Microsoft のサーバが優秀なのかもしらんね。
つーかあれか、これが出来るんだったら、自分でこれらのサーバ(たぶんこれだと Google のものと Microsoft のものなんだろう)とお喋りするクライアントを書く、みたいなことも考えてもいいのかもしらんね。
2022-01-18 16時 さらにちょっとだけ追記:
CoreFont がやや重めのユーザ登録が必要になってるのはそうなんだけれど、ふと Chrome で開きっぱなしになってたことに今気付いた。どういうわけか Windows 再起動も経てるのにログイン状態を維持出来てる:
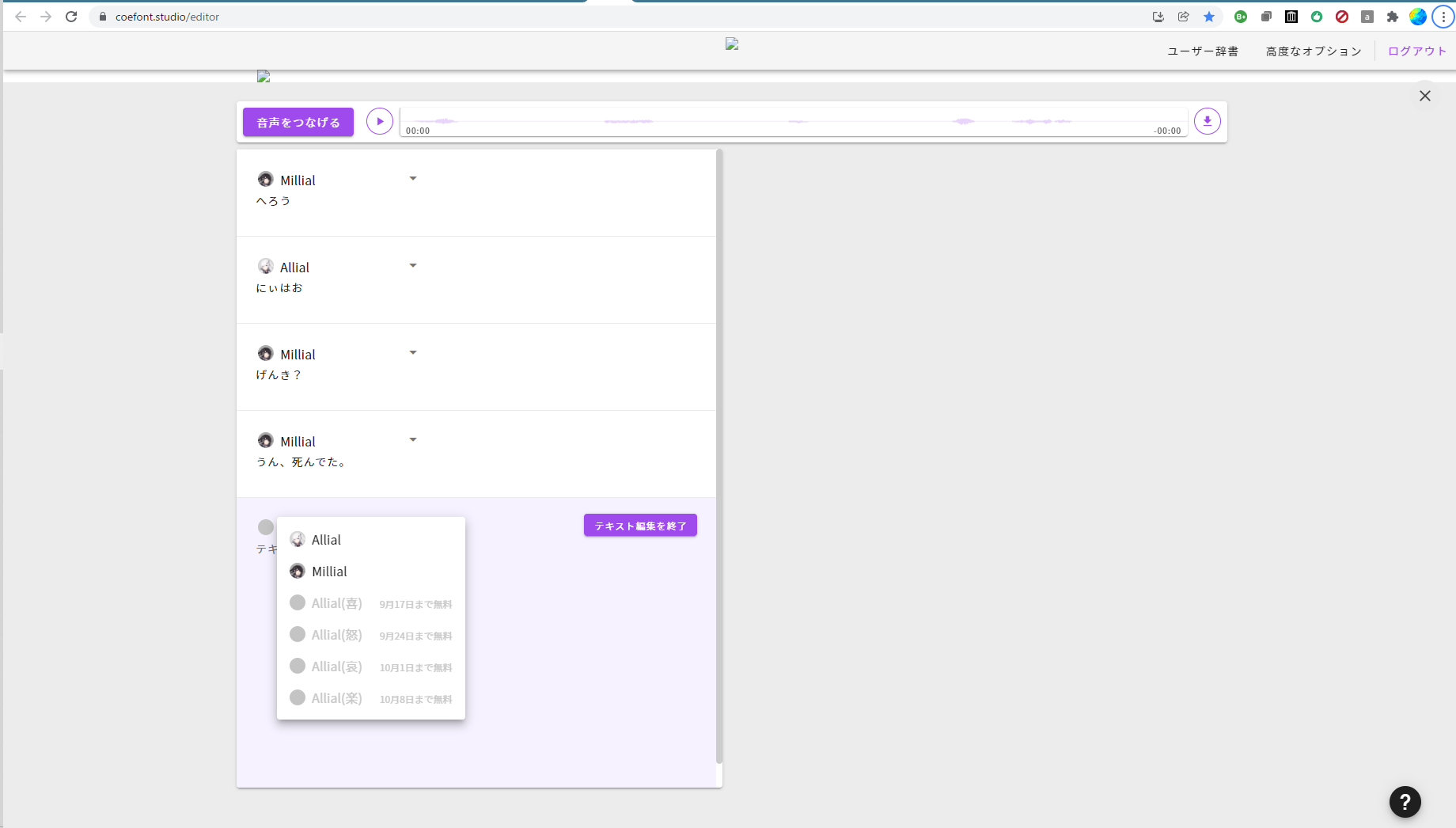
この Chrome タブを閉じたらもうちゃんとユーザ登録しないと使えないと思う。ともあれこんな UI ね。悪くなさそうでしょ? やってみるとちょっと抑揚調整が言うこと聞かなかったりとかしたけれど、ただ、UI としては「正解」だと思うんだよね。こういう「対話」を音声化したいんだと思うんだよ。確かに「一つの文書を読み上げる」というのも一つのユースケースだろうから ttsfree.com 的な UI が完全に誤りである、てことではないんだけれど。
edge-tts @ Python
「@Python」言うとる時点でもうトピック違いなんだけれど、「TTS りたいだけなんぢゃ」というワタシのような人もいると思うので話を続ける。
CoreFont がキビシイ、ttsfree.com も登録なしだと制約が大きくてやだなぁ、というわけだが、ttsfree.com が「TTS サーバー」に対するクライアントであることに着目すれば、「きっと別のクライアントがあるならあるはずあるだろう」と、思うはずだ、思うだろう、思ってくれ。ワタシの場合は生活の中心が Python なので、やはり Python から探す。PyPI で探せば「いっぱつ」というほどではないけれど、検索結果の比較的上の方に出てきた、edge-tts が。:
edge-tts is a Python module that allows you to use Microsoft Edge’s online text-to-speech service from within your Python code or using the provided edge-tts or edge-playback command.
名前から察するに ttsfree.com が使っている Microsoft のほうの TTS サーバーと同じなのではないかしら、と期待してみた。案の定:
1 [me@host: ~]$ py -3 -m edge_tts --list-voices | grep -A 4 ja-
2 Name: Microsoft Server Speech Text to Speech Voice (ja-JP, NanamiNeural)
3 ShortName: ja-JP-NanamiNeural
4 Gender: Female
5 Locale: ja-JP
6
7 Name: Microsoft Server Speech Text to Speech Voice (jv-ID, SitiNeural)
8 ShortName: jv-ID-SitiNeural
9 Gender: Female
--list-voices が不完全のようでランタイムエラーで完遂しなくて、ゆえに本当は「keita(男声)」があるはずと思うが列挙できない。けれどもこの「nanami」は、まさに ttsfree.com が依存している Microsoft の TTS サーバと同じもののようだ。実装はこんなかんじ:
1 """
2 Constants for the edgeTTS package.
3 """
4
5 TRUSTED_CLIENT_TOKEN = "6A5AA1D4EAFF4E9FB37E23D68491D6F4"
6 WSS_URL = (
7 "wss://speech.platform.bing.com/consumer/speech/synthesize/"
8 + "readaloud/edge/v1?TrustedClientToken="
9 + TRUSTED_CLIENT_TOKEN
10 )
11 VOICE_LIST = (
12 "https://speech.platform.bing.com/consumer/speech/synthesize/"
13 + "readaloud/voices/list?trustedclienttoken="
14 + TRUSTED_CLIENT_TOKEN
15 )
257 # ...
258 async with aiohttp.ClientSession(trust_env=True) as session:
259 async with session.ws_connect(
260 f"{WSS_URL}&ConnectionId={connect_id()}",
261 compress=15,
262 autoclose=True,
263 autoping=True,
264 headers={
265 "Pragma": "no-cache",
266 "Cache-Control": "no-cache",
267 "Origin": "chrome-extension://jdiccldimpdaibmpdkjnbmckianbfold",
268 "Accept-Encoding": "gzip, deflate, br",
269 "Accept-Language": "en-US,en;q=0.9",
270 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
271 " (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41",
272 },
273 ) as websocket:
274 for message in messages:
275 # ...
わかると思うが WEB サービスに対するクライアントなので、「Microsoft’s」だからといって Windows でしか使えないということではないし、「Edge’s」だからといって Microsoft Edge ブラウザを要求するわけでもなく、きっと OS X だの UNIX だの、android だので使える…、んじゃないかと思う。
「mytxt.txt」という utf-8 でエンコードしたテキストファイルを入力として:
1 [me@host: ~]$ py -3 -m edge_tts --voice "ja-JP-NanamiNeural" -f mytxt.txt > mytxt.mp3
としたら、オンラインで ttsfree.com で作ったのと同じナナミさんで読み上げた音声ファイルが作られた。出来上がった音声ファイルは 51分にもなるものなんだけれど、生成時間はびっくりするくらい短時間だった。体感で1分くらいか? もう少しかかったかもしれんけど、いずれにしてもかなり速かった。それと上で驚いている通りで、びっくりするほど読み間違いしない。だからテキストの微調整はかなり最低限で済みそう。
ttsfree.com でそうだったように、こちらも SSML を使えるし、edge_tts としての CLI は SSML 前提の「--pitch」などのオプションを用意してくれている。読み上げの演出には SSML を自力で駆使するしかないが、グローバルに全体の声音を変えたいってことなら、このコマンドラインオプションを活用出来るだろう。対して、「SSML を自力で駆使する」には「-z オプション」(--custom-ssml)を使う。
ttsfree.com は「SSML フルサポート」でなかったが、それよりは少しいいみたい:
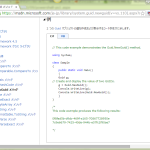
1 <speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xml:lang='ja-JP'>
2 <voice name='Microsoft Server Speech Text to Speech Voice (ja-JP, NanamiNeural)'>
3 <prosody pitch='+44Hz' rate='-30%' volume='+0%'>
4 ナナミさんで読み上げ!
5 </prosody>
6 <prosody pitch='-11Hz' rate='-10%' volume='-50%'>
7 ナナミさんで読み上げ?
8 </prosody>
9 </voice>
10 </speak>
1 [me@host: ~]$ py -3 -m edge_tts -f sample1.ssml -z > sample1.mp3
1 <speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xml:lang='ja-JP'>
2 <voice name='Microsoft Server Speech Text to Speech Voice (ja-JP, KeitaNeural)'>
3 <prosody pitch='+44Hz' rate='-30%' volume='+0%'>
4 ケイタさんで読み上げ!
5 </prosody>
6 <prosody pitch='-11Hz' rate='-10%' volume='-50%'>
7 ケイタさんで読み上げ?
8 </prosody>
9 </voice>
10 </speak>
1 [me@host: ~]$ py -3 -m edge_tts -f sample2.ssml -z > sample2.mp3
volume は効いてなさそうに思うんだが、rate も pitch もちゃんと意図したとおりに振る舞ってるみたい。
というわけでアタシ的にはとってもええもん見つけたわい、と思っておるが貴様はどうか。
2022-03-21追記: ハルカ復活
正確な言い回しだと「ハルカ、別の形で復活」。
Windows 11 に乗り換えたのだけれど、そのインストール直後に一瞬音声合成の何かが変わったのが「見えた」んだよね。すぐにそのダイアログは自動で閉じてしまったので、「何かが起こった」ことしかわからなかったんだけれど、今把握したところによればおそらくこれ:

「Haruka Desktop ってなんぞ?」てことさね。
で、検索。ここ:

まだ正確な理解は出来てないが、もしかすると「Microsoft.Speech ではなく System.Speech で万事おk」てことかも。
ここまでの流れを読んだ方はわかってくれてるかもしれないが、ワタシは「Microsoft Speech Runtime 11 / SDK 11」と個々のボイスをインストールした上で「Windows 10 では Haruka が動かん」と言ってたわけね。そして、その状態の Windows 10 を「無料アップグレード」して Windows 11 にした、というのが今のワタシの PC の状態。だから、まっさらな Windows 11 で System.Speech が使えるのかどうか、Microsoft Haruka Desktop が動作するのかどうかについてはわからない。けど、このワタシの状態ならリンク先記事のサンプル(を Haruka Desktop に読み替えたもの)が完全に動いた。つまりこれが期待通り動く:
1 #[Reflection.Assembly]::LoadWithPartialName("Microsoft.Speech")
2 [Reflection.Assembly]::LoadWithPartialName("System.Speech")
3 #$speak = New-Object Microsoft.Speech.Synthesis.SpeechSynthesizer
4 $speak = New-Object System.Speech.Synthesis.SpeechSynthesizer
5 $speak.Rate = 3 # from -10 to 10, default is zero.
6 #$speak.SetOutputToWaveFile("C:\Users\hhsprings\mmm.txt.mp3")
7 $speak.SetOutputToDefaultAudioDevice()
8 #$speak.SelectVoice("Microsoft Server Speech Text to Speech Voice (ja-JP, Haruka)")
9 $speak.SelectVoice("Microsoft Haruka Desktop")
10 $speak.Speak("かしゆかです。のっちです。あぁちゃんです。三人合わせて")
11 #$speak.SelectVoice("Microsoft Server Speech Text to Speech Voice (en-US, Helen)")
12 $speak.SelectVoice("Microsoft Zira Desktop")
13 $speak.Speak("Perfume")
14 #$speak.SelectVoice("Microsoft Server Speech Text to Speech Voice (ja-JP, Haruka)")
15 $speak.SelectVoice("Microsoft Haruka Desktop")
16 $speak.Speak("です。よろしくお願いします。")
17 $speak.Dispose()
Microsoft.Speech と System.Speech とで API に違いがあるのかどうか、などもまだ把握してないけど、とにかくワタシは再びハルカさんをオフラインで利用できる術を得たのだと悟ったのでした。めで。
2022-03-21 14時追記: オフラインで再び日本語の音声合成が出来るようになったのは喜ばしいが、Microsoft Edge’s TTS Server を知ってからここに戻ってくるとかなりガッカリする
2015年の時点でのワタシの興味が「とにかく音声合成出来ること」、喋ってくれればおっけー、だけだったので、ほんとに最小限しかやらなかったわけね。で、「Windows 10 でハルカが動かん」として Microsoft Edge TTS サービスにたどり着き、そこでは「どちらかといえば使い倒そうとするノリ」にしたので、こうやって「ハルカ再び」すると、ガッカリするんだなぁこれが。
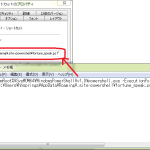
まず「SSML ファイルを入力として SpeakSsml するだけの Powershell スクリプト」:
1 param(
2 [Parameter()]
3 [String]$ssmlfile
4 )
5
6 $ssml = Get-Content -Path $ssmlfile -Encoding UTF8
7
8 [Reflection.Assembly]::LoadWithPartialName("System.Speech")
9 $speak = New-Object System.Speech.Synthesis.SpeechSynthesizer
10 $speak.SetOutputToDefaultAudioDevice()
11 $speak.SpeakSsml($ssml)
12 $speak.Dispose()
簡単でしょ。あとはこのスクリプトに、SSML ファイルを喰わせればいい。んだけどね、もう phoneme が使えないことが既にわかったし、speed 指定もなんかヘン(prosody そのものが使えない可能性あり)。随分限定的な SSML サポートらしい。
「オフラインでも」音声合成出来ることそのものはありがたいことだけれど、こういうことなので、割り切って考えるしかないかなぁ…。
2022-03-21 15時追記: eSpeak の TTSApp がどうやら Haruka Desktop を認識する…と思ったが勘違い
知らなかったのだが eSpeak って Microsoft.Speech (System.Speech) と統合されてるんだな:
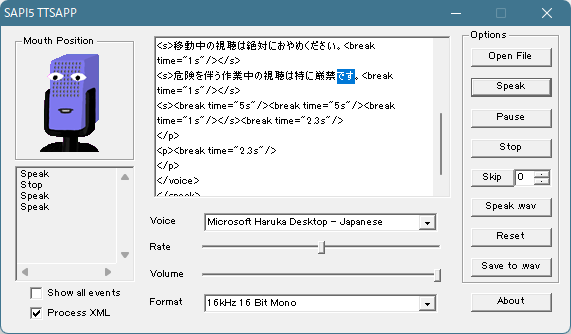
この TTSApp は使いにくいので(eSpeak 自体はライブラリなので)なんとか他の UI を見つけたいところだが、でもこれ、「Microsoft Haruka Desktop + Windows の Speech エンジンよりも制約が少ない SSML を使えるエンジン」なのよ、少なくとも phoneme が使えることは確認した。
と、ちょいちょい調べてたら、どうもこれ、eSpeak プロジェクトの持ち物じゃないらしい。オリジナルは SDK を使った SAPI サンプルで、なのでこれは Microsoft 製。なんで eSpeak をインストールするとバンドルされてるのか謎だが、なので「Microsoft.Speech (System.Speech) と統合されて」て当たり前。そして「残念ながら」commandline/ フォルダに突っ込まれてる「本来の espeak.exe」では Microsoft Haruka Desktop は使えない。こりゃ弱ったの。
いずれにしても、「もしかしたらこれは微救世主」であることには違いない。使いにくいけれども使えないわけではないのだから。