見出しの通り「gnuplot でグラフ一例…」の中に入れちゃってた内容を移動してきた。
pyr のことを書きたくなって、だとすると分割したくなり。
Contents
「gnuplot でグラフ一例…」内に追記で書いてた「R でグラフ」+α (pyr2)
「gnuplot でグラフ一例…」内に追記で書いてた「R でグラフ」
2021-04-11:
「見える化のためのスキル」のうち「簡易なもの」の代表が excel などの「ワークシート」だとするならば、「本格的なもの」の代表となるのが、これまで挙げてきた Matplotlib や R、あるいは MATLAB などであろう。gnuplot は、感覚的には中間的なところな気がするね。
で、統計解析パッケージの「R」についても一応ひとつ例を:
1 #
2 require(graphics)
3 #
4 pref <- read.csv("prefectures.csv")
5 pref$ymd = as.Date(paste0(pref$year, "-", pref$month, "-", pref$date))
6 pref <- subset(pref, prefectureNameE == "Tokyo")
7
8 #
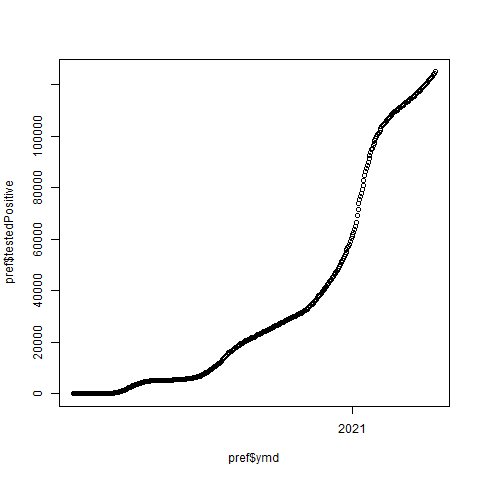
9 png(file = "prefectures-Tokyo-testedPositive.png", bg = "transparent")
10 plot(pref$ymd, pref$testedPositive)
11 dev.off()
1 #
2 require(graphics)
3 #
4 pref <- read.csv("prefectures.csv")
5 pref$ymd = as.Date(paste0(pref$year, "-", pref$month, "-", pref$date))
6 pref <- subset(pref, prefectureNameE == "Tokyo")
7 pref$testedPositive = append(
8 head(pref, n=1)$testedPositive,
9 tail(pref, n=nrow(pref) - 1)$testedPositive - head(pref, n=nrow(pref) - 1)$testedPositive)
10
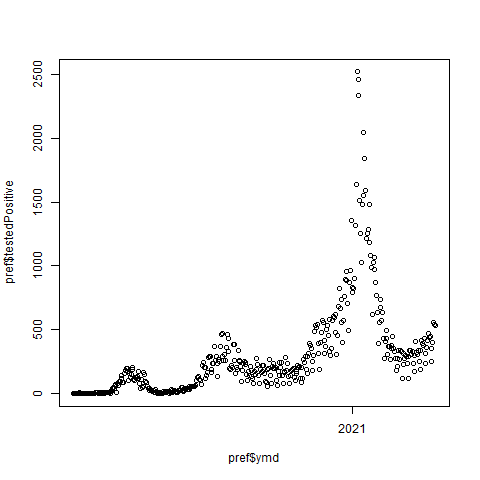
11 #
12 png(file = "prefectures-Tokyo-testedPositive_diff.png", bg = "transparent")
13 plot(pref$ymd, pref$testedPositive)
14 dev.off()
1 #
2 require(graphics)
3 #
4 pref <- read.csv("prefectures.csv")
5 pref$ymd = as.Date(paste0(pref$year, "-", pref$month, "-", pref$date))
6 pref <- subset(pref, prefectureNameE == "Tokyo")
7 pref$testedPositive = append(
8 head(pref, n=1)$testedPositive,
9 tail(pref, n=nrow(pref) - 1)$testedPositive - head(pref, n=nrow(pref) - 1)$testedPositive)
10
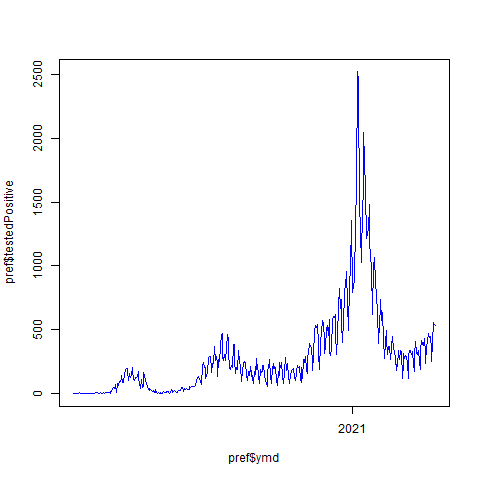
11 #
12 png(file = "prefectures-Tokyo-testedPositive_diffL.png", bg = "transparent")
13 plot(pref$ymd, pref$testedPositive, type = "l", col = "blue")
14 dev.off()
1 #
2 require(graphics)
3 #
4 pref <- read.csv("prefectures.csv")
5 pref$ymd = as.Date(paste0(pref$year, "-", pref$month, "-", pref$date))
6 pref <- subset(pref, prefectureNameE == "Tokyo")
7 pref$testedPositive = append(
8 head(pref, n=1)$testedPositive,
9 tail(pref, n=nrow(pref) - 1)$testedPositive - head(pref, n=nrow(pref) - 1)$testedPositive)
10
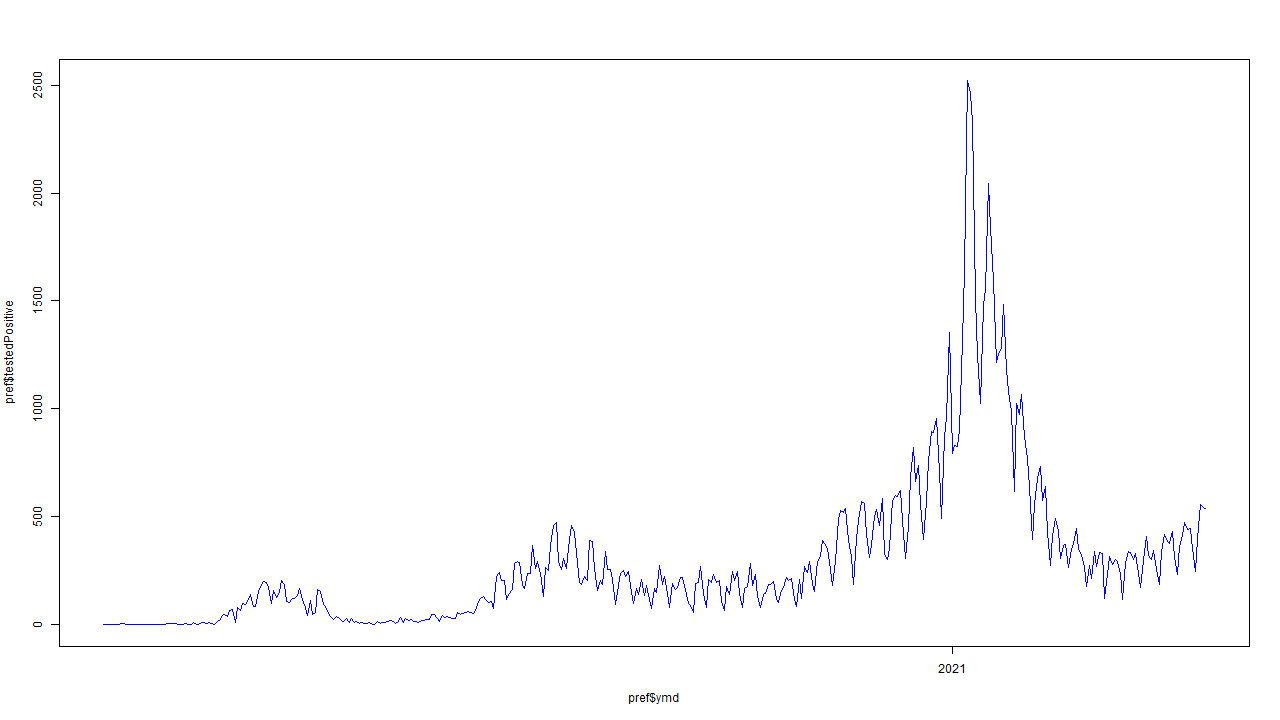
11 #
12 png(
13 file = "prefectures-Tokyo-testedPositive_diffL_2.png",
14 bg = "transparent",
15 width = 1280, height = 720)
16 plot(pref$ymd, pref$testedPositive, type = "l", col = "blue")
17 dev.off()
R に関して、「お気楽ご気楽、誰でも出来るぜ」というには程遠く、むろん「取っつきにくいし、なんなら熟達しても難しいところはずっと難しい(特にグラフィクスの制御)」ものなのだが、それでもなお(MATLAB とは違い)「八百屋が売り上げ戦略を練るのに使う」ために支払うコストは、パソコンやインターネットといったランニングコストを除けば「学習」のみ、誰かに金銭を支払ったりする必要がない、のは Python (+ matplotlib) や gnuplot などと同じ。
それと、python などと同じくデータ読み込みから加工、そして「解析」までを R 自身で行える。「統計解析パッケージ」ですから。python と違って「何でも出来る」ことを目指していない「統計解析だけを行う」ものだが、それをするための高級言語にはなっていて、データの取り回しは非常にパワフルに柔軟に行える。上の例では、東洋経済オンラインによるちょっと使いにくいフォーマット「year,month,date」を結合して使いやすくする、てことを一撃でやっている。2つめからのスクリプトではさらに「東洋経済オンラインのデータは積算なので新規感染者数に読み替える」のも比較的簡単にやっている。numpy/scipy のインターフェイスとはだいぶ違うが、それでも「マトリクス志向」である点は共通しているので、まぁ慣れだ、慣れ。
MATLAB が「数学系」に好んで使われ、NumPy/SciPy (+ matplotlib 等) が「科学技術系」に好んで使われる、てことなのだが、実際、使われているドメインの幅広さだけだと「R」が一番広いかもしれない。書店で、R 関連の書籍がずらっと並ぶカテゴリを是非観察してみて欲しい。「コンピュータ関連書籍」ではない場所に大量に置かれている場所を発見出来るだろう。実際、理系分野でもとりわけ農学系などでも盛んに利用され、文系では金融関係はもちろんのこと、社会科学系などでも頻繁に使われていることがわかる。(想像だが、Fortran/LAPACK/BLAS などに親しんだ分野の人々がそれをベースにしている MATLAB や numpy 系を好み、そうでない人々が R を好んでいるのではないかと思う。一番根底の部分では結局は同じ数学に辿り着くのだが、MATLAB/numpy 系は「行列・テンソルなどの基礎部分」を前面に押し出し過ぎていて、理系以外が見ると怯んでしまうだろうとは思う。)
まぁそういう「盛んに使っている場所」に生息するのは「その道の専門家(とその卵)」たちなので、Matplotlib に対しての態度がそうであるように、「難しくてなんぼ」と思ってる人々。だから、ごく平均的な一般人が R を使ってみて「難しすぎる、簡単になるべきだ」と叫んだところで、「簡易であるべき運動」はそれほど盛り上がらないだろう。簡単に入手できることと簡単に使えることとは全くの別問題。
それでも、である。何度でも言うけどね、「昔はこうしたものを入手することからして、ごく少数の人間に与えられた特権だったのだ」てこと。つまり、「胡瓜農家が R 使いで何が悪い」。そう出来るならそうすればいい。出来るのだ、ということを知っておくと良い、て話。
ちなみに、R はそもそもが「剝き身で膨大で、なおかつサードパーティ製ライブラリ選びが難儀」なところが、特に初学者にはハードルが高い。あと特に Windows でのグラフィックスの言うこと聞かないっぷりはなかなかストレスフルなところもあった。少なくともワタシが少し使ってた10年ほど前は。今はどうなのかな。今やってみせたのは、そう、10年ぶりにやってみたやつなんだけど、これだけならそれだけ。もっと細かいことをやりだすのに、今でもつまづくかどうか、だ。どうなんだろね? (本日時点最新は version 4.0.5。)
2021-04-12追記:
「色んな手段を知っておけばいい」の流れで GNU Octave てのもある。MATLAB に対するフリーの代替であることがゴール、てことからわかる通り、これまでワタシが書いてきたものの中だと NumPy/SciPy/MatplotLib 系に近い。ただ、これまでのものはワタシは一度は使ったことがあるものだったのに対し、こちらは一度もユーザだった経験もないし触れたことすらない、ので、「ほらね」はやめとく。「MATLAB 相当」で怯むのがひとまず正解の、「猿には使えない」ものなのではある。そもそも、Octave について「名前くらいは知ってた」人には、ワタシが追加で言うこともないほど色々知ってるだろう。一度も聞いたことがない人には、明らかにツーマッチ候補だろう。
Octave について触れることによっても言いたいことはやはり同じ。「専門家と同じ道具を手に入れることだけならタダ」。
なお、少しだけ細かく言っておくと、Octave の本体はこれは「数値演算パッケージ」であって、ビジュアライズは機能のうちの一部である。で、かつてはバックエンドが gnuplot そのものだったんですと。途中から独自にやりだした、てことみたい。なので、「見える化ろうぜ」ネタとして gnuplot と octave を別々に扱うことには価値はある。
…まぁ…、gnuplot も octave もそうなんだけど、こやつらってのは古いだけあって探せば情報は非常に多いのよね。ただし、「大昔に書かれて更新されてなくて、サイトデザインも古臭くてよみづらい」状態で放置されてるのが多くて、今の時点で後追いで学ぼうとするユーザにとっては良い状態ではないんだよね。なので、ほんとは「真っ先にオススメするもの」の候補にはしづらいんだよね。やっぱドキュメントって大事。
2021-06-14: python + R は最強である可能性はありや、なしや?
かなり人によるとは思うものの、「R + python が出来るならば、ある意味最強」となる場合もあるんじゃなかろうか、と思って。
ワタシはとにかく最初に R に触れた時の印象が最悪だったので「R のグラフィックはサイアク」だと思い続けてる。言うなれば「トラウマ」というヤツだ。これが真実なのかどうかとは関係なく、とにかくワタシにとっての R は、「データ処理としてはとても良いものだが、これでお絵かきはしたくない」と思っている、ということ。「だったらデータ処理だけ R でやらせて、お絵かきは matplotlib でやっちゃえばいいんじゃん」が出来るだろうか、と。
無論 R を実行して、その結果のデータを csv などの形式に書き出して…というアプローチを採るならなんとでもなるけどそうじゃなくて「組み込みR」てこと。すなわち rpy2 を使ってみる:
1 # -*- coding: utf-8 -*-
2 from datetime import date, timedelta
3 import numpy as np
4 import matplotlib
5 import matplotlib.pyplot as plt
6 # rpy2 は、R の C API を python ラップしたものである。
7 # Python の C API がそうであるように、「スニペットを丸ごと eval」してしまうような
8 # high level API とともに、R のステートメント一行一行に対応するような low level
9 # API もある。今回使ってみるのは前者。
10 import rpy2
11 import rpy2.robjects as robjects
12
13
14 # 「plot_prefectures_4.R」からデータ処理部分だけ抜き出した断片。
15 _R_CODE = """
16 #
17 pref <- read.csv("prefectures.csv")
18 pref$ymd = as.Date(paste0(pref$year, "-", pref$month, "-", pref$date))
19 pref <- subset(pref, prefectureNameE == "Tokyo")
20 pref$testedPositive = append(
21 head(pref, n=1)$testedPositive,
22 tail(pref, n=nrow(pref) - 1)$testedPositive - \
23 head(pref, n=nrow(pref) - 1)$testedPositive)
24 """
25 robjects.r(_R_CODE)
26 pref = robjects.globalenv['pref']
27 T = [
28 date(1970, 1, 1) + timedelta(days=int(ymd))
29 for ymd in pref[pref.colnames.index("ymd")]]
30 Y = np.array(pref[pref.colnames.index("testedPositive")])
31 #
32 fontprop = matplotlib.font_manager.FontProperties(
33 fname="c:/Windows/Fonts/meiryo.ttc")
34 fig, ax1 = plt.subplots(tight_layout=True)
35 fig.set_size_inches(16.53 * 1.4, 11.69)
36 ax1.plot(T, Y)
37 ax1.grid(True)
38 ax1.set_title(
39 "「東洋経済オンライン「新型コロナウイルス 国内感染の状況」」を加工",
40 fontproperties=fontprop)
41 fig.savefig(
42 "cov19viz_tokyo_testtedPositive_{}.png".format(
43 str(T[-1]).replace("-", "")[4:]))
44 plt.close(fig)
45 # 結果の画像は想像通りのものなので貼り付けない。
今のワタシのケースの場合、たとえば「とても興味深い実装が R にあるのを見つけた」として、この時に「ワタシは R は不得手だがこの資産をどうにか活用したい」と考えたとする。しかも「R はあまりよくわからないので、出来るだけ元の R に手を加えたくない」として。そして「グラフについては元のやつが相当ダサいので、この際ワタシが得意な matplotlib でかっちょよく描画しちゃれ」と考えたとしたら、まさに例にしたような実装になる。
人によってはまったく逆のことを考えるだろう。「numpy のことはまったくわからないがとてもステキな計算をしているのをみつけた」→「ワタシの得意な ggplot2 でかっちょよく描画しちゃれ」:
1 # -*- coding: utf-8 -*-
2 import io
3 from datetime import date, timedelta
4 import numpy as np
5 import rpy2
6 #import rpy2.robjects.packages as rpackages
7 import rpy2.robjects as robjects
8 from rpy2.robjects import numpy2ri
9
10
11 #
12 era = "2020/1/16"
13 era = date(*map(int, era.split("/")))
14 # toyokeizai_online_covid19.npz は別の python スクリプトで東洋経済オンライン
15 # のデータを少し加工して npz に仕立てたもの。移動平均など元データにないものを
16 # 計算して突っ込んでいる。
17 dattko = np.load(io.open("toyokeizai_online_covid19.npz", "rb"))
18 # ↓「東京」を取り出すつもりで間違って神奈川を取り出しちゃってる。ごめん。
19 npat = dattko["testedPositive_movavg"][:,slice(13, 14)].sum(axis=1)
20 #hosp = dattko["hospitalized_movavg"][:,slice(13, 14)].sum(axis=1)
21 T = robjects.vectors.StrVector([
22 str(era + timedelta(t)) for t in range(len(npat))])
23 numpy2ri.activate()
24 robjects.globalenv['dattko'] = robjects.DataFrame({
25 "ymd": T,
26 "tokyo_newpatmovavg": npat})
27
28 #
29 robjects.r("""
30 #install.packages("ggplot2")
31 library('ggplot2')
32
33 dattko$ymd = as.Date(paste0(dattko$ymd))
34 g <- ggplot(dattko, aes(x=ymd, y=tokyo_newpatmovavg)) +
35 geom_line(color="blue") +
36 scale_x_date(date_labels="%Y-%m-%d") +
37 ggtitle("「東洋経済オンライン「新型コロナウイルス 国内感染の状況」」を加工")
38 ggsave(plot=g, file="cov19viz_tokyo_testtedPositive_0610_2.png")
39 """)

こうしたチャンポンは得てして「どちらの言語にも相当熟達していなければならない」になりがちなので、万人に薦められるものかと言われると答えに窮するものではある。実際 Python と R のデータの授受はわかりやすいものではない。それでも、そうした多少の困難に抵抗がないのであれば、「自分の得意不得意」「R、Python の得手不得手」の両方を考えてどうするか決めれば良い、ということだとは思うのだが…。
正直、やってみせた2つのくらいのことなら、素直に「R で計算した結果を python で読むのに苦痛でない形式で書き出す」「python で計算した結果を R で読むのに苦痛でない形式で書き出す」というところで切って考える方が、少なくとも精神衛生上は圧倒的に良い。特に後者の「python で計算した素敵な計算結果を R で」の方、データ連携がかなり鬱陶しい。
ちゃんと突き詰めてないけれど、おそらく pyr2 の「python ⇔ R データ型変換サポート」が我々が期待する遥かに下のレベルに留まっている、てことだと思う。「鬱陶しい」の詳細はこれは、「数値だけがおさまっている numpy は numpy2ri でスムーズに交換出来るが、それ以外は完全に無頓着らしい」てこと、具体的には「date」がまったくダメ、たぶん中間層で date であったことが忘れ去られる。(rpy2 の python 側にいる時点で rpy2 の Date 型であっても、robjects.globalenv などで R 側に持っていく時点でそのことが忘れ去られる。)
そんな「ウザい」状態であっても rpy2 を使う理由が果たしてあるのか、てことだけれど、要は「csv ファイルに吐き出して、それを読み込む」というのが「気持ち悪い」とか、あるいはデータが巨大で現実にそれが不可能な場合、こうしたインメモリとして python と R がダイレクトに連携することが「オイシイ」となりうる…のだけれど、「巨大で…」って、あるのかねぇ、とは思う。
同じく、low-level インターフェイスを使うおいしさってのも、あんまりない気はする。「C と Python」の関係と違って、おそらく R と python の共存関係は、一方の大きな資産を「出来る限りそのままの形で活用したい」、てものだと思うんだ。そういうのが多いんであれば、果たしてそこまで何度も python と R を行ったり来たりするような使い方って、するであろうか、と。
で、結局なんだけれども、「R + python が出来るならば、ある意味最強」という問いについて、少なくとも rpy2 に頼るということであれば、あんまし最強じゃないと思う。python は python、R は R で分けて考えた方がいい、と思う。rpy2 の価値はせいぜい「場合によっては少し楽な場合もある」という程度でしかなさそう。(ただ幸いなことに「R の資産を python から使う」のケースの方が少し楽なのは救い。)「python と R 両方使うことはある意味最強」ということはないではないとは思うよ、そう思う場合は「別々に使えば?」が今のところの無難な結論。
あとね…、まぁワタシが OSS に対する評価でかなり重視するドキュメント、これがまぁダメだわ、かなり。非常にわかりにくい、これ。
2021-06-15追記: ちょっと考え直してみる+α
話としては3つ。
まず、ちょっと説明というか検証が足りてなかった。「pyr2 だけでいいの?」て話。pyr2 は「R の C API でインターフェイス」したものなのだけれど、R 本体は同梱されないので、本体は本体でインストールする必要がある。
で、そういう関係なので、たとえば
1 # -*- coding: utf-8 -*-
2 import rpy2
3 import rpy2.robjects as robjects
4 robjects.r("""
5 install.packages("ggplot2")
6 """)
とすれば R 本体のパッケージマネージャが起動し、本体管理のパッケージ置き場にインストールされる。たとえば Windows 版 4.0.5 であれば「c:/Program Files/R/R-4.0.5/library/ggplot2」として。
「pyr2 さえ入れとけば R 本体をインストールすることなく R が使える」のだとするとちょっと違った世界も開けることもあるんだけれど、これについてはそうではないてことね。
追記したくなった一番の本題が二つ目。pyr2 に対してネガティブめな評価をしたけれど、ちょっと冷静に考え直してみようかと。
ふと思ったのだけれど、「numpy は numpy2ri でスムーズに交換出来るが、それ以外は完全に無頓着」といったけれど、「それ以外」がよく考えたらあんまないなと。「数値とベクター、マトリクス」に関してほとんどオッケーとして、以外となればまずは「文字列」だけど、これはもちろん何の問題もない。というか上のスクリプトでやってる。「StrVector」ね、ベクターに詰め込む場合は。
「データ連携」と言った場合に、基礎として置かれるものは、多くの場合「数値・文字(列)などの「値」、シーケンス、ハッシュ」という三つ組なのは json や YAML といったものをみればわかるだろう。問題はこの「値」としてどこまで組み込んでおくか、てことよね? そこに「日付・日付時刻」を含める派と含めない派は、たぶんちょうど半々くらい。SQL がこれを含めている印象から考えれば「あるのが当然」と思うに至るだろうけれど、json 基準だと「必須とまではしなくていいかもね」という気分にもなる。
「R」「Python」という個々の環境そのものは日付型を用意しているものの、その境界層がそれをサポートしていない、という事実について、要はこれがもしも日付時刻じゃなかったらどう思うのか、ということ。少なくともこれが「geometry型」なら、現時点でのエンジニアの多くは致し方ないと受け容れるだろう。日付時刻が相手だからちょっと微妙な気分になるだけだ。というふうに、受け容れてしまえばなんてことない問題、てことはないかしらと。どうかなぁ?
たとえばそれを受け容れた世界。「excel との連携」なんてのを考えたとする。普通は Python だけの世界から excel を扱えるライブラリを検討するわけなんだけれど、「R のパッケージ」から見繕おうと考えるのも一つの手になってくるのよね、たとえば:
1 # -*- coding: utf-8 -*-
2 import rpy2
3 import rpy2.robjects as robjects
4 robjects.r("""
5 #
6 #install.packages("readxl")
7 library("readxl")
8
9 pref <- read_excel("prefectures.xls", sheet=1)
10 """)
11 pref = robjects.globalenv['pref']
12 print(pref)
excel、はあくまでも例。「R にしかこの便利ライブラリがない」みたいなことって、たぶんないことはないだろうと思うんだよね。そういう時に、こういう逃げ道があるのはまぁ悪くないかもしれないなと。
にしてもだ。やっぱ日付型に関してはとても気になる。なんかねぇ、出来そうで出来ないんだこれ。
3つめはついでの話。
YAML の話を書いた際に触れた StackOverflow’s Developper Survey、そこでは Ruby に着目したけれど、R についてもみておくといいかもしれない。
Loved, Dreaded, Wanted どれをとってみても「R きゃーすてきー」という熱狂の片鱗は見当たらない、というのが一点、もう一点は、このランキングに現れるほど非常に広く使われている、というのが二点目。
こういう、属してきたグループによって知ってる知らないがはっきり分かれるものってのは、「広く使われてる」と言ってみたところで人によってはなかなか信じにくいものである可能性はある。少なくとも「Excel なら知ってる!」という人物が R を知ってる可能性は、たしかにゼロに近いかもしれない。けれど。ほんとにね、書店行ってみるといいと思うよ、ワタシが言ってる意味、わかると思う。専門書が強いところがいい。東京ならOAZO丸善や八重洲ブックセンター、地方都市でもJUNK堂なんかは割とあるだろう。そうした書店で、あえて「コンピュータ関連」以外の専門書の棚を眺めてみ。びっくりするくらい R の本が多い、しかも意外な場所に。(逆に言えば専門書をほとんど置かない書店では、下手すれば一冊も見つからないだろうね。)
教育機関(特に大学)においてこれが重視され、それゆえに R 関係の書籍に需要があり、ゆえにこれを学習する者が非常に多い一方で、利用者自身は R をそれほど愛していない、ということにはなるわけだが、まぁなんというか R 自身の問題というよりは、やはりライバルとなりうる python が強過ぎるということなのかもしらんね。(個人的には「ライバル? どっちも使えばよくね?」と思うけど。)
Fortran がまさにそうだったのでわかるのだが、「R の人気がなくなってきている」ことが今すぐその価値を失うことを意味するかというのは、これは間違いなく No で、確実に「R で書かれた重要な資産」というものは重視され続けるはず、何年も何十年も。そういう「レガシー活用」という見方で pyr2 をみるという考え方もあるかもしれないね。