「Windows 奈良では2」。
個人ユースには mecab-ipadic-neologd がツーマッチだ、ということのみならず、仮に「正式な使い方でちゃんと使いたい」と願っても、Windows の場合はヘビィ過ぎる。(というか 15GB 必要です、にはビビってみよう。)
うーん、と思っていたのだが、「#研究結果の評価や再現などに使いたい場合」から凍結済み辞書(のもと)が入手出来ることがわかり、これ幸い、と。
mecab-ipadic-neologd-0.0.6.tar.gz をダウンロードしてきて開いてみたら、どうやら「misc/patch」「diff」の部分が目的のもののようだ:
1 [me@host: ~]$ cd mecab-ipadic-neologd-0.0.6
2 [me@host: mecab-ipadic-neologd-0.0.6]$ ls -1 diff
3 new_entries_from_20150324_until_20150623.tsv.xz
4 new_entries_from_20150623_until_head.tsv.gz
5 [me@host: mecab-ipadic-neologd-0.0.6]$ ls -1 misc/patch
6 Noun.adverbal.csv.20160421.diff
7 Noun.csv.20160404.diff
8 Noun.csv.20160421.diff
9 Noun.csv.20160923.diff
10 Noun.csv.20170317.diff
11 Noun.demonst.csv.20170228.diff
12 Noun.name.csv.20150905.diff
13 Noun.name.csv.20160421.diff
14 Noun.name.csv.20160923.diff
15 Noun.name.csv.20161005.diff
16 Noun.name.csv.20170317.diff
17 Noun.number.csv.20160421.diff
18 Noun.org.csv.20160421.diff
19 Noun.org.csv.20160923.diff
20 Noun.org.csv.20161005.diff
21 Noun.others.csv.20160421.diff
22 Noun.place.csv.20150609.diff
23 Noun.place.csv.20160421.diff
24 Noun.place.csv.20160923.diff
25 Noun.place.csv.20161005.diff
26 Noun.proper.csv.20160421.diff
27 Noun.proper.csv.20160519.diff
28 Noun.proper.csv.20160923.diff
29 Noun.proper.csv.20161005.diff
30 Noun.verbal.csv.20150813.diff
31 Noun.verbal.csv.20160421.diff
32 Noun.verbal.csv.20160923.diff
33 Prefix.csv.20160421.diff
34 Suffix.csv.20160421.diff
35 Suffix.csv.20161027.diff
36 Symbol.csv.20160421.diff
37 Verb.csv.20150609.diff
*.diff はほんとに diff だね。もとの ipadic に対する差分になってる。utf-8 なのはありがたいかな。new_entries_from_ のほうは観察してもよくわかんない。ひとまず *.diff のほうだけ考えてみるとするか。
考えねばならんのは、「ワタシはシステム辞書そのものを更新したいのであろうか、ユーザ辞書として追加すれば十分なのか」の二択から、なのだが、当然「パッチがあたるんであれば、前者の方が楽」。後者を採用しようとする際に問題なのが、mecab-ipadic-neologd は新語追加のみならず、オリジナル IPA 辞書の「変更」も対象にしていること。つまり:
1 --- ./Noun.adverbal.csv.org 2016-04-01 00:00:52.871325278 +0900
2 +++ ./Noun.adverbal.csv 2016-04-21 15:21:30.424472898 +0900
3 @@ -5,7 +5,8 @@
4 いつか,1314,1314,5896,名詞,副詞可能,*,*,*,*,いつか,イツカ,イツカ
5 近頃,1314,1314,5337,名詞,副詞可能,*,*,*,*,近頃,チカゴロ,チカゴロ
6 行く先,1314,1314,5561,名詞,副詞可能,*,*,*,*,行く先,ユクサキ,ユクサキ
7 -3月,1314,1314,2728,名詞,副詞可能,*,*,*,*,3月,サンガツ,サンガツ
8 +3月,1314,1314,2728,名詞,副詞可能,*,*,*,*,3月,サンガツ,サンガツ
9 +3月,1314,1314,2728,名詞,副詞可能,*,*,*,*,3月,サンガツ,サンガツ
10 再来年,1314,1314,5101,名詞,副詞可能,*,*,*,*,再来年,サライネン,サライネン
11 すべて,1314,1314,4851,名詞,副詞可能,*,*,*,*,すべて,スベテ,スベテ
12 等々,1314,1314,5125,名詞,副詞可能,*,*,*,*,等々,トウトウ,トートー
13 ...
この「3月」の更新の扱いは忘れるしかないということになる。(というか上書き追加が辞書利用の優先度としてどうなるかの話。)
とりあえず、「システム辞書にパッチをあてて利用する」のは今回はやめておき、「あくまでも追加のユーザ辞書だよありがてー」に留める利用で考えてみることにする。
まぁ話はめちゃくちゃ簡単で、*.diff から「^+」だけ抜き出せばいいわけだよ、「更新」を気にしないのであれば。この作業だけなら Python みたいな高級言語はお呼びじゃない:
1 #! /bin/sh
2 mkdir from_neologd 2> /dev/null
3
4 for i in mecab-ipadic-neologd-0.0.6/misc/patch/*.diff ; do
5 bn=`basename $i .diff`
6 sed '1,2d' $i | grep '^+' | sed 's@^.@@' > from_neologd/${bn}
7 done
このスクリプトで「from_neologd」に「Noun.adverbal.csv.20160421」などが作られる、と。エントリ削除だけの差分もあるみたいね。なのでサイズゼロのものが出来ちゃうが、それはまぁ手で消すってことで。
で、作られたものは、 mecab-dict-index がそのまま解読出来る csv なので、ワタシの my-mecab-userdict-build.py は本来お呼びじゃないんだけど、実はこっそり mecab-dict-index がそのまま解読出来る csv もそのまま扱えるようにしてあり、そして「単独の辞書にマージ (--merge-all)」出来るようにしてあるんで、そうしちゃおうかと:
1 [me@host: ~]$ cd from_neologd
2 [me@host: from_neologd]$ my-mecab-userdict-build.py *.csv.* \
3 > --merge-all=from_neologd_0.0.6
4 INFO:root:processing input 'Noun.adverbal.csv.20160421'
5 INFO:root:processing input 'Noun.csv.20160404'
6 INFO:root:processing input 'Noun.csv.20160421'
7 INFO:root:processing input 'Noun.csv.20160923'
8 INFO:root:processing input 'Noun.csv.20170317'
9 INFO:root:processing input 'Noun.demonst.csv.20170228'
10 INFO:root:processing input 'Noun.name.csv.20150905'
11 INFO:root:processing input 'Noun.name.csv.20160421'
12 INFO:root:processing input 'Noun.name.csv.20160923'
13 INFO:root:processing input 'Noun.name.csv.20161005'
14 INFO:root:processing input 'Noun.name.csv.20170317'
15 INFO:root:processing input 'Noun.number.csv.20160421'
16 INFO:root:processing input 'Noun.org.csv.20160421'
17 INFO:root:processing input 'Noun.org.csv.20160923'
18 INFO:root:processing input 'Noun.org.csv.20161005'
19 INFO:root:processing input 'Noun.others.csv.20160421'
20 INFO:root:processing input 'Noun.place.csv.20150609'
21 INFO:root:processing input 'Noun.place.csv.20160421'
22 INFO:root:processing input 'Noun.place.csv.20160923'
23 INFO:root:processing input 'Noun.place.csv.20161005'
24 INFO:root:processing input 'Noun.proper.csv.20160421'
25 INFO:root:processing input 'Noun.proper.csv.20160923'
26 INFO:root:processing input 'Noun.proper.csv.20161005'
27 INFO:root:processing input 'Noun.verbal.csv.20160421'
28 INFO:root:processing input 'Noun.verbal.csv.20160923'
29 INFO:root:processing input 'Prefix.csv.20160421'
30 INFO:root:processing input 'Suffix.csv.20160421'
31 INFO:root:processing input 'Suffix.csv.20161027'
32 INFO:root:processing input 'Symbol.csv.20160421'
33 INFO:root:processing input 'Verb.csv.20150609'
34 reading C:\Users\HHSPRI~1\AppData\Local\Temp\from_neologd_0.0.6_0.csv ... 12751
35 emitting double-array: 100% |###########################################|
36
37 done!
38 INFO:root:dictionary 'from_neologd_0.0.6.dic' was created.
まぁ正規の neologd の使い方よりは精度は落ちるにせよ、「マシにはなる」んだろうなと期待し。そしてさすがにこれは「AV 女優辞書」みたいな「有効にしたくない」場面は少なかろうと言うことで、いつも使うユーザ辞書にしてしまおうかと。
前回は「ユーザ固有 rc」の件にしか触れなかったが、「おれんちグローバル」てことにしたいから、システムの方に置いてしまおう、ということであれば、(ワタシの Windows の場合は)c:/Program Files (x86)/MeCab/etc/mecabrc を直接編集してしまおうと。どうせ Windows で「シングルユーザなんだから」と無頓着に「作った辞書も c:/Program Files (x86)/MeCab/dic に置いちまえ、と。
して変更した mecabrc:
1 ;
2 ; Configuration file of MeCab
3 ;
4 ; $Id: mecabrc.in,v 1.3 2006/05/29 15:36:08 taku-ku Exp $;
5 ;
6 dicdir = $(rcpath)\..\dic\ipadic
7
8 userdic = c:/Program Files (x86)/MeCab/dic/from_neologd_0.0.6.dic
9
10 ; output-format-type = wakati
11 ; input-buffer-size = 8192
12
13 ; node-format = %m\n
14 ; bos-format = %S\n
15 ; eos-format = EOS\n
そこそこの追加になるんだけれど、どの程度効果が出てるかはまだ良くわかんない。とりあえず良くなってると信じてみる。
そして…半日後くらい。
ちょいちょい結果を見てるんだけど、正直「あんましよろしくない部分がある」。これは neologd 作者の考え方によるもので、個人的には「MeCab の真意に反してる」か、もしくは「人によっては目的に合わない」と思う。以下キャプチャは、右が neologd なし、左が neologd あり:
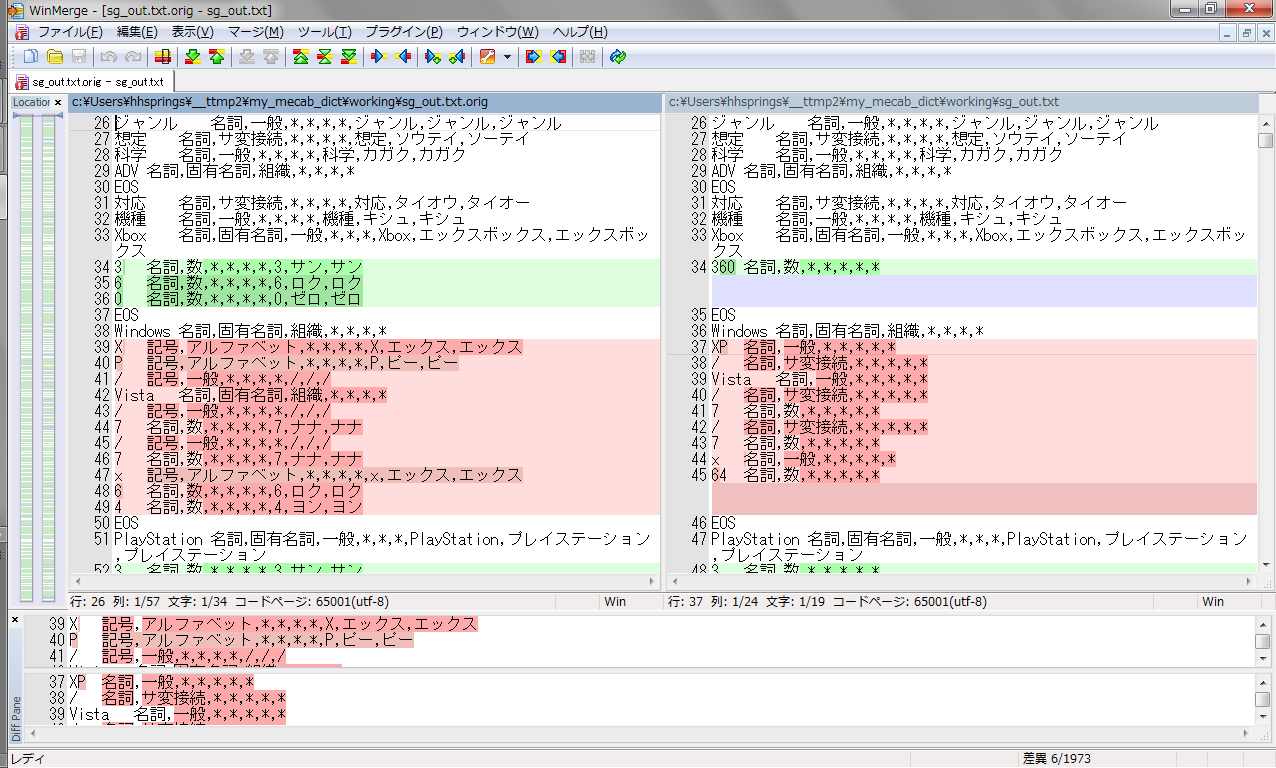
「読み」重視、つまり読み上げが目的の場合は neologd の辞書も悪くないんだけれど、「XP」を「アルファベット二つ」としてしまうのは非常に困る。この解析済み結果からはもはや入力が「XP」だったのか「X P」だったのかの判別が出来ない。「MeCab の真意に反してる」というのはつまり、「本来 MeCab って、ワードに区切るためのもの(形態要素の解析をするもの)でしょ、「アルファベット」って形態要素なのかい?」てことなのだが、「読み上げに使う」のもひとつの使い方だから…、まぁなんとも言えないかな。
この辞書が自分の目的に合う場合は別にいいんだよ。けどたぶん 6:4 か 7:3 くらいの比率で「これはオレには合わん」のではないかと思う。読み上げ目的に MeCab を使いたいユーザが5割を超えるとは到底思えない。
あとこれはほとんどご愛嬌かなぁ:
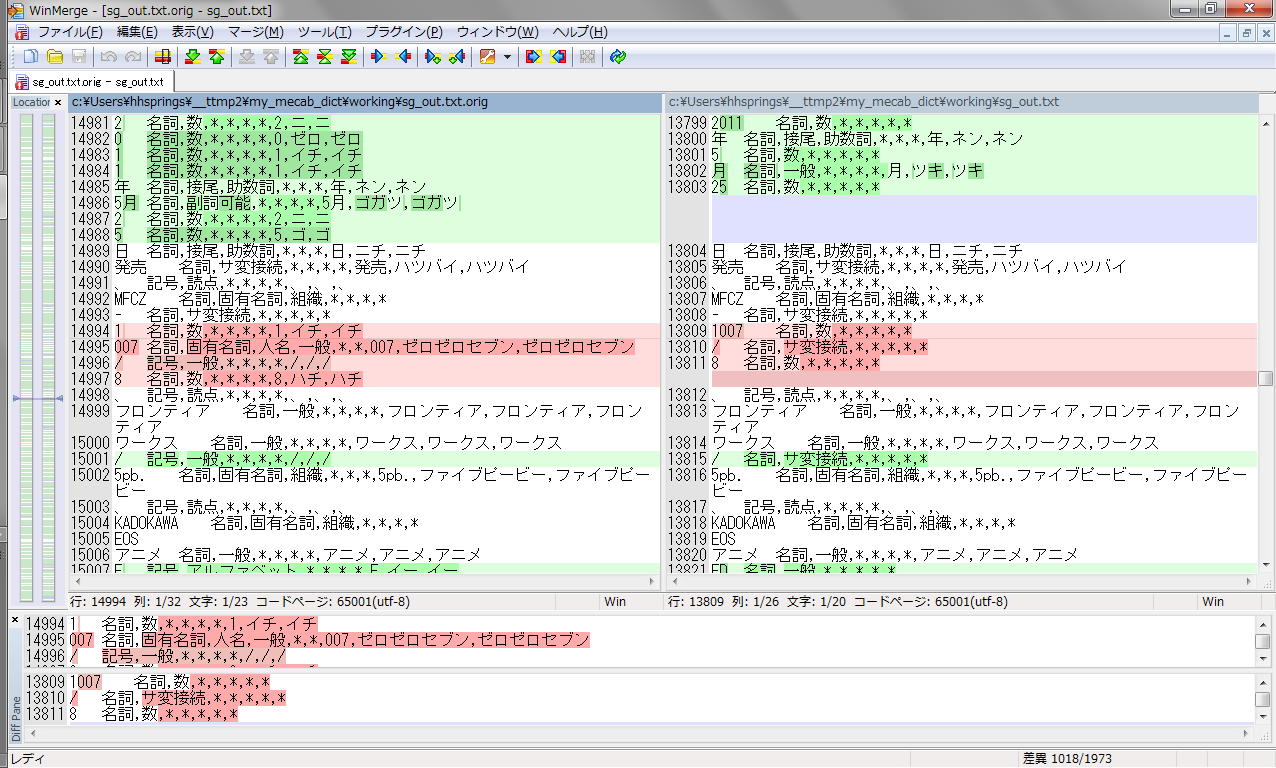
いずれにしてもこの子、盲目的に信じたらダメだわ。取捨選択すべき。少なくとも Symbol.csv、Noun.number.csv は使わないか、問題のものを取り除くべき(読み上げ目的の人以外は)。そして「システムグローバルな mecabrc から使うのはよしといた方がいい」。













