16進数ってバイト数嵩んでやぁねぇ、式。
UUID て、ビット数が多い(128bit)わけで、文字列表現としては16進数表記ですら32バイトを使ってしまうわけで。
随分前から「base64的なエンコードを標準にすりゃいいのに」と思ってた。
ら。あ、既に結構標準なのね…。このエントリの見出しはね、例によって StackOverflow のタイトル「Convert UUID 32-character hex string into a “YouTube-style” short id and back」からパクってます。つまり、「YouTubeのメディアID」もそうなのか、てことな。
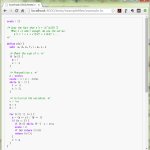
1 >>> import base64
2 >>> import uuid
3 >>> raw_id = uuid.uuid4()
4 >>> raw_id
5 UUID('2c90d983-0c97-44b0-b3a9-1d662e7b57a3')
6 >>> id = base64.urlsafe_b64encode(raw_id.bytes).rstrip('=')
7 >>> id
8 'LJDZgwyXRLCzqR1mLntXow'
9 >>> uuid.UUID(bytes=base64.urlsafe_b64decode((id + '==').replace('_', '/')))
10 UUID('2c90d983-0c97-44b0-b3a9-1d662e7b57a3')
11 >>>
かなりコンパクトになりますわな。