今更…。
自力でやると結構煩雑。頭いたくなるよ。
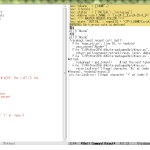
前から近いニーズのことやってた気がしてたんだけど、意外と必要じゃなかったみたい。改めて考えてみたら、Python の場合は difflib のおかげで一撃なのであった:
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3
4 from difflib import SequenceMatcher
5
6
7 def common_seq(lhs, rhs):
8 """
9 >>> print(common_seq("ABChhh", "XYZkkk"))
10 <BLANKLINE>
11 >>> print(common_seq("ABChhh", "ABCkkk"))
12 ABC
13 >>> print(common_seq("zzABChhh", "ABCkkk"))
14 ABC
15 >>> print(common_seq("ABChhh", "yyABCkkk"))
16 ABC
17 >>> print(common_seq("zzABChhh", "yyABCkkk"))
18 ABC
19 >>> print(common_seq("uvwxABChhh", "yzABCkkk"))
20 ABC
21 >>> print(common_seq("uvwABChhh", "xyzABCkkk"))
22 ABC
23 """
24 sm = SequenceMatcher(a=lhs, b=rhs)
25 first_match = sm.get_matching_blocks()[0]
26 span = slice(first_match.a, first_match.a + first_match.size)
27 return lhs[span]
28
29
30 if __name__ == '__main__':
31 import doctest
32 doctest.testmod()
first_match と言ってることからわかると思うけど、一致部分全部を拾い上げることも出来る。
なお、difflib なので、例えば空白の無視とかそういったことも出来る、けど今回はやらない。あと difflib が文字列前提なので、文字列以外に適用したくなったらどうしようかと思うんだけど、今はまぁいいや。
追記。
つーか「一致部分全部を拾い上げる」方を標準に考えたほうが便利よね:
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3
4 from difflib import SequenceMatcher
5
6
7 def common_seq(lhs, rhs):
8 r"""
9 >>> print("\n".join(common_seq("ABChhh", "XYZkkk")))
10 <BLANKLINE>
11 >>> print("\n".join(common_seq("ABChhh", "ABCkkk")))
12 ABC
13 >>> print("\n".join(common_seq("zzABChhh", "ABCkkk")))
14 ABC
15 >>> print("\n".join(common_seq("ABChhh", "yyABCkkk")))
16 ABC
17 >>> print("\n".join(common_seq("zzABChhh", "yyABCkkk")))
18 ABC
19 >>> print("\n".join(common_seq("uvwxABChhh", "yzABCkkk")))
20 ABC
21 >>> print("\n".join(common_seq("uvwABChhh", "xyzABCkkk")))
22 ABC
23 """
24 sm = SequenceMatcher(a=lhs, b=rhs)
25 return [lhs[slice(m.a, m.a + m.size)]
26 for m in sm.get_matching_blocks() if m.size]
27
28
29 if __name__ == '__main__':
30 import doctest
31 doctest.testmod()