EAN は UPC、ISBN、GTIN と読み替えてもらって構わない。
「kivyLauncher + zxing でバーコードスキャン」の動機はもともとは「あたし、この DVD 既に買ったかしら?」の管理がしたかっただけ、なのだけれども、せっかく EAN が取れてるんだから、ちょっとは情報をくっつけて管理したいなぁ、と思ったわけですな。
ただね…。
調べてみてもらえればわかるんだけれども、EAN lookup だとかそういったものって、要するに大規模なデータベースを要する分野だもんで、色んなサービスあるけどまぁこんなね:
- xmlやjsonで受け取れるステキなサービスは大抵有償あるいはアカウント必要
- 日本語がダメなのもある
- データベースが小さすぎるものも多い
ワタシのニーズ的に、リッチな情報が欲しいってほどのもんでもなくて、せいぜいタイトルがわかるくらいでもいいわけなんで、とすれば「有償」やら「アカウントが必要」はちぃとヘビィでもあるし。
でな。普通の検索エンジンで以下画像のような検索でもいいかなぁと:
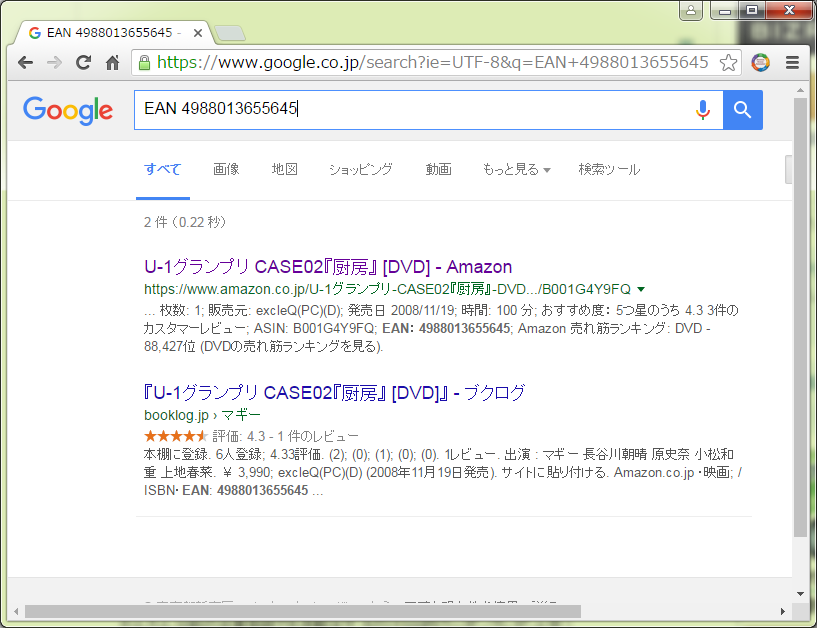
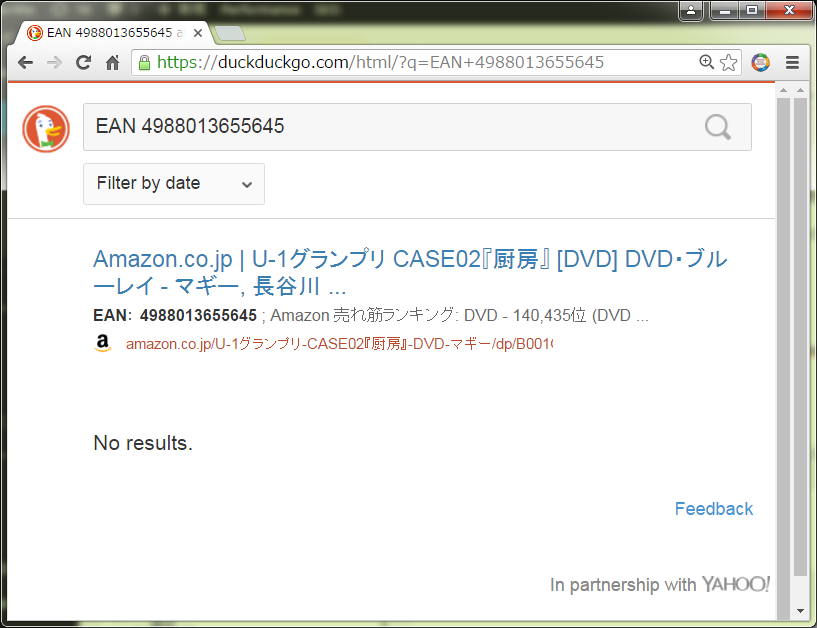
つまりちゃんと「EAN」を検索キーワードに含めてあげれば、かなり期待通りの一覧になるわけな。
「普通の検索エンジン」といってもここでも当然「API を使いたい」てのはあるんだけれど、
- 知ってる人は知っている、Google の検索 API は有償(無償版はあるが制限多いしアカウント必要)。
- DuckDuckGo にはInstant Answer APIなんてのがあるんだけれど、これは json で返してくれるうえに無償で使えるステキなものなのだが…。「Instant」に注目。
This API does not include all of our links, however. That is, it is not a full search results API or a way to get DuckDuckGo results into your applications beyond our instant answers. Because of the way we generate our search results, we unfortunately do not have the rights to fully syndicate our results. For the same reason, we cannot allow framing our results without our branding. Please see our partnerships page for more info on guidelines and getting in touch with us.
wikipedia からの検索をあてにするくらいなら使えるんだけれど、EAN の検索は必ずゼロ件になる。ので全然使えない、今の場合。
というわけで、機械処理には適さない汚れた html を受け取ってパースする、って昔ながらのやり方しかなさそうだな、ということで。
「kivyLauncher アプリ内で使う」ことを踏まえて素の python で書いた。「kivyLauncher アプリ内で使う」がネックでな。BeautifulSoup みたいなステキなもんは、素の kivyLauncherでは使えない。ので、ダルいが HTMLParser で書いた:
1 # -*- coding: utf-8 -*-
2 import urllib
3 import urllib2
4 from HTMLParser import HTMLParser
5
6 # DuckDuckGo 用。
7 class _DuckDuckGoHtmlResExtractor(HTMLParser):
8
9 def __init__(self):
10 HTMLParser.__init__(self)
11 self.recording = 0
12 self.data = []
13
14 def handle_starttag(self, tag, attrs):
15 if tag == 'a':
16 d = dict(attrs)
17 if 'class' in d and d['class'] == 'result__a':
18 self.recording = 1
19 self.data.append({"href": d['href']})
20
21 def handle_endtag(self, tag):
22 if tag == 'a':
23 self.recording = 0
24
25 def handle_data(self, data):
26 if self.recording:
27 self.data[-1]["data"] = data.strip().decode("utf-8")
28
29 # Google 用。
30 class _GoogleHtmlResExtractor(HTMLParser):
31
32 def __init__(self):
33 HTMLParser.__init__(self)
34 self._states = 0
35 self.data = []
36
37 def handle_starttag(self, tag, attrs):
38 # user-agent ごとに構造が全然違う?
39
40 d = dict(attrs)
41 if tag == 'p':
42 # chrome のブラウザでみてるとここは
43 # tag == 'h3' and 'class' in d and d['class'] == 'r'
44 # で判断出来るのだが…?
45 self._states = 1
46 elif tag == 'a' and self._states == 1:
47 if d['href'] != '/':
48 # "https://www.google.co.jp/url?q=" という問い合わせ
49 # を間に挟んでくれちゃうのね、google さんは。
50 self.data.append({
51 "href": "https://www.google.co.jp" + d['href']
52 })
53 self._states = 2
54
55 def handle_endtag(self, tag):
56 if tag == 'a':
57 self._states = 0
58
59 def handle_data(self, data):
60 if self._states == 2:
61 self.data[-1]["data"] = data.strip().decode("utf-8")
62 #
63 _MAPPING = {
64 "duckduckgo":
65 ("https://duckduckgo.com/html/", _DuckDuckGoHtmlResExtractor),
66 "google":
67 ("https://www.google.co.jp/search", _GoogleHtmlResExtractor),
68 }
69
70 #
71 def query(ean, type_="EAN", engine="google"): #engine="duckduckgo"
72 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
73
74 # 3点。
75 # 1. Googleの場合 User Agent 必須 (ないと 403)
76 # 2. Googleでは POST は NG、必ず GET でないとダメ…らしい
77 # 3. DuckDuckGo はクエリを繰り返してると 403
78 # (数分ほっとけば再開する。これはブラウザからも起こる。)
79 url = _MAPPING[engine][0]
80 data = urllib.urlencode({
81 "q": " ".join([type_, ean]),
82 })
83 opener = urllib2.build_opener()
84 opener.addheaders = [('User-Agent', user_agent)]
85 res = opener.open(url + "?" + data)
86 html = res.read()
87
88 parser = _MAPPING[engine][1]()
89 parser.feed(html)
90
91 return parser.data
コメントからわかる通り、403 に少々苦労した。
1 for d in query("4988013655645", engine="google"):
2 #print(d['data'].encode("cp932"))
3 print(d)
みたいに使う。この場合、本日実行した結果はこんな:
1 {'href': u'https://www.google.co.jp/url?q=https://www.amazon.co.jp/U-1%25E3%2582%25B0%25E3%2583%25A9%25E3%2583%25B3%25E3%2583%2597%25E3%2583%25AA-CASE02%25E3%2580%258E%25E5%258E%25A8%25E6%2588%25BF%25E3%2580%258F-DVD-%25E3%2583%259E%25E3%2582%25AE%25E3%2583%25BC/dp/B001G4Y9FQ&sa=U&ved=0ahUKEwiR5r2VxJfOAhWGmZQKHa-bCswQFggGMAA&usg=AFQjCNFnt55uCQXH1df-td01GQoRjCyy9Q', 'data': u'U-1\u30b0\u30e9\u30f3\u30d7\u30ea CASE02\u300e\u53a8\u623f\u300f [DVD] - Amazon'}
2 {'href': u'https://www.google.co.jp/url?q=http://booklog.jp/users/chanpei/archives/B001G4Y9FQ&sa=U&ved=0ahUKEwiR5r2VxJfOAhWGmZQKHa-bCswQFggIMAE&usg=AFQjCNHgQQxonZCTDy8DrTCuUp4c9gzpeA', 'data': u'\u300eU-1\u30b0\u30e9\u30f3\u30d7\u30ea CASE02\u300e\u53a8\u623f\u300f [DVD]\u300f - \u30d6\u30af\u30ed\u30b0'}
そう、アタシはほんとに検索結果のタイトルと url だけで十分なのでこれしか取ってない。頑張ればもう少しだけ情報取れるけどね。
まぁこんなもんはきっとイタチごっこになるんだろうなぁと。一年後にも同じコードで動く保障はまったくない。けど一応今日の用は足せる。
2016-8-6 追記:
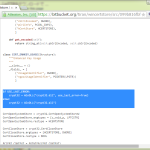
バグってた。何度も呼び出すと以前の呼び出し結果への追記になっちゃう。コード中でハイライトした deepcopy と parser.data = [] が本日変更した部分。
2016-8-7 追記:
「バグってた」の措置は parser のインスタンスを維持したままだったから。改めて直した。