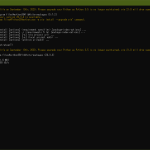
Windows MSYS シェルスクリプトとして書いた CGI を Python の CGIHTTPServer でテストなんてやったけれど。
Python 2.7 では Windows 固有の問題があったが、3.x でデグレードしてることに気付いてしまった。また、2.7 と共通の問題もあることがわかった。
まず 2.7 と共通の問題。Accept-Encoding、Accept-Language、Accept-Charset を通せない。これは 2.7 からで、3.x でも踏襲されてる。んで、これを対応したろうか、と思って 2.7 で対応してみて(例によって公式のものを直接書き換えて)よしよしと思って、3.x でもやろうとして…。
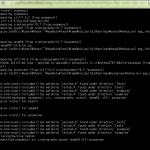
3.x では Accept も通せなくなってる。なんだこれはと思って解析してたら、2.7 から 3.x に「リファイン」する際のミスが紛れ込んでいた…。機能間の連携の不整合が起こってしまっている。該当するのは http/server.py の run_cgi 内のこの部分:
1113 accept = []
1114 for line in self.headers.getallmatchingheaders('accept'):
1115 if line[:1] in "\t\n\r ":
1116 accept.append(line.strip())
1117 else:
1118 accept = accept + line[7:].split(',')
1119 env['HTTP_ACCEPT'] = ','.join(accept)
と http/client.py のここ:
219 class HTTPMessage(email.message.Message):
220 # XXX The only usage of this method is in
221 # http.server.CGIHTTPRequestHandler. Maybe move the code there so
222 # that it doesn't need to be part of the public API. The API has
223 # never been defined so this could cause backwards compatibility
224 # issues.
225
226 def getallmatchingheaders(self, name):
227 """Find all header lines matching a given header name.
228
229 Look through the list of headers and find all lines matching a given
230 header name (and their continuation lines). A list of the lines is
231 returned, without interpretation. If the header does not occur, an
232 empty list is returned. If the header occurs multiple times, all
233 occurrences are returned. Case is not important in the header name.
234
235 """
236 #...省略...
どう間違っているかはソースコードを読めばわかるので省略するけれども、とにかく「更新された新しいモジュール・クラス」から「取り残された」ことが原因のインターフェイスミスマッチ。
で、これはもう報告するしかないなぁ、と腹を括って、issue に挙げようとした。あ、一ヶ月前に2009年に挙がってら。
- #5054 CGIHTTPRequestHandler.run_cgi() HTTP_ACCEPT improperly parsed
- #5053 http.client.HTTPMessage.getallmatchingheaders() always returns []
これは次の版では直るかもしれない、と思うのだが、なにせインターフェイスのミスマッチ問題なので、上記2つの議論はなんか混乱してる気がしますわ。まず、ツッコミも入っているけどこれ:
line[:1] in ‘\t\n\r’ clearly was meant to to be line[-1].
は clearly、じゃないし、meant to be じゃない。line[:1] で正しい。継続行の処理だから、これ。
需要が減ってる CGI ものなので、真剣度は少なめな気がするし、まぁまぁ繊細な設計問題ではあるので、即座に修正される…というほどでもないと思うけれど、次版(きっと半年~1年後)では修正されてるんじゃないかな。
2009年に挙がったものが、一ヶ月前に最終更新の issue でレビューステータスにはなっている。次版に取り込まれるかどうかはよくわからない。ひとまずパッチとしては#5054の方に添付されてるcgi-accept.patchで良いと思う。(get_all の中までみてないので、継続行の扱いがどうなってくれたのかは気にはなるが、きっと大丈夫であろう。)なお、Accept-Encoding、Accept-Language、Accept-Charset の追加はcgi-accept.patchの流れで追加出来る。こんな感じ:
1 accept = self.headers.get_all('accept', ())
2 env['HTTP_ACCEPT'] = ','.join(accept)
3 # ---------------------------------------- ADD BEGIN
4 accept_encoding = self.headers.get_all('accept-encoding', ())
5 env['HTTP_ACCEPT_ENCODING'] = ','.join(accept_encoding)
6
7 accept_charset = self.headers.get_all('accept-charset', ())
8 env['HTTP_ACCEPT_CHARSET'] = ','.join(accept_charset)
9 # ---------------------------------------- ADD END
これの成果はhttps://bitbucket.org/hhsprings/pygmentize_cgi/src/testにあります。