最初から「webkit timestamp」とわかって調べ始めたわけではない。(ついでに「webkit」と思ったのは stackoverflow がそう言ってたというだけ。)
結構前に「Chrome のキャッシュ」の話を書いて、その「キャッシュ」の話に関しては進展はなくその時書いた通りのまま、なんだけれど、キャッシュではなくて「訪問履歴 (History)」だと話が別で…、「chrome://history」がね、まぁ…。
今の私の場合、urls2htmlcal.py なんかで「カレンダと url の紐付け」なんて作業をしてると、:visited かどうか、てのが結構作業的に大事。「どこまで確認できたか」が「未訪問時のスタイル「青」と訪問済のスタイル「紫」」で識別出来るから。そして「未訪問扱いに戻したい」場合に「chrome://history」で消してあげると、ページの更新をすることなく即座に反映するわけ。だから「個々のサイト単位で一つ一つ」という、キャッシュとは違った細かな制御をしたい、というわけね。
けど…「chrome://history」、おそろしく使い勝手が悪い。ユーザインターフェイスとしては「ワースト」に属する部類のヒドいもの。まぁ Google が作る UI なんて全部そうなので驚きはしないけれども…。
そういうわけで、「Chrome のキャッシュ」での結論とは違って、「Chrome 自身以外での手段で何とかする術はありや、なしや」というのを知りたくなった、てのがまず発端。
「History」の実体は、「Chrome のキャッシュ」とほとんど同じ場所にある。名前はそのまんま「History」。
キャッシュの index は正体不明だったが、この History はテキストエディタなどで開いてみればすぐに sqlite であることがわかる。ゆえに SQLiteStudio で見れるだろう…、と思ったら、SQLiteStudio って、拡張子を見てる? History.db と名前を変えないと読んでくれなかった。
ともあれ、これで History データベースを読めるようになったのだけれど、「last_visit_time」など時刻形式がわからん、と。本日時点だと posixtime では「16~」となるはずだが「13~」で、桁数もかなり多いのでは、と。うーん、posixtime でないことだけはわかるが、これはなんだ。一つだけ対応関係をみるに、「13254742143349715 == “2021-01-10 17:49:03 +0900″」らしい(データベースの行に対応すると思われるアイテムを chrome://history でみればわかる)。
Epoch_(computing)から探り当てるか、と思ってたが、いつも通り stackoverflow に答えを見つけた:
1 # -*- coding: utf-8 -*-
2 from datetime import timedelta
3 from datetime import datetime
4
5 #
6 posix_epoch = datetime.utcfromtimestamp(0)
7 webkit_epoch = datetime(1601, 1, 1)
8 unit = 10**6 # 10^-6 == micro
9 #
10 ques = 13254742143349715
11 print(
12 datetime.fromtimestamp(
13 int(ques / unit) - (posix_epoch - webkit_epoch).total_seconds()))
14 # -> 2021-01-10 17:49:03
1601年1月1日って見覚えがあるようなないようなだな、と思ったが「NTFS, COBOL, Win32/Win64 (NT time epoch)」。あら、そうでしたっけか。
ひとまず、見出しにした「webkit timestamp 13254742143349715 == posix timestamp ???」という本題についてはこれだけ。
して、ワタシ的の「ゴール」の方は、完遂するかどうかわかんない。少なくとも「あぁめんどい」と思ってる日常が少しあるのは確かだけれど、そこまで真剣にやる必要があるようなものでもないわけで。
とりあえずは「SQLiteStudio でリネームしないと扱えない」であるとか、「Chrome 動作中に編集して良いのやらどうなのやら」だとか、あるいは(UI から想像出来るよりは)それなりには複雑な構造なので、「壊さないように」のと「壊しちゃったらすぐに戻せるように」もそこそこ繊細でもあるので、やる場合はちょっと強めの本気スイッチ入れなきゃいけないの。
ひとまず「手始め」としてはまずはこれ:
1 import os
2 #import io
3 import sys
4 from datetime import timedelta
5 from datetime import datetime
6 import sqlite3
7
8
9 _adj_pt2wt = (
10 datetime.utcfromtimestamp(0) - datetime(1601, 1, 1)).total_seconds()
11
12
13 def _parse_webkittimestamp(tss):
14 return datetime.fromtimestamp(int(int(tss) / 10**6) - _adj_pt2wt)
15
16
17 # TABLES:
18 # meta
19 # + key
20 # + value
21 # urls
22 # + id
23 # + url
24 # + title
25 # + visit_count
26 # + typed_count
27 # + last_visit_time
28 # + hidden
29 # visits
30 # + id
31 # + url
32 # + visit_time
33 # + from_visit
34 # + transition
35 # + segment_id
36 # + visit_duration
37 # + incremented_omnibox_typed_score
38 # + publicly_routable
39 # visit_source
40 # + id
41 # + source
42 # keyword_search_terms
43 # + keyword_id
44 # + url_id
45 # + term
46 # + normalized_term
47 # downloads
48 # + id
49 # + guid
50 # + current_path
51 # + target_path
52 # + start_time
53 # + received_bytes
54 # + total_bytes
55 # + state
56 # + danger_type
57 # + interrupt_reason
58 # + hash
59 # + end_time
60 # + opened
61 # + last_access_time
62 # + transient
63 # + referrer
64 # + site_url
65 # + tab_url
66 # + tab_referrer_url
67 # + http_method
68 # + by_ext_id
69 # + by_ext_name
70 # + etag
71 # + last_modified
72 # + mime_type
73 # + original_mime_type
74 # downloads_url_chains
75 # + id
76 # + chain_index
77 # + url
78 # downloads_slices
79 # + download_id
80 # + offset
81 # + received_bytes
82 # + finished
83 # segments
84 # + id
85 # + name
86 # + url_id
87 # segment_usage
88 # + id
89 # + segment_id
90 # + time_slot
91 # + visit_count
92 # typed_url_sync_metadata
93 # + storage_key
94 # + value
95
96
97 def main(db):
98 conn = sqlite3.connect(db)
99 try:
100 c = conn.cursor()
101 sql = """\
102 SELECT b.url, b.title, a.visit_time
103 FROM visits a INNER JOIN urls b ON (a.url = b.id) ORDER BY a.visit_time"""
104
105 for row in c.execute(sql):
106 dt = _parse_webkittimestamp(row[2])
107 print(row[:2], dt)
108 finally:
109 conn.close()
110
111
112 if __name__ == '__main__':
113 #_USERDATA_DEFAULT = "c:/Users/hhsprings/AppData/Local/Google/Chrome/User Data/Default"
114 #_HISTORY = os.path.join(_USERDATA_DEFAULT, "History")
115 main(sys.argv[1])
Chrome を開きっぱなしでも動かせるかどうかは場合によるっぽい。最初動かしたまま使えたのだが、ほとんど使えないみたい。「ロックされとるがな」と叱られる。てのがあるので、「使いやすい道具」にすぐにでも出来る、って確信が全く持てない。毎度 Chrome を閉じて使うツールなんぞ、さすがに使いたくない。
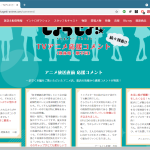
というわけで、「自分で作ろうとせずに、だれかが作ったものを探そう、extension にあるんでねーの?」と、 chrome history editor extension みたいな検索で、すぐにこの紹介サイトが見つかる。Recent History をお薦められた。
使い始めて早々に履歴検索で検索から戻ってこない事象に巡り合って、紹介を躊躇しかけたのだけれど、でもね、いや、これはかなり劇的に恐ろしく使いやすいわ。Chrome 組み込みの「chrome://history」がヒド過ぎるのでよほどのものでない限りはこれよりは相対的に普通は良いだろう、ということではなくて、いや、ちゃんと使いやすいよ。検索から返ってこないケースだって、タブを閉じればいいだけ。Chrome がハングアップするわけではなくて、extension の javascript が返ってこないだけだから。
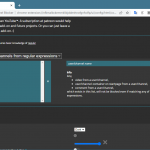
紹介サイトはメイン画面だけ見せてて、これが非常に優秀なんだけれど、実際これ:
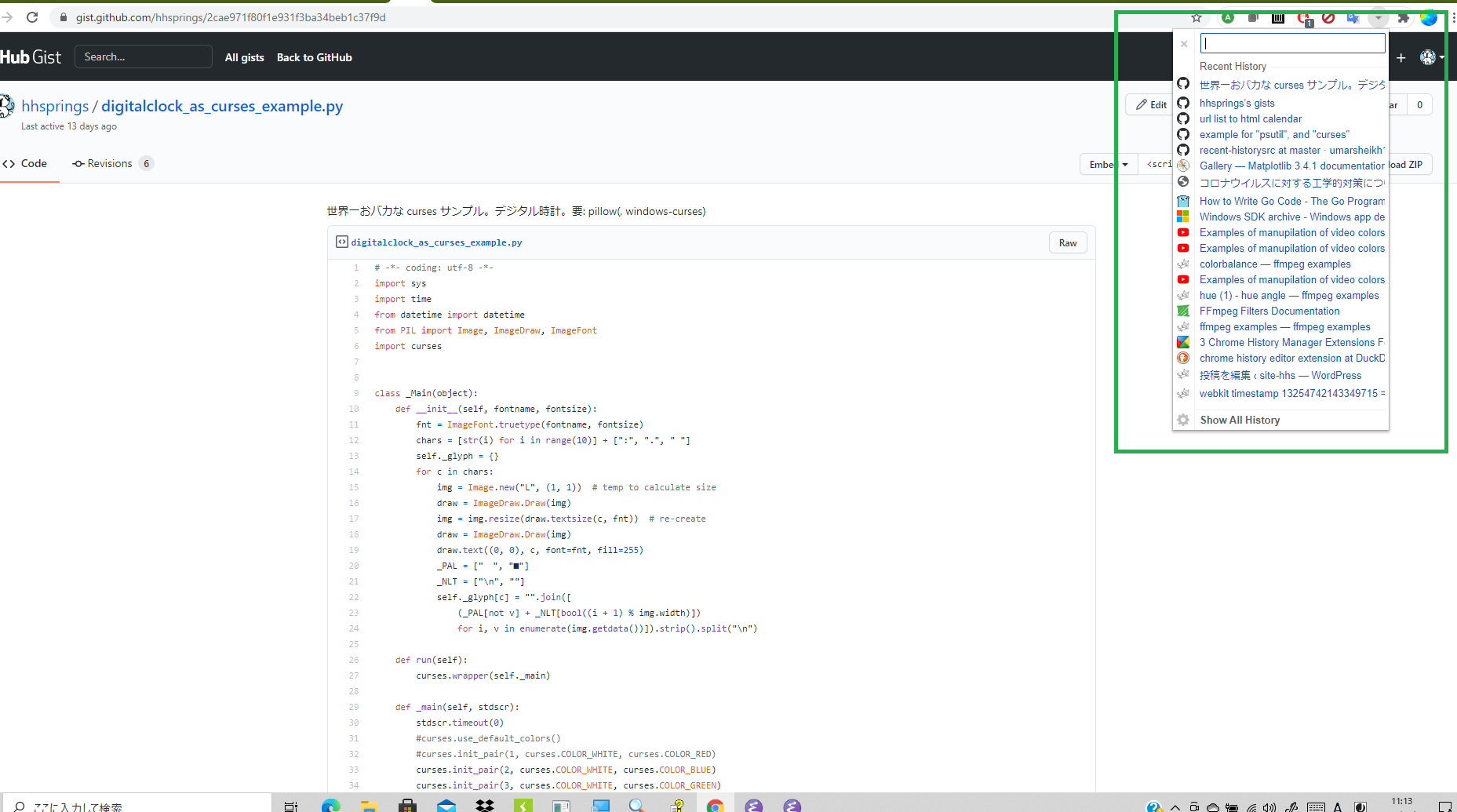
は、確かにメイン画面に比べて地味なんだけど、だけどこれだけでもかなりブラウズ生活が楽になる、と思わん?
あとついでに言えばこれ、OSS で GitHub で公開されてる。つまり何か欲しい機能があったり不満があった場合に、自分でコントリビュート出来る、てことでもあるし、そうでない場合でも、少なくとも「オレオレ Chrome extension を書く」参考にはなるだろう。
2021-05-29追記:
紹介した「Recent History」なのだが、Windows 再起動したタイミングで使えなくなってて、何かと思ったら Chrome から警告受けて、自動で disable にされてた。
この拡張機能は Chrome ウェブストアのポリシーに違反しています。
うぞーん。どうすりゃいいの、便利なのだがなぁ? とりあえずは強制的に再度 enable には出来るが…?