好きで PHP やってるわけじゃねー。
なんらかの理由で、そう、典型的には「TinyMCEなどのビジュアルエディタによる変換で」、HTMLエンティティへのエンコード済みテキストがあったとする:
1 <pre>
2 #include <iostream>
3 static const char* s = "abcde";
4
5 int main()
6 {
7 if (s[1] == 'b') {
8 std::cout << "It makes me huge frustration." << std::endl;
9 }
10 return 0;
11 }
12 </pre>
「ワタシがブラウザ」であるならば、こう表示するであろう:
1 #include <iostream>
2 static const char* s = "abcde";
3
4 int main()
5 {
6 if (s[1] == 'b') {
7 std::cout << "It makes me huge frustration." << std::endl;
8 }
9 return 0;
10 }
そう。ブラウザ相手に HTML エンティティが残っていても誰も困らない。これを適切な表示に読み替えるのはブラウザの責務だから。
だからといって html_entity_decode が「ブラウザ相手であればいい」で終わっちゃってどーすんのよ。
つまり。「ブラウザのような」処理を書く必要がある場合は、「ブラウザはこう解釈する」を模擬する必要がある。pygmentsにはさ、「ブラウザが表示してくれるであろうテキスト」ではなく、「書き手が意図したテキスト(すなわちブラウザでみたままのテキスト)」を渡さないと意味がないでしょう? つまりこの種の処理では、
1
も含め、全て対応する文字に変換しなければならない。
html_entity_decode のマニュアルにはさ、こんなことが書いてあるわけね:
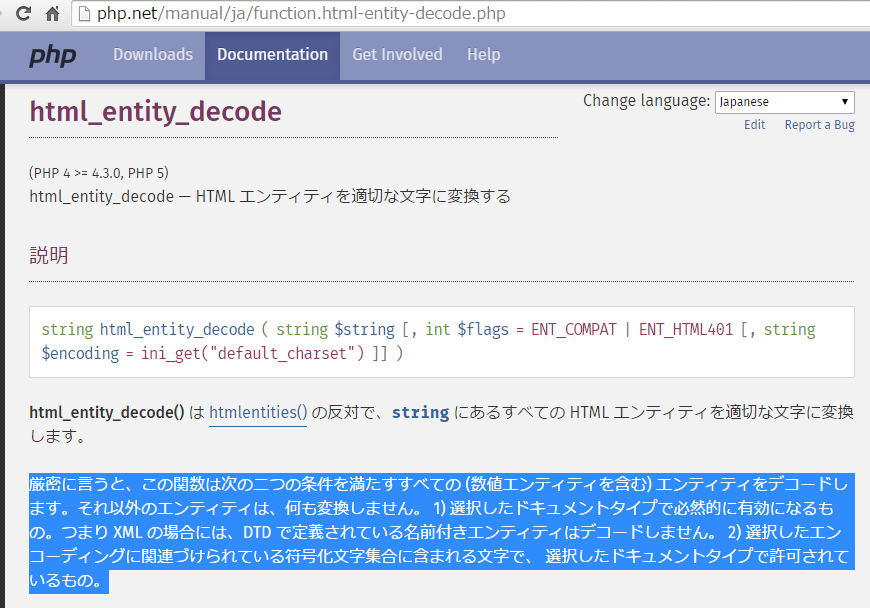
なんかね、この翻訳違和感あってさ、英文はこうね:
More precisely, this function decodes all the entities (including all numeric entities) that a) are necessarily valid for the chosen document type — i.e., for XML, this function does not decode named entities that might be defined in some DTD — and b) whose character or characters are in the coded character set associated with the chosen encoding and are permitted in the chosen document type. All other entities are left as is.
「that are necessarily valid for the chosen document type」って、「変換しないと不正になっちゃうもの(DTDに違反する)」ってことのような気がするのだが、だとしたら翻訳はヘンだ。アタシが読み間違えてる? (訳出としてはきっとこの場合「妥当であることが不可欠であるもの」てな感じ? と思うんだけどな。)
で。変換しない、とは書いてあるが、変換したい場合にどうすればいいのか、書いてないんだ、これが。HTML の場合は
1
2 <
3 &
4 >
などの名前付き実体参照が該当する。これを変換しない、という。もう一度言うけど、「ブラウザ相手でいい」ならこれでも良いのだ。けど相手はブラウザじゃない、場合にどうすりゃいいのだ。(言い換えれば、出力が HTML でない場合、ね。)
例によって答えは StackOverflow にあったんだけれど、その前に、答えを見つけた StackOverflow の該当ページのこれを引用しとく:
1 $HTML401NamedToNumeric = array(
2 ' ' => ' ', # no-break space = non-breaking space, U+00A0 ISOnum
3 '¡' => '¡', # inverted exclamation mark, U+00A1 ISOnum
4 '¢' => '¢', # cent sign, U+00A2 ISOnum
5 '£' => '£', # pound sign, U+00A3 ISOnum
6 '¤' => '¤', # currency sign, U+00A4 ISOnum
7 '¥' => '¥', # yen sign = yuan sign, U+00A5 ISOnum
8 '¦' => '¦', # broken bar = broken vertical bar, U+00A6 ISOnum
9 '§' => '§', # section sign, U+00A7 ISOnum
10 '¨' => '¨', # diaeresis = spacing diaeresis, U+00A8 ISOdia
11 '©' => '©', # copyright sign, U+00A9 ISOnum
12 'ª' => 'ª', # feminine ordinal indicator, U+00AA ISOnum
13 '«' => '«', # left-pointing double angle quotation mark = left pointing guillemet, U+00AB ISOnum
14 '¬' => '¬', # not sign, U+00AC ISOnum
15 '­' => '­', # soft hyphen = discretionary hyphen, U+00AD ISOnum
16 '®' => '®', # registered sign = registered trade mark sign, U+00AE ISOnum
17 '¯' => '¯', # macron = spacing macron = overline = APL overbar, U+00AF ISOdia
18 '°' => '°', # degree sign, U+00B0 ISOnum
19 '±' => '±', # plus-minus sign = plus-or-minus sign, U+00B1 ISOnum
20 '²' => '²', # superscript two = superscript digit two = squared, U+00B2 ISOnum
21 '³' => '³', # superscript three = superscript digit three = cubed, U+00B3 ISOnum
22 '´' => '´', # acute accent = spacing acute, U+00B4 ISOdia
23 'µ' => 'µ', # micro sign, U+00B5 ISOnum
24 '¶' => '¶', # pilcrow sign = paragraph sign, U+00B6 ISOnum
25 '·' => '·', # middle dot = Georgian comma = Greek middle dot, U+00B7 ISOnum
26 '¸' => '¸', # cedilla = spacing cedilla, U+00B8 ISOdia
27 '¹' => '¹', # superscript one = superscript digit one, U+00B9 ISOnum
28 'º' => 'º', # masculine ordinal indicator, U+00BA ISOnum
29 '»' => '»', # right-pointing double angle quotation mark = right pointing guillemet, U+00BB ISOnum
30 '¼' => '¼', # vulgar fraction one quarter = fraction one quarter, U+00BC ISOnum
31 '½' => '½', # vulgar fraction one half = fraction one half, U+00BD ISOnum
32 '¾' => '¾', # vulgar fraction three quarters = fraction three quarters, U+00BE ISOnum
33 '¿' => '¿', # inverted question mark = turned question mark, U+00BF ISOnum
34 'À' => 'À', # latin capital letter A with grave = latin capital letter A grave, U+00C0 ISOlat1
35 'Á' => 'Á', # latin capital letter A with acute, U+00C1 ISOlat1
36 'Â' => 'Â', # latin capital letter A with circumflex, U+00C2 ISOlat1
37 'Ã' => 'Ã', # latin capital letter A with tilde, U+00C3 ISOlat1
38 'Ä' => 'Ä', # latin capital letter A with diaeresis, U+00C4 ISOlat1
39 'Å' => 'Å', # latin capital letter A with ring above = latin capital letter A ring, U+00C5 ISOlat1
40 'Æ' => 'Æ', # latin capital letter AE = latin capital ligature AE, U+00C6 ISOlat1
41 'Ç' => 'Ç', # latin capital letter C with cedilla, U+00C7 ISOlat1
42 'È' => 'È', # latin capital letter E with grave, U+00C8 ISOlat1
43 'É' => 'É', # latin capital letter E with acute, U+00C9 ISOlat1
44 'Ê' => 'Ê', # latin capital letter E with circumflex, U+00CA ISOlat1
45 'Ë' => 'Ë', # latin capital letter E with diaeresis, U+00CB ISOlat1
46 'Ì' => 'Ì', # latin capital letter I with grave, U+00CC ISOlat1
47 'Í' => 'Í', # latin capital letter I with acute, U+00CD ISOlat1
48 'Î' => 'Î', # latin capital letter I with circumflex, U+00CE ISOlat1
49 'Ï' => 'Ï', # latin capital letter I with diaeresis, U+00CF ISOlat1
50 'Ð' => 'Ð', # latin capital letter ETH, U+00D0 ISOlat1
51 'Ñ' => 'Ñ', # latin capital letter N with tilde, U+00D1 ISOlat1
52 'Ò' => 'Ò', # latin capital letter O with grave, U+00D2 ISOlat1
53 'Ó' => 'Ó', # latin capital letter O with acute, U+00D3 ISOlat1
54 'Ô' => 'Ô', # latin capital letter O with circumflex, U+00D4 ISOlat1
55 'Õ' => 'Õ', # latin capital letter O with tilde, U+00D5 ISOlat1
56 'Ö' => 'Ö', # latin capital letter O with diaeresis, U+00D6 ISOlat1
57 '×' => '×', # multiplication sign, U+00D7 ISOnum
58 'Ø' => 'Ø', # latin capital letter O with stroke = latin capital letter O slash, U+00D8 ISOlat1
59 'Ù' => 'Ù', # latin capital letter U with grave, U+00D9 ISOlat1
60 'Ú' => 'Ú', # latin capital letter U with acute, U+00DA ISOlat1
61 'Û' => 'Û', # latin capital letter U with circumflex, U+00DB ISOlat1
62 'Ü' => 'Ü', # latin capital letter U with diaeresis, U+00DC ISOlat1
63 'Ý' => 'Ý', # latin capital letter Y with acute, U+00DD ISOlat1
64 'Þ' => 'Þ', # latin capital letter THORN, U+00DE ISOlat1
65 'ß' => 'ß', # latin small letter sharp s = ess-zed, U+00DF ISOlat1
66 'à' => 'à', # latin small letter a with grave = latin small letter a grave, U+00E0 ISOlat1
67 'á' => 'á', # latin small letter a with acute, U+00E1 ISOlat1
68 'â' => 'â', # latin small letter a with circumflex, U+00E2 ISOlat1
69 'ã' => 'ã', # latin small letter a with tilde, U+00E3 ISOlat1
70 'ä' => 'ä', # latin small letter a with diaeresis, U+00E4 ISOlat1
71 'å' => 'å', # latin small letter a with ring above = latin small letter a ring, U+00E5 ISOlat1
72 'æ' => 'æ', # latin small letter ae = latin small ligature ae, U+00E6 ISOlat1
73 'ç' => 'ç', # latin small letter c with cedilla, U+00E7 ISOlat1
74 'è' => 'è', # latin small letter e with grave, U+00E8 ISOlat1
75 'é' => 'é', # latin small letter e with acute, U+00E9 ISOlat1
76 'ê' => 'ê', # latin small letter e with circumflex, U+00EA ISOlat1
77 'ë' => 'ë', # latin small letter e with diaeresis, U+00EB ISOlat1
78 'ì' => 'ì', # latin small letter i with grave, U+00EC ISOlat1
79 'í' => 'í', # latin small letter i with acute, U+00ED ISOlat1
80 'î' => 'î', # latin small letter i with circumflex, U+00EE ISOlat1
81 'ï' => 'ï', # latin small letter i with diaeresis, U+00EF ISOlat1
82 'ð' => 'ð', # latin small letter eth, U+00F0 ISOlat1
83 'ñ' => 'ñ', # latin small letter n with tilde, U+00F1 ISOlat1
84 'ò' => 'ò', # latin small letter o with grave, U+00F2 ISOlat1
85 'ó' => 'ó', # latin small letter o with acute, U+00F3 ISOlat1
86 'ô' => 'ô', # latin small letter o with circumflex, U+00F4 ISOlat1
87 'õ' => 'õ', # latin small letter o with tilde, U+00F5 ISOlat1
88 'ö' => 'ö', # latin small letter o with diaeresis, U+00F6 ISOlat1
89 '÷' => '÷', # division sign, U+00F7 ISOnum
90 'ø' => 'ø', # latin small letter o with stroke, = latin small letter o slash, U+00F8 ISOlat1
91 'ù' => 'ù', # latin small letter u with grave, U+00F9 ISOlat1
92 'ú' => 'ú', # latin small letter u with acute, U+00FA ISOlat1
93 'û' => 'û', # latin small letter u with circumflex, U+00FB ISOlat1
94 'ü' => 'ü', # latin small letter u with diaeresis, U+00FC ISOlat1
95 'ý' => 'ý', # latin small letter y with acute, U+00FD ISOlat1
96 'þ' => 'þ', # latin small letter thorn, U+00FE ISOlat1
97 'ÿ' => 'ÿ', # latin small letter y with diaeresis, U+00FF ISOlat1
98 'ƒ' => 'ƒ', # latin small f with hook = function = florin, U+0192 ISOtech
99 'Α' => 'Α', # greek capital letter alpha, U+0391
100 'Β' => 'Β', # greek capital letter beta, U+0392
101 'Γ' => 'Γ', # greek capital letter gamma, U+0393 ISOgrk3
102 'Δ' => 'Δ', # greek capital letter delta, U+0394 ISOgrk3
103 'Ε' => 'Ε', # greek capital letter epsilon, U+0395
104 'Ζ' => 'Ζ', # greek capital letter zeta, U+0396
105 'Η' => 'Η', # greek capital letter eta, U+0397
106 'Θ' => 'Θ', # greek capital letter theta, U+0398 ISOgrk3
107 'Ι' => 'Ι', # greek capital letter iota, U+0399
108 'Κ' => 'Κ', # greek capital letter kappa, U+039A
109 'Λ' => 'Λ', # greek capital letter lambda, U+039B ISOgrk3
110 'Μ' => 'Μ', # greek capital letter mu, U+039C
111 'Ν' => 'Ν', # greek capital letter nu, U+039D
112 'Ξ' => 'Ξ', # greek capital letter xi, U+039E ISOgrk3
113 'Ο' => 'Ο', # greek capital letter omicron, U+039F
114 'Π' => 'Π', # greek capital letter pi, U+03A0 ISOgrk3
115 'Ρ' => 'Ρ', # greek capital letter rho, U+03A1
116 'Σ' => 'Σ', # greek capital letter sigma, U+03A3 ISOgrk3
117 'Τ' => 'Τ', # greek capital letter tau, U+03A4
118 'Υ' => 'Υ', # greek capital letter upsilon, U+03A5 ISOgrk3
119 'Φ' => 'Φ', # greek capital letter phi, U+03A6 ISOgrk3
120 'Χ' => 'Χ', # greek capital letter chi, U+03A7
121 'Ψ' => 'Ψ', # greek capital letter psi, U+03A8 ISOgrk3
122 'Ω' => 'Ω', # greek capital letter omega, U+03A9 ISOgrk3
123 'α' => 'α', # greek small letter alpha, U+03B1 ISOgrk3
124 'β' => 'β', # greek small letter beta, U+03B2 ISOgrk3
125 'γ' => 'γ', # greek small letter gamma, U+03B3 ISOgrk3
126 'δ' => 'δ', # greek small letter delta, U+03B4 ISOgrk3
127 'ε' => 'ε', # greek small letter epsilon, U+03B5 ISOgrk3
128 'ζ' => 'ζ', # greek small letter zeta, U+03B6 ISOgrk3
129 'η' => 'η', # greek small letter eta, U+03B7 ISOgrk3
130 'θ' => 'θ', # greek small letter theta, U+03B8 ISOgrk3
131 'ι' => 'ι', # greek small letter iota, U+03B9 ISOgrk3
132 'κ' => 'κ', # greek small letter kappa, U+03BA ISOgrk3
133 'λ' => 'λ', # greek small letter lambda, U+03BB ISOgrk3
134 'μ' => 'μ', # greek small letter mu, U+03BC ISOgrk3
135 'ν' => 'ν', # greek small letter nu, U+03BD ISOgrk3
136 'ξ' => 'ξ', # greek small letter xi, U+03BE ISOgrk3
137 'ο' => 'ο', # greek small letter omicron, U+03BF NEW
138 'π' => 'π', # greek small letter pi, U+03C0 ISOgrk3
139 'ρ' => 'ρ', # greek small letter rho, U+03C1 ISOgrk3
140 'ς' => 'ς', # greek small letter final sigma, U+03C2 ISOgrk3
141 'σ' => 'σ', # greek small letter sigma, U+03C3 ISOgrk3
142 'τ' => 'τ', # greek small letter tau, U+03C4 ISOgrk3
143 'υ' => 'υ', # greek small letter upsilon, U+03C5 ISOgrk3
144 'φ' => 'φ', # greek small letter phi, U+03C6 ISOgrk3
145 'χ' => 'χ', # greek small letter chi, U+03C7 ISOgrk3
146 'ψ' => 'ψ', # greek small letter psi, U+03C8 ISOgrk3
147 'ω' => 'ω', # greek small letter omega, U+03C9 ISOgrk3
148 'ϑ' => 'ϑ', # greek small letter theta symbol, U+03D1 NEW
149 'ϒ' => 'ϒ', # greek upsilon with hook symbol, U+03D2 NEW
150 'ϖ' => 'ϖ', # greek pi symbol, U+03D6 ISOgrk3
151 '•' => '•', # bullet = black small circle, U+2022 ISOpub
152 '…' => '…', # horizontal ellipsis = three dot leader, U+2026 ISOpub
153 '′' => '′', # prime = minutes = feet, U+2032 ISOtech
154 '″' => '″', # double prime = seconds = inches, U+2033 ISOtech
155 '‾' => '‾', # overline = spacing overscore, U+203E NEW
156 '⁄' => '⁄', # fraction slash, U+2044 NEW
157 '℘' => '℘', # script capital P = power set = Weierstrass p, U+2118 ISOamso
158 'ℑ' => 'ℑ', # blackletter capital I = imaginary part, U+2111 ISOamso
159 'ℜ' => 'ℜ', # blackletter capital R = real part symbol, U+211C ISOamso
160 '™' => '™', # trade mark sign, U+2122 ISOnum
161 'ℵ' => 'ℵ', # alef symbol = first transfinite cardinal, U+2135 NEW
162 '←' => '←', # leftwards arrow, U+2190 ISOnum
163 '↑' => '↑', # upwards arrow, U+2191 ISOnum
164 '→' => '→', # rightwards arrow, U+2192 ISOnum
165 '↓' => '↓', # downwards arrow, U+2193 ISOnum
166 '↔' => '↔', # left right arrow, U+2194 ISOamsa
167 '↵' => '↵', # downwards arrow with corner leftwards = carriage return, U+21B5 NEW
168 '⇐' => '⇐', # leftwards double arrow, U+21D0 ISOtech
169 '⇑' => '⇑', # upwards double arrow, U+21D1 ISOamsa
170 '⇒' => '⇒', # rightwards double arrow, U+21D2 ISOtech
171 '⇓' => '⇓', # downwards double arrow, U+21D3 ISOamsa
172 '⇔' => '⇔', # left right double arrow, U+21D4 ISOamsa
173 '∀' => '∀', # for all, U+2200 ISOtech
174 '∂' => '∂', # partial differential, U+2202 ISOtech
175 '∃' => '∃', # there exists, U+2203 ISOtech
176 '∅' => '∅', # empty set = null set = diameter, U+2205 ISOamso
177 '∇' => '∇', # nabla = backward difference, U+2207 ISOtech
178 '∈' => '∈', # element of, U+2208 ISOtech
179 '∉' => '∉', # not an element of, U+2209 ISOtech
180 '∋' => '∋', # contains as member, U+220B ISOtech
181 '∏' => '∏', # n-ary product = product sign, U+220F ISOamsb
182 '∑' => '∑', # n-ary sumation, U+2211 ISOamsb
183 '−' => '−', # minus sign, U+2212 ISOtech
184 '∗' => '∗', # asterisk operator, U+2217 ISOtech
185 '√' => '√', # square root = radical sign, U+221A ISOtech
186 '∝' => '∝', # proportional to, U+221D ISOtech
187 '∞' => '∞', # infinity, U+221E ISOtech
188 '∠' => '∠', # angle, U+2220 ISOamso
189 '∧' => '∧', # logical and = wedge, U+2227 ISOtech
190 '∨' => '∨', # logical or = vee, U+2228 ISOtech
191 '∩' => '∩', # intersection = cap, U+2229 ISOtech
192 '∪' => '∪', # union = cup, U+222A ISOtech
193 '∫' => '∫', # integral, U+222B ISOtech
194 '∴' => '∴', # therefore, U+2234 ISOtech
195 '∼' => '∼', # tilde operator = varies with = similar to, U+223C ISOtech
196 '≅' => '≅', # approximately equal to, U+2245 ISOtech
197 '≈' => '≈', # almost equal to = asymptotic to, U+2248 ISOamsr
198 '≠' => '≠', # not equal to, U+2260 ISOtech
199 '≡' => '≡', # identical to, U+2261 ISOtech
200 '≤' => '≤', # less-than or equal to, U+2264 ISOtech
201 '≥' => '≥', # greater-than or equal to, U+2265 ISOtech
202 '⊂' => '⊂', # subset of, U+2282 ISOtech
203 '⊃' => '⊃', # superset of, U+2283 ISOtech
204 '⊄' => '⊄', # not a subset of, U+2284 ISOamsn
205 '⊆' => '⊆', # subset of or equal to, U+2286 ISOtech
206 '⊇' => '⊇', # superset of or equal to, U+2287 ISOtech
207 '⊕' => '⊕', # circled plus = direct sum, U+2295 ISOamsb
208 '⊗' => '⊗', # circled times = vector product, U+2297 ISOamsb
209 '⊥' => '⊥', # up tack = orthogonal to = perpendicular, U+22A5 ISOtech
210 '⋅' => '⋅', # dot operator, U+22C5 ISOamsb
211 '⌈' => '⌈', # left ceiling = apl upstile, U+2308 ISOamsc
212 '⌉' => '⌉', # right ceiling, U+2309 ISOamsc
213 '⌊' => '⌊', # left floor = apl downstile, U+230A ISOamsc
214 '⌋' => '⌋', # right floor, U+230B ISOamsc
215 '⟨' => '〈', # left-pointing angle bracket = bra, U+2329 ISOtech
216 '⟩' => '〉', # right-pointing angle bracket = ket, U+232A ISOtech
217 '◊' => '◊', # lozenge, U+25CA ISOpub
218 '♠' => '♠', # black spade suit, U+2660 ISOpub
219 '♣' => '♣', # black club suit = shamrock, U+2663 ISOpub
220 '♥' => '♥', # black heart suit = valentine, U+2665 ISOpub
221 '♦' => '♦', # black diamond suit, U+2666 ISOpub
222 '"' => '"', # quotation mark = APL quote, U+0022 ISOnum
223 '&' => '&', # ampersand, U+0026 ISOnum
224 '<' => '<', # less-than sign, U+003C ISOnum
225 '>' => '>', # greater-than sign, U+003E ISOnum
226 'Œ' => 'Œ', # latin capital ligature OE, U+0152 ISOlat2
227 'œ' => 'œ', # latin small ligature oe, U+0153 ISOlat2
228 'Š' => 'Š', # latin capital letter S with caron, U+0160 ISOlat2
229 'š' => 'š', # latin small letter s with caron, U+0161 ISOlat2
230 'Ÿ' => 'Ÿ', # latin capital letter Y with diaeresis, U+0178 ISOlat2
231 'ˆ' => 'ˆ', # modifier letter circumflex accent, U+02C6 ISOpub
232 '˜' => '˜', # small tilde, U+02DC ISOdia
233 ' ' => ' ', # en space, U+2002 ISOpub
234 ' ' => ' ', # em space, U+2003 ISOpub
235 ' ' => ' ', # thin space, U+2009 ISOpub
236 '‌' => '‌', # zero width non-joiner, U+200C NEW RFC 2070
237 '‍' => '‍', # zero width joiner, U+200D NEW RFC 2070
238 '‎' => '‎', # left-to-right mark, U+200E NEW RFC 2070
239 '‏' => '‏', # right-to-left mark, U+200F NEW RFC 2070
240 '–' => '–', # en dash, U+2013 ISOpub
241 '—' => '—', # em dash, U+2014 ISOpub
242 '‘' => '‘', # left single quotation mark, U+2018 ISOnum
243 '’' => '’', # right single quotation mark, U+2019 ISOnum
244 '‚' => '‚', # single low-9 quotation mark, U+201A NEW
245 '“' => '“', # left double quotation mark, U+201C ISOnum
246 '”' => '”', # right double quotation mark, U+201D ISOnum
247 '„' => '„', # double low-9 quotation mark, U+201E NEW
248 '†' => '†', # dagger, U+2020 ISOpub
249 '‡' => '‡', # double dagger, U+2021 ISOpub
250 '‰' => '‰', # per mille sign, U+2030 ISOtech
251 '‹' => '‹', # single left-pointing angle quotation mark, U+2039 ISO proposed
252 '›' => '›', # single right-pointing angle quotation mark, U+203A ISO proposed
253 '€' => '€', # euro sign, U+20AC NEW
254 );
And the one for XHTML:
1 ''' => ''', # apostrophe = APL quote, U+0027 ISOnum
えらいこっちゃぁ。要はこれだけのものを残しっちまうわけだ、html_entity_decode は。
論より証拠、で、こんな検証 PHP:
1 <style type="text/css">
2 .container { width: 800px; height: 200px; }
3 </style>
4 <form method="POST">
5 <div class="container">
6 <textarea name='txt' style='width: 100%; height: 100%;'>
7 <?php
8 if ($_POST) {
9 echo $_POST['txt'];
10 }
11 ?>
12 </textarea>
13 </div>
14 <input type="submit">
15 </form>
16
17 <pre style="border: 1px solid #777;">
18 <?php
19 if ($_POST) {
20 echo html_entity_decode($_POST['txt']);
21 }
22 ?>
23 </pre>
24 <pre style="border: 1px solid #777;">
25 <?php
26 if ($_POST) {
27 echo html_entity_decode($_POST['txt'], ENT_QUOTES | ENT_COMPAT | ENT_HTML401);
28 }
29 ?>
30 </pre>
31
32 <pre style="border: 1px solid #777;">
33 <?php
34 if ($_POST) {
35 echo htmlentities($_POST['txt']);
36 }
37 ?>
38 </pre>
39 <pre style="border: 1px solid #777;">
40 <?php
41 if ($_POST) {
42 echo htmlentities($_POST['txt'], ENT_QUOTES | ENT_COMPAT | ENT_HTML401);
43 }
44 ?>
45 </pre>
(検証はブラウザで見るだけではダメね。「ソースの表示」で見ること。)
検証結果については、「今ワタシと同じように困ってる」人ならいらないだろうし、「困るかもしれないので知りたい」人は、ご自身でやってみるのが良かろう。どれも残念な結果になります。とりわけ残念なのは
1
2 '
なんですが、apos については先の StackOverflow からの引用でわかるでしょう。nbsp についてはPHPのマニュアルにこう書いてあります:
trim(html_entity_decode(‘ ‘)); の結果が空の文字列に ならないことを疑問に思う人もいるでしょう。なぜそうなるのかというと、 デフォルトのエンコーディング ISO-8859-1 では ‘ ‘ エンティティが ASCII コード 32 (これは trim() で取り除かれる) ではなく ASCII コード 160 (0xa0) に変換されるからです。
で、ずっと先の StackOverflow ページに答えがあったのに、なかなか気付かなかったけれど、答えは概ねこんな感じ:
1 function entities_to_unicode($str, $flags) {
2 $str = html_entity_decode(
3 $str, $flags,
4 'UTF-8');
5 $str = preg_replace_callback(
6 "/(&#[0-9]+;)/", function($m) {
7 return mb_convert_encoding($m[1], "UTF-8", "HTML-ENTITIES");
8 }, $str);
9 return $str;
10 }
11
12 $flags = ENT_QUOTES | ENT_COMPAT | ENT_HTML401;
13 $result = entities_to_unicode(
14 preg_replace(
15 array('/ /', '/'/'),
16 array(' ', "'"),
17 $some_input), $flags);
UTF-8特定してるのは、先の本題ではない引用からわかる通り、HTML401の名前付き実体参照の多くは「非ASCII」前提であり、つまり Unicode でなければならないんですね、「変換先」は。たとえば LATIN-1 で表現出来ない参照は、LATIN-1 には変換は出来ない。当たり前。日本人でもわかりやすいのは
1 ← (←)
2 ↑ (↑)
3 → (→)
4 ↓ (↓)
5 ↔ (↔)
6 ↵ (↵)
7 ⇐ (⇐)
8 ⇑ (⇑)
9 ⇒ (⇒)
10 ⇓ (⇓)
11 ⇔ (⇔)
とかかね。
mb_convert_encoding まで駆り出さないと出来ないのか、と思うのはきっと、html_entity_decode が名前負けしてるからだ。誰だってここまでやってくれるものが「html_entity_decodeにある」と思いたいと思うぞ。