前からこの手の、やなんだよ。
例えば静的 HTML で
1 <html xmlns="http://www.w3.org/1999/xhtml">
2 <head>
3 <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
と書いてみたり、あるいは同じく HTML の form で
1 <form action="demo_form.asp" accept-charset="ISO-8859-1">
2 First name: <input type="text" name="fname"><br />
3 Last name: <input type="text" name="lname"><br />
4 <input type="submit" value="Submit">
5 </form>
と書けてみたり、もしくは、ajax とか python の urllib2 とか PHP の cURL とかで「Accept-Charset: iso-2022-jp」と明示したりとか。
この「Charset」は IANA が管理しており、こんなだ:
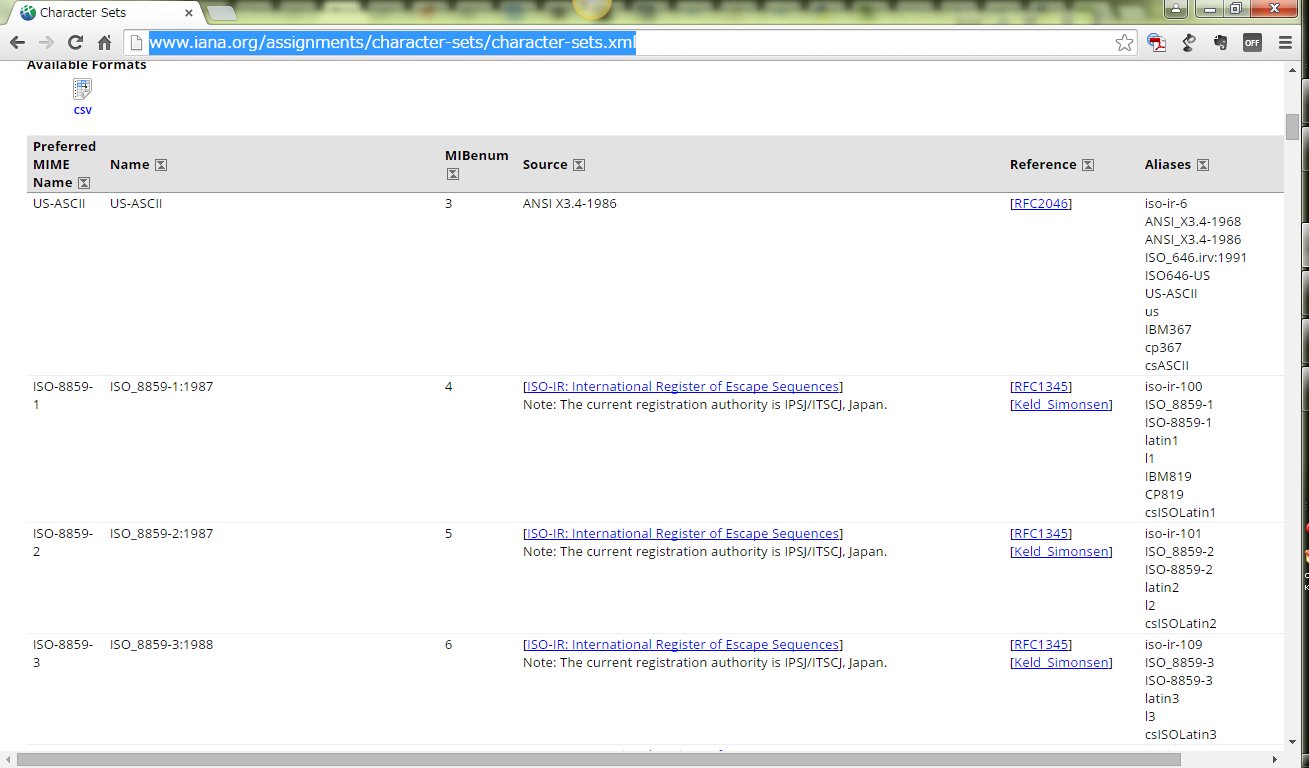
この表は csv でもダウンロード出来る。
つまりは、「正式には」、上で挙げたようなケースで指定する charset は、ここに書かれているものだけ使うのが最も行儀が良い、あるいは、どんなにマイナーでもここにあるものならば文句を言われる筋合いはないはずだ、ということになるわけだ。
ところがこの名前と Python の codec 名とは、まぁあんまし合わない:
1 >>> import codecs
2 >>> codecs.lookup("Shift_JIS").name
3 'shift_jis'
4 >>> codecs.lookup("MS_Kanji").name
5 'cp932'
6 >>> codecs.lookup("csEUCPkdFmtJapanese").name
7 Traceback (most recent call last):
8 File "<stdin>", line 1, in <module>
9 LookupError: unknown encoding: csEUCPkdFmtJapanese
10 >>> codecs.lookup("EUC-JP").name
11 'euc_jp'
12 >>> codecs.lookup("Windows-31J").name
13 Traceback (most recent call last):
14 File "<stdin>", line 1, in <module>
15 LookupError: unknown encoding: Windows-31J
Python で処理できない charset はまぁ無視するしかない(というか何某かエラーを返すんだろう)ので却って問題にはならないんだけれど、IANA で「alias」として列挙してるものたちは「同じもの」と言うべきなので、Python の codecs.lookup がたとえ失敗したとしても、兄弟名で引けるなら、それは扱えて然るべきだ、と思うであろ? けどさ、上のコンソール結果の Shift_JIS と MS_Kanji のをみてよ。つまり IANA は「同一」とみなしているのに Python は「別物」(方言として区別している)としている。
それだけではなくて、特に Java プログラマにとって重大な「Windows-31J」(*)は IANA で管理されていて「妥当」なのよね、今や。なのに python はこれを知らない。
個人的にはもう utf-8 と ISO-2022-* の二者択一にすればいい、と思っているし、事実かなり utf-8 へ収束しつつあるのでワタシ自身は一切困ることはないんだけれど、まだまだ「業務系」では使っておるでしょ? フツーに Shift_JIS、Windows-31J で自爆し続けている業務アプリケーション、わんさかあるんだと思ってる。
ひとまずは、「別名の管理が違う問題」と、「Windows-31J問題」は隅にいったん置いておくとして、IANA charset 名と Python codec との対応付けを書いてみた:
1 # -*- coding: utf-8 -*-
2 #
3 # character-sets-1.csv is from:
4 # http://www.iana.org/assignments/character-sets/character-sets.xhtml
5 #
6 def _mangle_key(s):
7 return s.replace("-", "_").lower()
8
9
10 def _build_dict():
11 import codecs
12 import csv
13 reader = csv.DictReader(open("character-sets-1.csv", "rb"))
14 result = {}
15 for row in reader:
16 trynames = [row["Name"]]
17 if row["Preferred MIME Name"]:
18 trynames.append(row["Preferred MIME Name"])
19 if row["Aliases"]:
20 trynames.extend(row["Aliases"].split("\n"))
21
22 pycodecnames = set()
23 nf = []
24 for nm in trynames:
25 try:
26 pyc = codecs.lookup(nm)
27 result[_mangle_key(nm)] = (
28 pyc.name, row["Preferred MIME Name"])
29 pycodecnames.add(pyc)
30 except LookupError:
31 nf.append(nm)
32 if pycodecnames and nf:
33 pyc = list(pycodecnames)[0]
34 for nm in nf:
35 result[_mangle_key(nm)] = (
36 pyc.name, row["Preferred MIME Name"])
37 return result
38
39
40 def _get_dict():
41 """
42 return dict, as:
43 key: iena name (or alias)
44 value: tuple of python codec name and preferred MIME name
45 """
46 import os
47 import pickle
48 if os.path.exists("iana_character_sets.pickle"):
49 return pickle.load(open("iana_character_sets.pickle", "rb"))
50 result = _build_dict()
51 pickle.dump(result, open("iana_character_sets.pickle", "wb"))
52 return result
53
54
55 _IANA_MAPPING = _get_dict()
56 del _build_dict
57 del _get_dict
58
59
60 def lookup(charset_name):
61 """
62 if exists, return tuple of python codec name and preferred MIME name,
63 otherwise raise LookupError
64 """
65 key = _mangle_key(charset_name)
66 if key in _IANA_MAPPING:
67 return _IANA_MAPPING[key]
68 raise LookupError("unsupported charset: %s" % charset_name)
character-sets-1.csv はダウンロードして同じ場所に置いといてね。モジュールとして使います:
1 >>> import iana_character_sets
2 >>> help(iana_character_sets.lookup)
3 Help on function lookup in module iana_character_sets:
4
5 lookup(charset_name)
6 if exists, return tuple of python codec name and preferred MIME name,
7 otherwise raise LookupError
8 >>> iana_character_sets.lookup("shift_jis")
9 ('shift_jis', 'Shift_JIS')
10 >>> iana_character_sets.lookup("shift-jis")
11 ('shift_jis', 'Shift_JIS')
12 >>> iana_character_sets.lookup("Shift_jis")
13 ('shift_jis', 'Shift_JIS')
14 >>> iana_character_sets.lookup("ms-kanji")
15 ('cp932', 'Shift_JIS')
16 >>> iana_character_sets.lookup("ms_kanji")
17 ('cp932', 'Shift_JIS')
18 >>> iana_character_sets.lookup("iso-8859-6-E")
19 Traceback (most recent call last):
20 File "<stdin>", line 1, in <module>
21 File "iana_character_sets.py", line 68, in lookup
22 raise LookupError("unsupported charset: %s" % charset_name)
23 LookupError: unsupported charset: iso-8859-6-E
いやらしい話、たまたま Python codec から lookup 出来れば無条件にそれを信じつつ、IANA Alias 群をグルーピングしようとするので、対応表はチグハグになります。つまり「Shift_JIS」群は、Python codec では cp932 だったり shift_jis だったりする。これはもうどうしようもないわ。