好きなものに囲まれていたい、もしくは「収集癖」に関する検討について。
どこまでが推し活で、どこまでがコレクターだろうか。リアルタイムで観ているものとしては、「かげきしょうじょ!!」は久しぶりの大ヒットで、各話、毎回10回はリピート再生するほどにお気に入っている。毎季一つか二つくらいは毎週楽しみなアニメはあったけれど、ここまで夢中になってるのは宝石の国以来。こういうスポ根ものってのは、やっぱし昭和世代には刺さる。
して、「収集癖」発揮して、公式サイトにある画像を集めて Windows テーマに仕立て上げちゃるぜなんてことして喜んでるんだけど、画像だけでは物足りなくなり、「応援コメント」:
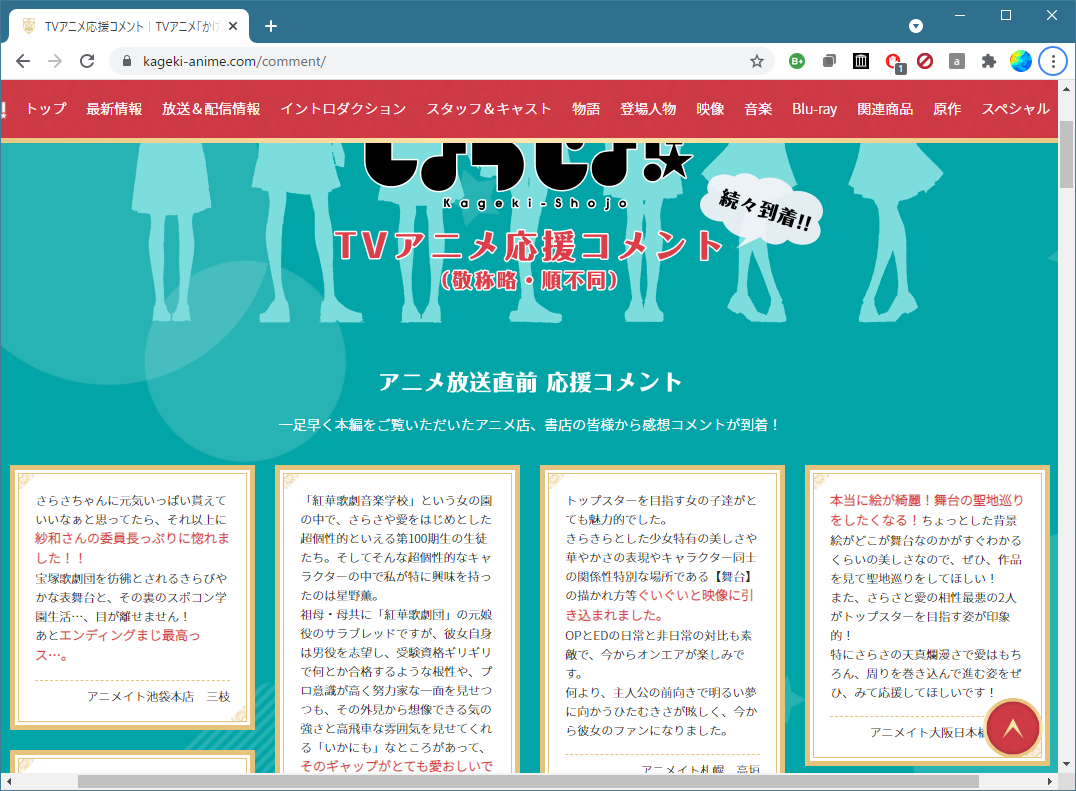
も画像化してデスクトップ背景にしたいぞ、と思うに至り。興味がなかったり、評価してないものについてのこうした応援コメントだったら、これは単なるセールストーク。なにせ、視聴者自身の評価ではなくて、売り手による宣伝文句が並んでるだけ、だからね。けれどもワタシにはこのアニメが刺さりまくっているので、この「セールストーク」全部が「わしもわしも」と共感しきりで、読んでると楽しくなってくるわけだ。
というかさ、この「応援コメント」ページのレイアウト、読みにくっ…。というわけで、「ずっと読んでいたい」「読みやすくしたい」の二つの動機でもって、デスクトップ背景にしたい、と。「読みやすくしたい」は、一人のコメントごとに一枚の絵にしたい、てことだ。とりあえず、そうしたことをしたいぜスクリプトの初版は簡単さ:
1 # -*- coding: utf-8 -*-
2 import io
3 import os
4 import re
5 import subprocess
6 import urllib.request
7
8 import bs4 # require "beautifulsoup", please install "bs4"
9
10
11 def _build_base():
12 topurl = "https://kageki-anime.com/comment/"
13 outbase = "_top_orig.html"
14 if not os.path.exists(outbase):
15 res, _ = urllib.request.urlretrieve(topurl)
16 d = io.open(res, "r", encoding="utf-8").read()
17 d = re.sub(r'(<head .*?>\n)', r'\1<base href="{}">\n'.format(topurl), d)
18 io.open(outbase, "w", encoding="utf-8").write(d)
19 return io.open(outbase, "r", encoding="utf-8").read()
20
21
22 def _genpages():
23 orig_cont = _build_base()
24 soup = bs4.BeautifulSoup(orig_cont, features="html.parser")
25 cont_head = orig_cont[:orig_cont.index('</head>')]
26 cont_foot = orig_cont[orig_cont.index('</body>'):]
27 for crt in ({"name": "li", "class": "item"}, {"name": "div", "class": "box"}):
28 for celem in soup.find_all(**crt):
29 pelem = celem.find("p")
30 nelem = celem.find(**{"name": "div", "class": "name"})
31 conts = [
32 cont_head,
33 '</head>',
34 '<body id="top">',
35 '<div id="wrapper">',
36 '<div id="comment">',
37 ]
38 conts.extend([
39 '<div class="top_comment">',
40 '<div class="box">',
41 ])
42 conts.append(str(nelem))
43 conts.append(str(pelem).replace("<br/>", " ▽"))
44 conts.extend([
45 '</div>',
46 '</div>',
47 ])
48 conts.extend([
49 '</div>',
50 '</div>',
51 cont_foot,
52 ])
53 yield "\n".join(conts)
54
55
56 def _kscomments_toimage():
57 for i, cont in enumerate(_genpages()):
58 ofn = os.path.abspath("ks_comments_{:03d}.html".format(i))
59 with io.open(ofn, "w", encoding="utf-8") as fo:
60 fo.write(cont)
61 ofnimg = os.path.splitext(ofn)[0] + ".png"
62 cmdl = [
63 "c:/Program Files (x86)/Google/Chrome/Application/chrome",
64 "--headless",
65 "--disable-gpu",
66 "--enable-logging",
67
68 "--hide-scrollbars",
69 "--force-device-scale-factor=4.0",
70 "--window-size=1920,1080",
71 ofn,
72 "--screenshot=" + ofnimg,
73 ]
74 subprocess.check_call(cmdl)
75
76
77 if __name__ == '__main__':
78 _kscomments_toimage()
発想はシンプルで、元の html を、各コメント一つずつにバラバラに分解して、その各々を、headless chrome の「screenshot」で画像にする、というもの。簡単、だよね? けれども。これがまったく満足のいく画像にならないのはそう、「ズーム」の制御が出来てないからだ。–window-size でブラウザのビューポートのサイズ、そして –force-device-scale-factor で、出力画像の解像度を制御出来ているけれど、やりたいのは、headless でない chrome で「Ctrl-Plus」でめいっぱい拡大した状態に相当する画像にしたいのだ。
色々探ったけれど、結局はこの共感を得られていなくてなおかつ正面から答えてないこの回答が、確かに唯一の正解らしい。この回答が「答えになってない」かつ共感ゼロなのは、たとえるなら、「接種会場に持っていく必要があるのはなんですか?」という質問に「入場前から予診票をカバンから出しておく必要はありません」と答えているようなものだから。chrome –headless の起動オプション(や puppeteer.launch のオプション)でコントロールする部分は「接種会場に持っていくもの」ということなわけだが、「Ctrl-Plus で制御するのと同じことが出来る制御」は、これは答えとしては「接種会場に到着する前には出来ないので、お越しいただいてから行ってください」ということ。つまり、答えは、「chrome の起動オプションでのコントロールは出来ないけれど、そもそも DevTools API ってのはさ、ページのレンダリングにそもそも割り込めるのであるからして、そこで好きに css とか差し込めばええやん」。
DevTools API を使った制御はとりあえずあとまわしにして、「どうせ css でしか制御出来ないんだから」てことだけが本質、てことなのだから、ワタシの目的は以下で完遂出来る:
1 body {
2 min-width: 0 !important;
3 min-height: 0 !important;
4 zoom: 1.8;
5 line-height: 1.3;
6 font-size: 2.0rem;
7 }
8
9 #comment .top_comment .name {
10 font-size: 3.2rem;
11 }
12
13 #comment .top_comment .name span.red {
14 font-size: 2.6rem;
15 }
16
17 #comment .top_comment p strong {
18 font-size: 2.3rem;
19 }
1 # -*- coding: utf-8 -*-
2 import io
3 import os
4 import re
5 import subprocess
6 import urllib.request
7
8 import bs4 # require "beautifulsoup", please install "bs4"
9
10
11 def _build_base():
12 topurl = "https://kageki-anime.com/comment/"
13 outbase = "_top_orig.html"
14 if not os.path.exists(outbase):
15 res, _ = urllib.request.urlretrieve(topurl)
16 d = io.open(res, "r", encoding="utf-8").read()
17 d = re.sub(r'(<head .*?>\n)', r'\1<base href="{}">\n'.format(topurl), d)
18 io.open(outbase, "w", encoding="utf-8").write(d)
19 return io.open(outbase, "r", encoding="utf-8").read()
20
21
22 def _genpages():
23 orig_cont = _build_base()
24 soup = bs4.BeautifulSoup(orig_cont, features="html.parser")
25 cont_head = orig_cont[:orig_cont.index('</head>')]
26 cont_foot = orig_cont[orig_cont.index('</body>'):]
27 cssfn = "file://" + os.path.abspath("ks_comments.css").replace("\\", "/")
28 for crt in ({"name": "li", "class": "item"}, {"name": "div", "class": "box"}):
29 for celem in soup.find_all(**crt):
30 pelem = celem.find("p")
31 nelem = celem.find(**{"name": "div", "class": "name"})
32 conts = [
33 cont_head,
34 '<link rel="stylesheet" href="{}">'.format(cssfn),
35 '</head>',
36 '<body id="top">',
37 '<div id="wrapper">',
38 '<div id="comment">',
39 ]
40 conts.extend([
41 '<div class="top_comment">',
42 '<div class="box">',
43 ])
44 conts.append(str(nelem))
45 conts.append(str(pelem).replace("<br/>", " ▽"))
46 conts.extend([
47 '</div>',
48 '</div>',
49 ])
50 conts.extend([
51 '</div>',
52 '</div>',
53 cont_foot,
54 ])
55 yield "\n".join(conts)
56
57
58 def _kscomments_toimage():
59 for i, cont in enumerate(_genpages()):
60 ofn = os.path.abspath("ks_comments_{:03d}.html".format(i))
61 with io.open(ofn, "w", encoding="utf-8") as fo:
62 fo.write(cont)
63 ofnimg = os.path.splitext(ofn)[0] + ".png"
64 cmdl = [
65 "c:/Program Files (x86)/Google/Chrome/Application/chrome",
66 "--headless",
67 "--disable-gpu",
68 "--enable-logging",
69
70 "--hide-scrollbars",
71 "--force-device-scale-factor=4.0",
72 "--window-size=1920,1080",
73 ofn,
74 "--screenshot=" + ofnimg,
75 ]
76 subprocess.check_call(cmdl)
77
78
79 if __name__ == '__main__':
80 _kscomments_toimage()
まぁ今のワタシのこれの場合、もともとオリジナルの html に対する加工がそこそこあるので、css をこうして付け加えることには抵抗はないわけなのだが、そうではなくて、自作ではないどこかのページのキャプチャをしたいときに、とくに「zoom だけコントロール出来ればいい」という場合に、毎度今回のこのスクリプトみたいなのをイチイチ書くのでは、かなり苦痛なわけだ。
「chrome の起動オプションでは出来なくて、だけれども DevTools API として実現できる」のための puppeteer。たとえばこんなかんじ:
1 const puppeteer = require('puppeteer-core');
2 async function run () {
3 const executablePath =
4 "c:/Program Files (x86)/Google/Chrome/Application/chrome.exe";
5 const browser = await puppeteer.launch({
6 headless: true,
7 executablePath: executablePath,
8 defaultViewport: {
9 width: 1920,
10 height: 1080,
11 deviceScaleFactor: 4.0, /* --force-device-scale-factor */
12 },
13 });
14 const page = await browser.newPage();
15
16 // ks_comments_000.html は上の python で加工したページだが、当然
17 // http:// なページも指せる。当たり前。
18 await page.goto('file://path/to/ks_comments_000.html');
19
20 // スタイルをコントロールする:
21 // await page.evaluate(({}) => {$('body').css('zoom', '3.0');},{});
22 // await page.addScriptTag({url: 'https://code.jquery.com/jquery-3.2.1.min.js'})
23 // await page.evaluate(({}) => {jQuery('body').css('zoom', '1.7');},{});
24 await page.addStyleTag({path: 'ks_comments.css'})
25
26
27 await page.screenshot({path: './ks_comments_000.png'});
28 browser.close();
29 }
30 run();
「evaluate」は当然処理している html ページのコンテキスト依存なので、jquery をロードしていないページで「$」は使えないし、ロードしているページなら addScriptTag はいらない…みたいな非常に簡単なことなんだけれど、headless chrome、DevTools API の整理されたドキュメントがどこにもない上に例によって間違った解説日本語の存在のせいで、この簡単な正解にたどり着くのには非常に苦労した。(puppeteer についてはちゃんとしたドキュメントがある。最初からそれだけみてればよかったと後悔したが、日本語サイト読んで後悔するのはまぁいつものことだ。)
なお、この zoom の件は、Capturing webpage as image and converting it to video にちょこっと触れておいた。