これと違って動機は先に書いちゃう。
これで hstack, vstack してみたので、つい「4つの異なる動画を ffmpeg の hstack, vstack で一つの動画にする」のをやってみたくなったのである。たとえばともだちと共同で同じ対象を撮影したとしてだな、未編集ならばそれらは時刻あわせさえちゃんと出来るなら、対象までの距離差さえなければ簡単に同期するはずだ、みたいなことね。
なんだけれど、「youtube からのダウンロードは規約違反」だったり、それ以前に「ライセンス」やら「プライバシー保護」やらとにかく繊細だからさ、原則この手のは「自分で撮影したり何かしら機械的に自分で作った動画」を使うしかないわけね。そういうのに相応しいのを手持ちなら良かったんだけど、あいにく手持ちじゃない。
「ともだちと共同で同じ対象を撮影した」とするならば、普通同期ポイントまでの時間が撮影者によって違うのが普通よね。なので、「検証用の動画」を作るならば、同期ポイントまでの時間がバラバラのものを作りたい。
さらにはそもそも「実景を撮影」だとか「ちゃんとしたアニメーション」でない場合、「絵と音が同期している」ものを(撮影以外の方法で)生み出すのは難儀だ、て話。
色々思考をめぐらしていたんだけれど、「Text to speech で喋らせた音声の Waveform 動画」が一番この目的に相応しいかなと。
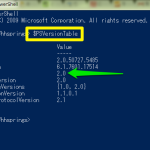
すんげー久しぶりで思いっきり忘れておるが、
を読み返しつつ、Speech Synthesis Markup Language なんて新たな発見もしつつで、まずはこれとほぼ同じノリの(バカ)スクリプト:
1 # -*- coding: utf-8 -*-
2 from os import path
3 import sys
4 import codecs
5 import subprocess
6
7
8 # =============================================
9 ifn = sys.argv[1]
10
11 #
12 _voices = [ # インストールしてるのしか使えないわよ
13 "Microsoft Server Speech Text to Speech Voice (en-US, Helen)",
14 "Microsoft Server Speech Text to Speech Voice (en-US, ZiraPro)",
15 "Microsoft Server Speech Text to Speech Voice (en-US, Helen)",
16 "Microsoft Server Speech Text to Speech Voice (en-US, ZiraPro)",
17 ]
18 for i, voice in enumerate(_voices):
19 fn = "tmp.ps1"
20 fo = codecs.getwriter('cp932')(open(fn, "w"))
21 # ---------------------------------------------
22 fo.write("""\
23 [Reflection.Assembly]::LoadWithPartialName("Microsoft.Speech")
24 $speak = New-Object Microsoft.Speech.Synthesis.SpeechSynthesizer
25 $speak.Rate = -3 # from -10 to 10, default is zero.
26 $speak.SetOutputToWaveFile("{}-{}.mp3")
27 """.format(path.join(path.abspath("."), path.basename(ifn)), i + 1))
28 # ---------------------------------------------
29
30 # ---------------------------------------------
31 s = open(ifn, "rb").read().decode("cp932").strip()
32 fo.write(u"""\
33 $speak.SelectVoice("{}")
34 """.format(voice))
35 fo.write(u"""\
36 $speak.SpeakSsml("
37 <speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xml:lang='en-US'>
38 <s>
39 {}{}
40 </s>
41 </speak>
42 ")
43 """.format("/" * i, s))
44 # ---------------------------------------------
45 fo.write("""$speak.Dispose()
46 """)
47 fo.close()
48 # ---------------------------------------------
49
50 # =============================================
51 subprocess.call([
52 "C:/WINDOWS/SysWOW64/WindowsPowerShell/v1.0/powershell",
53 path.abspath(fn)])
54 # =============================================
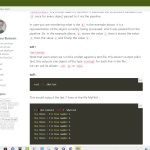
もとのヤツを書いたころは今より Python 慣れしてない頃なので、今みると危なっかしいところもある(しかも 2.7 でしか動かんだろう)けど気にしてない。ともあれ、これにより4つの mp3 が出来た。これを Waveform な動画にするのは FFMpeg の wikiをみればすぐに出来る:
1 me@host: ~$ for i in *.mp3 ; do \
2 > ffmpeg -y -i $i \
3 > -filter_complex "[0:a]showwaves=s=1920x1080:mode=line,format=yuv420p[v]" \
4 > -map "[v]" -map 0:a -c:v libx264 -c:a aac \
5 > $i.mp4 ; done
てわけで、こんな動画4つが出来た:
後ろのものほど先頭で余分に「スラッシュ」を喋らせてる。(続く投稿でやる予定の検証の都合上、ブランクじゃ困るので。)