これの続きだと果たして言えるのやらどうやら。
これ、それにこれでの主張というのは、「質の良い見える化を皆で共有すべし、それをするのはメディアの責務だ、それによってコンセンサスを醸成せよ」「二週間前の行動の反映なのだから、二週間後予測に基づいて行動するのがデフォルトなんではないんかーい」の二点が主たるものである。さらに「人口比」という見出しで括って言いたかったのは「相応しい指標で思考すべきで、そのための「統一的なものの見方」が必要である」てこと。
後者の、「相応しい指標」は、ほんとは専門家会議や各地方自治体行政がきちんと考えて、報告してくれていたりはするわけである。むろん「個々が個々に」なのはマズいにせよ、各々ちゃんとやろうとはしているわけだ。でもメディアは「批判が仕事である」と勘違いしているので、「指標を示せ」と行政や政府に文句だけを言い続ける。いや…、「お前らにも出来るんだし、出てるだろが」と。そういうことをワタシは言いたいわけである。ワタシが「人口比」で主張したことは、東京都と政府の指標にちゃんと含まれてる。それをみてる。メディアがそこを軽視して「今日は新たに300人でしたきゃー」と、そこばかりを強調し、もっと議論しやすい移動平均で議論することを怠り、10万人あたりを伝えることも軽視し、なので「島根で10人感染者が出ることがどれほど危険なことなのか」が一向に国民に伝わらない。
まぁそんなことが、言いたかったことなわけなんだけれど、もう一つ、隠れたテーマとしては、「こうした可視化は、20年前と今とでは、簡単さが雲泥の差であるということを伝えること」でもあったりした。正直ワタシが学生の頃なんてのは、今では誰でも使える「スプライン補完」みたいな基礎的な平滑化ですら、インフラが今ほど整っていなかったので、まぁ言ってしまえば「大学のような恵まれた場所でのみ簡単」というシロモノだったわけである。けれども、今は、はっきりいって「パソコンをお持ちの全国民」が、少しの学習と若干の手間さえかければ、(基礎となる理論等々への理解の有無によらず)実施できるようになった。そう、「誰でも」だ。老婆だろうが小学生だろうが、誰でもだ。この手段は「ワタシの場合は Python + Matplotlib」ということにはなるんだけれど、この道具に関しては色々選べる。MS Excel で出来ることも増えたし、フリーのものが良ければ、LibreOffice もかなり強力なことが出来る。(ちなみに 8割オジサンでお馴染みの西浦先生は R 使いらしい。)
というわけで、「言いたかった主たること」はもう大方言い尽くしたのではあるけれど、もう少しだけ「見える化の実現、のサンプル」を続けようかと。今回は感染拡大のステージングを素直に可視化しようとするとどうなるんだろね、てやつ。ただ、一般人が簡単にアクセス出来るデータで出来ることは限られてるので、出来ることだけを。
まずは、改めて(少し拡充したりもしてるので)データ取得:
1 # -*- coding: utf-8 -*-
2 import io
3 import sys
4 import csv
5 import datetime
6 import numpy as np
7
8
9 def _tonpa(fn):
10 # rownum=2020/1/16からの日数, colnum=都道府県コード-1
11 result = {
12 "newpat": np.zeros((1, 47)),
13 "newpatmovavg": np.zeros((1, 47)), # 週平均
14 "newpatmovavg2": np.zeros((1, 47)), # 2週平均
15 "newdeath": np.zeros((1, 47)),
16 "newdeathmovavg": np.zeros((1, 47)),
17 "newdeathmovavg2": np.zeros((1, 47)),
18 "effrepro": np.zeros((1, 47)), # 実効再生産数
19 }
20 era = "2020/1/16"
21 era = datetime.date(*map(int, era.split("/")))
22 reader = csv.reader(io.open(fn, encoding="utf-8-sig"))
23 next(reader)
24 for row in reader:
25 dt, (p, c, d) = row[0], map(int, row[1::2])
26 dt = (datetime.date(*map(int, dt.split("/"))) - era).days
27 if dt > len(result["newpat"]) - 1:
28 for k in result.keys():
29 result[k] = np.vstack((result[k], np.zeros((1, 47))))
30 result["newpat"][dt, p - 1] = c
31 result["newpatmovavg"][dt, p - 1] = result[
32 "newpat"][max(0, dt-6):dt+1, p - 1].mean()
33 result["newpatmovavg2"][dt, p - 1] = result[
34 "newpat"][max(0, dt-13):dt+1, p - 1].mean()
35 result["newdeath"][dt, p - 1] = d
36 result["newdeathmovavg"][dt, p - 1] = result[
37 "newdeath"][max(0, dt-6):dt+1, p - 1].mean()
38 result["newdeathmovavg2"][dt, p - 1] = result[
39 "newdeath"][max(0, dt-13):dt+1, p - 1].mean()
40 # 実効再生産数は、現京都大学西浦教授提案による簡易計算(を一般向け説明にまとめてくれ
41 # ている東洋経済ONLINE)より:
42 # (直近7日間の新規陽性者数/その前7日間の新規陽性者数)^(平均世代時間/報告間隔)
43 # 平均世代時間は=5日、報告間隔=7日の仮定。
44 # のつもりだが、東洋経済ONLINEで GitHub にて公開(閉鎖予定)されてる計算結果の csv とは
45 # 値が違う。違うことそのものは致し方ないこと。計算タイミングによって結果は変わるし、
46 # NHK まとめと東洋経済ONLINEのデータはシンクロしてないから。思いっきり間違ってるって
47 # ことはなさそう。近い値にはなってる。
48 for dt in range(len(result["newpat"])):
49 # 実効再生産数(都道府県別)
50 sum1 = result["newpat"][max(0, dt-6):dt+1, :].sum(axis=0)
51 sum2 = result["newpat"][max(0, dt-6-7):max(0, dt-6)+1, :].sum(axis=0)
52 result["effrepro"][dt, :] = np.power(sum1 / sum2, 5. / 7.)
53 np.savez(io.open("nhk_news_covid19_prefectures_daily_data.npz", "wb"), **result)
54
55
56 if __name__ == '__main__':
57 fn = "nhk_news_covid19_prefectures_daily_data.csv"
58 _tonpa(fn)
1 # -*- coding: utf-8-unix -*-
2 import io
3 import csv
4 import datetime
5 import numpy as np
6
7
8 _PREFCODE = {
9 '北海道': 1,
10 '青森県': 2,
11 '岩手県': 3,
12 '宮城県': 4,
13 '秋田県': 5,
14 '山形県': 6,
15 '福島県': 7,
16 '茨城県': 8,
17 '栃木県': 9,
18 '群馬県': 10,
19 '埼玉県': 11,
20 '千葉県': 12,
21 '東京都': 13,
22 '神奈川県': 14,
23 '新潟県': 15,
24 '富山県': 16,
25 '石川県': 17,
26 '福井県': 18,
27 '山梨県': 19,
28 '長野県': 20,
29 '岐阜県': 21,
30 '静岡県': 22,
31 '愛知県': 23,
32 '三重県': 24,
33 '滋賀県': 25,
34 '京都府': 26,
35 '大阪府': 27,
36 '兵庫県': 28,
37 '奈良県': 29,
38 '和歌山県': 30,
39 '鳥取県': 31,
40 '島根県': 32,
41 '岡山県': 33,
42 '広島県': 34,
43 '山口県': 35,
44 '徳島県': 36,
45 '香川県': 37,
46 '愛媛県': 38,
47 '高知県': 39,
48 '福岡県': 40,
49 '佐賀県': 41,
50 '長崎県': 42,
51 '熊本県': 43,
52 '大分県': 44,
53 '宮崎県': 45,
54 '鹿児島県': 46,
55 '沖縄県': 47,
56 }
57 _COLSNM = (
58 "testedPositive",
59 "peopleTested",
60 "hospitalized",
61 "serious",
62 "discharged",
63 "deaths",
64 "effectiveReproductionNumber",
65 )
66 def _tonpa(fn):
67 # 元データ prefectures.csv の著作権:
68 # 『東洋経済オンライン「新型コロナウイルス 国内感染の状況」制作:荻原和樹』
69 #
70 # 1. 開始日が NHK まとめと違う
71 # 2. 更新のない都道府県は省略してある
72 # 3. 日付は一応抜けなく連続している、今のところ
73 #
74 # NHKまとめのほうで密行列として扱った同じノリにしたい、ここでは面倒だけど。
75 # つまり、列方向に都道府県、行方向に日付。
76 result = {
77 k: np.zeros((1, 47))
78 for k in _COLSNM}
79 reader = csv.reader(io.open(fn, encoding="utf-8-sig"))
80 next(reader)
81 def _f(d):
82 if not d or d == "-":
83 # 不明とか未報告の意味だと思う。
84 return float("nan")
85 return float(d)
86
87 era = datetime.date(2020, 1, 16) # NHKまとめのほうの起点日
88 curdate = era
89 for line in reader:
90 date = datetime.date(*map(int, line[:3]))
91 dadv = (date - curdate).days
92 data = list(map(_f, line[5:]))
93 p = _PREFCODE[line[3]]
94 for i, k in enumerate(_COLSNM):
95 for _ in range(dadv):
96 result[k] = np.vstack((result[k], np.zeros((1, 47))))
97 result[k][-1, p - 1] = data[i]
98 curdate = date
99 # 東洋経済オンラインのデータ更新がおよそ一日遅く、ズレてると扱いにくいので、
100 # 末尾を埋めておく。
101 nhkdat = np.load(io.open("nhk_news_covid19_prefectures_daily_data.npz", "rb"))
102 days = len(nhkdat["newpat"])
103 for d in range(days - len(result[_COLSNM[0]])):
104 for i, k in enumerate(_COLSNM):
105 result[k] = np.vstack((result[k], np.full((1, 47), np.nan)))
106
107 # 元データについて、どうやら厚労省のオープンデータそのものを転記しただけの
108 # 項目は累積でのみ管理しているらしく、この csv 全体では「累積だったりそうで
109 # なかったり」と大変使いにくい。ゆえ、累積のものは読み替えておく。
110 for k in ("testedPositive", "peopleTested", "discharged", "deaths",):
111 result[k][1:] = (
112 result[k] - np.roll(result[k], 1, axis=0))[1:]
113 #
114 # peopleTested の最新2日分はゴミ:
115 # ---
116 # 2021,1,28,東京都,Tokyo, 97571, 1303823.0, 14957.0, 150, 81767.0, 847, 0.74
117 # 2021,1,29,東京都,Tokyo, 98439, 1309999.0, 13807.0, 147, 83768.0, 864, 0.76
118 # 2021,1,30,東京都,Tokyo, 99208, 1309999.0, 13383.0, 141, 84942.0, 883, 0.77
119 # 2021,1,31,東京都,Tokyo, 99841, 1309999.0, 13257.0, 140, 85698.0, 886, 0.78
120 # ---
121 # 集計が3日遅れ、てこと、だろう。
122 result["peopleTested"][np.where(result["peopleTested"] == 0.0)] = float("nan")
123 # 移動平均
124 for k in ("testedPositive", "peopleTested", "hospitalized", "serious", "deaths"):
125 k1, k2 = k, k + "_movavg"
126 result[k2] = np.zeros(result[k1].shape)
127 for dt in range(len(result[k1])):
128 #result[k2][dt, :] = result[k1][
129 # max(0, dt - 6):dt + 1, :].mean(axis=0)
130 result[k2][dt, :] = np.nanmean(result[k1][
131 max(0, dt - 6):dt + 1, :], axis=0)
132 #
133 np.savez(io.open("toyokeizai_online_covid19.npz", "wb"), **result)
134
135
136 if __name__ == '__main__':
137 _tonpa("prefectures.csv")
で、人口比の計算に必要なデータ:
1 1 東京都 13000-1 13,515,271 13,960,236 +3.29 2021年1月1日
2 2 神奈川県 14000-7 9,126,214 9,216,009 +0.98 2020年9月1日
3 3 大阪府 27000-8 8,839,469 8,815,082 -0.28 2020年11月1日
4 4 愛知県 23000-6 7,483,128 7,538,701 +0.74 2020年11月1日
5 5 埼玉県 11000-1 7,266,534 7,342,682 +1.05 2020年12月1日
6 6 千葉県 12000-6 6,222,666 6,281,869 +0.95 2021年1月1日
7 7 兵庫県 28000-3 5,534,800 5,434,645 -1.81 2021年1月1日
8 8 北海道 01000-6 5,381,733 5,231,685 -2.79 2020年11月30日
9 9 福岡県 40000-9 5,101,556 5,108,038 +0.13 2020年9月1日
10 10 静岡県 22000-1 3,700,305 3,613,788 -2.34 2021年1月1日
11 11 茨城県 08000-4 2,916,976 2,852,499 -2.21 2021年1月1日
12 12 広島県 34000-6 2,843,990 2,793,470 -1.78 2020年11月1日
13 13 京都府 26000-2 2,610,353 2,566,341 -1.69 2021年1月1日
14 14 宮城県 04000-2 2,333,899 2,290,915 -1.84 2021年1月1日
15 15 新潟県 15000-2 2,304,264 2,195,068 -4.74 2021年1月1日
16 16 長野県 20000-0 2,098,804 2,031,795 -3.19 2021年1月1日
17 17 岐阜県 21000-5 2,031,903 1,975,397 -2.78 2020年9月1日
18 18 栃木県 09000-0 1,974,255 1,930,000 -2.24 2021年1月1日
19 19 群馬県 10000-5 1,973,115 1,924,116 -2.48 2021年1月1日
20 20 岡山県 33000-1 1,921,525 1,880,772 -2.12 2021年1月1日
21 21 福島県 07000-9 1,914,039 1,820,949 -4.86 2021年1月1日
22 22 三重県 24000-1 1,815,865 1,768,632 -2.60 2020年9月1日
23 23 熊本県 43000-5 1,786,170 1,734,231 -2.91 2021年1月1日
24 24 鹿児島県 46000-1 1,648,177 1,587,785 -3.66 2021年1月1日
25 25 沖縄県 47000-7 1,433,566 1,460,427 +1.87 2021年1月1日
26 26 滋賀県 25000-7 1,412,916 1,412,095 -0.06 2021年1月1日
27 27 山口県 35000-1 1,404,729 1,339,003 -4.68 2021年1月1日
28 28 愛媛県 38000-8 1,385,262 1,323,851 -4.43 2021年1月1日
29 29 長崎県 42000-0 1,377,187 1,308,277 -5.00 2021年1月1日
30 30 奈良県 29000-9 1,364,316 1,321,250 -3.16 2021年1月1日
31 31 青森県 02000-1 1,308,265 1,228,730 -6.08 2020年12月1日
32 32 岩手県 03000-7 1,279,594 1,209,457 -5.48 2021年1月1日
33 33 大分県 44000-1 1,166,338 1,124,309 -3.60 2020年11月1日
34 34 石川県 17000-3 1,154,008 1,129,362 -2.14 2020年12月1日
35 35 山形県 06000-3 1,123,891 1,062,239 -5.49 2021年1月1日
36 36 宮崎県 45000-6 1,104,069 1,062,180 -3.79 2021年1月1日
37 37 富山県 16000-8 1,066,328 1,033,981 -3.03 2020年11月1日
38 38 秋田県 05000-8 1,023,119 948,964 -7.25 2021年1月1日
39 39 香川県 37000-2 976,263 949,357 -2.76 2020年9月1日
40 40 和歌山県 30000-4 963,579 912,364 -5.32 2021年1月1日
41 41 山梨県 19000-4 834,930 805,339 -3.54 2021年1月1日
42 42 佐賀県 41000-4 832,832 808,074 -2.97 2021年1月1日
43 43 福井県 18000-9 786,740 762,272 -3.11 2020年11月1日
44 44 徳島県 36000-7 755,733 721,721 -4.50 2020年9月1日
45 45 高知県 39000-3 728,276 688,583 -5.45 2021年1月1日
46 46 島根県 32000-5 694,352 665,702 -4.13 2021年1月1日
47 47 鳥取県 31000-0 573,441 550,651 -3.97 2021年1月1日
の上で、「10万人当たりの新規感染者数に基づくステージング」:
1 # -*- coding: utf-8-unix -*-
2 import io
3 import csv
4 import datetime
5 import numpy as np
6 import matplotlib.pyplot as plt
7 import matplotlib.font_manager
8 import matplotlib.ticker as ticker
9 from matplotlib.colors import BoundaryNorm
10
11
12 _PREFCODE = {
13 '北海道': 1,
14 '青森県': 2,
15 '岩手県': 3,
16 '宮城県': 4,
17 '秋田県': 5,
18 '山形県': 6,
19 '福島県': 7,
20 '茨城県': 8,
21 '栃木県': 9,
22 '群馬県': 10,
23 '埼玉県': 11,
24 '千葉県': 12,
25 '東京都': 13,
26 '神奈川県': 14,
27 '新潟県': 15,
28 '富山県': 16,
29 '石川県': 17,
30 '福井県': 18,
31 '山梨県': 19,
32 '長野県': 20,
33 '岐阜県': 21,
34 '静岡県': 22,
35 '愛知県': 23,
36 '三重県': 24,
37 '滋賀県': 25,
38 '京都府': 26,
39 '大阪府': 27,
40 '兵庫県': 28,
41 '奈良県': 29,
42 '和歌山県': 30,
43 '鳥取県': 31,
44 '島根県': 32,
45 '岡山県': 33,
46 '広島県': 34,
47 '山口県': 35,
48 '徳島県': 36,
49 '香川県': 37,
50 '愛媛県': 38,
51 '高知県': 39,
52 '福岡県': 40,
53 '佐賀県': 41,
54 '長崎県': 42,
55 '熊本県': 43,
56 '大分県': 44,
57 '宮崎県': 45,
58 '鹿児島県': 46,
59 '沖縄県': 47,
60 }
61 def _vis(dattko):
62 reader = csv.reader(io.open("pp.txt", encoding="cp932"), delimiter="\t")
63 fac = []
64 for row in reader:
65 fac.append((_PREFCODE[row[1]], int(row[4].replace(",", ""))))
66 fac.sort()
67 fac = np.array([(100000. / n) for pc, n in fac]) #10万人換算
68 #fac = np.array([(fac[12][1] / n) for pc, n in fac]) #東京換算
69 #
70 era = datetime.date(2020, 1, 16)
71 #
72 fontprop = matplotlib.font_manager.FontProperties(
73 fname="c:/Windows/Fonts/meiryo.ttc")
74
75 era = "2020/1/16" # 木曜日
76 era = datetime.date(*map(int, era.split("/")))
77 #
78 k, kt = "testedPositive_movavg", "新規陽性者数(10万人あたり)"
79 #k, kt = "hospitalized", "入院治療等を要する者(10万人あたり)"
80 #k, kt = "deaths", "死者数(10万人あたり)"
81 #k, kt = "serious_movavg", "重症者数(10万人あたり)"
82 #k, kt = "serious", "重症者数(10万人あたり)"
83 #
84 skip = 7*4*7
85 Z = dattko[k] * fac
86 Z = Z[skip:]
87 Z[np.where(np.isnan(Z))] = 0
88 #
89 T = np.array([era + datetime.timedelta(t + skip) for t in range(len(Z))])
90 Y = np.arange(48)
91 X, Y = np.meshgrid(T, Y)
92 #
93 fig, ax1 = plt.subplots(tight_layout=True)
94 fig.set_size_inches(16.53 * 1.2, 11.69)
95 ax1.invert_yaxis()
96 ax1.tick_params(labelright=True)
97 ax1.yaxis.set_major_formatter(
98 ticker.FuncFormatter(
99 lambda x, pos=None: {
100 pc: pn for (pn, pc) in _PREFCODE.items()}.get(x + 1, "")))
101 for lab in ax1.get_yticklabels():
102 lab.set_fontproperties(fontprop)
103 CS = ax1.pcolor(
104 X, Y, Z.T * 7,
105 norm=BoundaryNorm([0, 15, 25, 50], 400), cmap="coolwarm")
106 ax1.set_yticks(range(47))
107
108 cbar = fig.colorbar(CS)
109 ax1.grid(True)
110 ax1.set_xlabel(
111 "{}\n「東洋経済オンライン「新型コロナウイルス 国内感染の状況」」を加工".format(kt),
112 fontproperties=fontprop)
113
114 fig.savefig("{}_per100000_{}.png".format(k, str(T[-1])))
115 plt.close(fig)
116
117
118 if __name__ == '__main__':
119 _vis(np.load(io.open("toyokeizai_online_covid19.npz", "rb")))
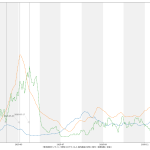
Matplotlib の実例としては「BoundaryNorm例」のつもり。最新データを使うとこんな絵になる:
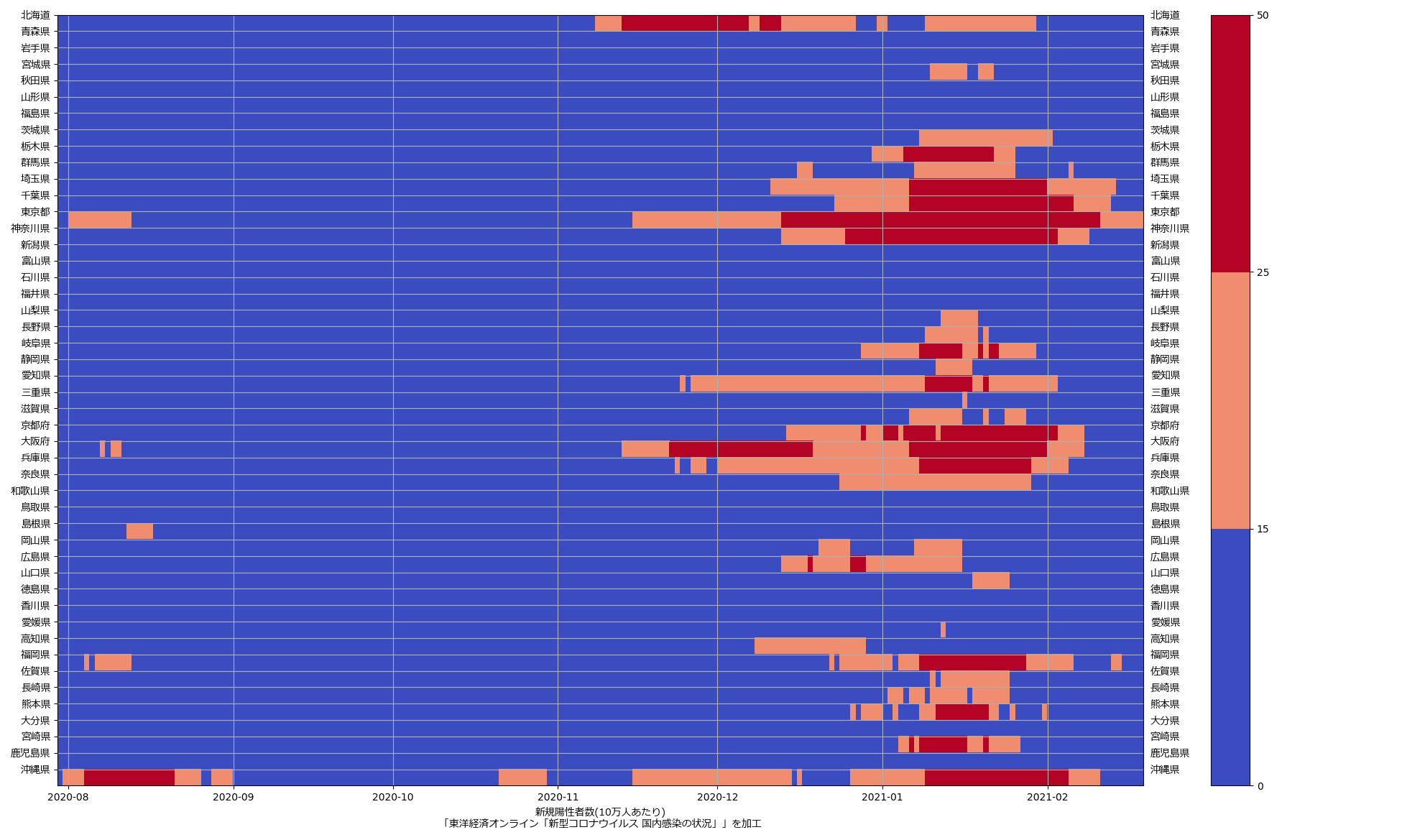
東京がステージ3基準、大阪がステージ2基準になってるのがわかるだろう。(なお大阪問題に関しては、ワタシはこれまで主張してきた通り、重傷者数と死者数の減りが非常に鈍くいまだにワーストな点から、大阪だけ先走っていいという意見には素直に賛成出来るわけではなく「判断が難しいところ」と思ってる。)
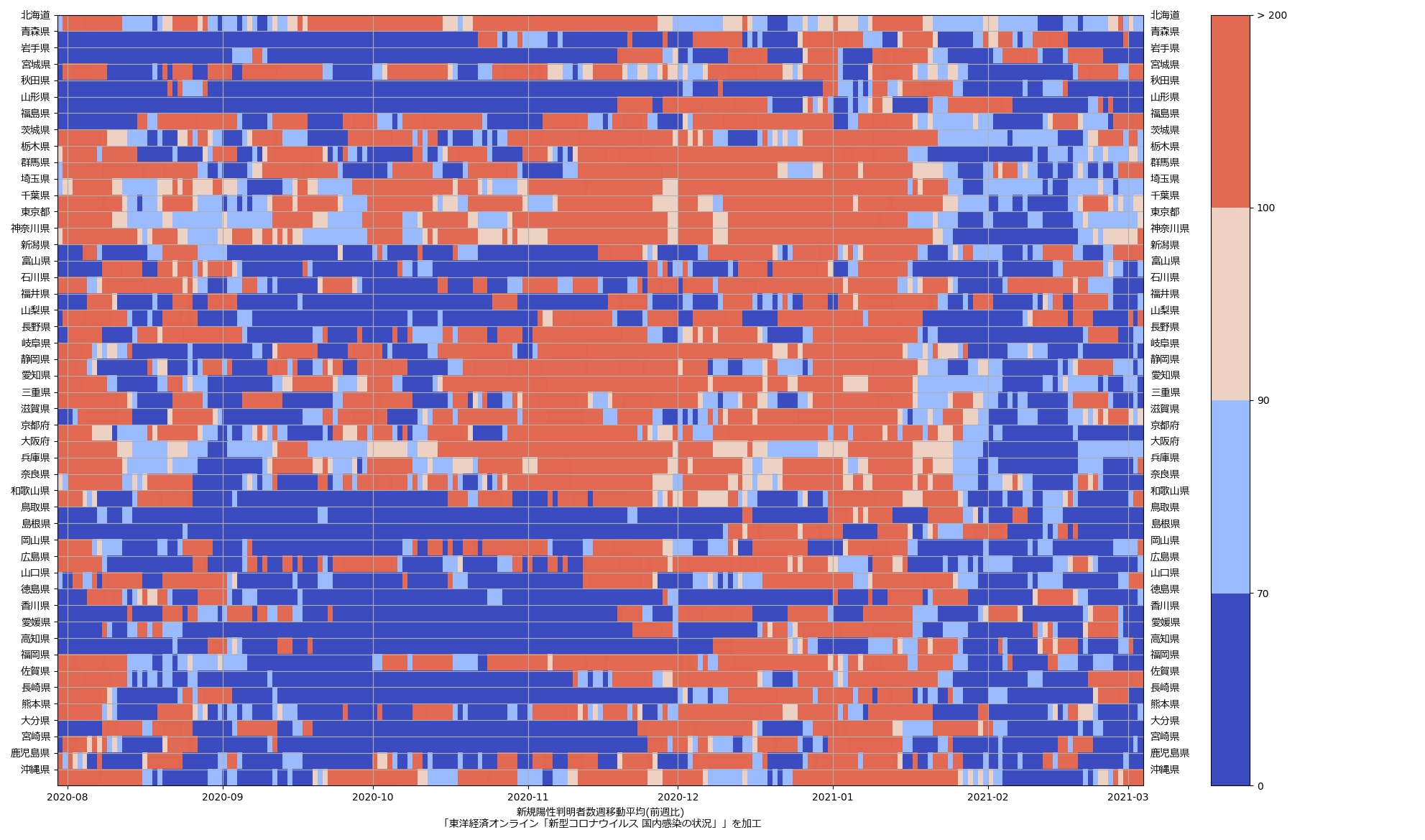
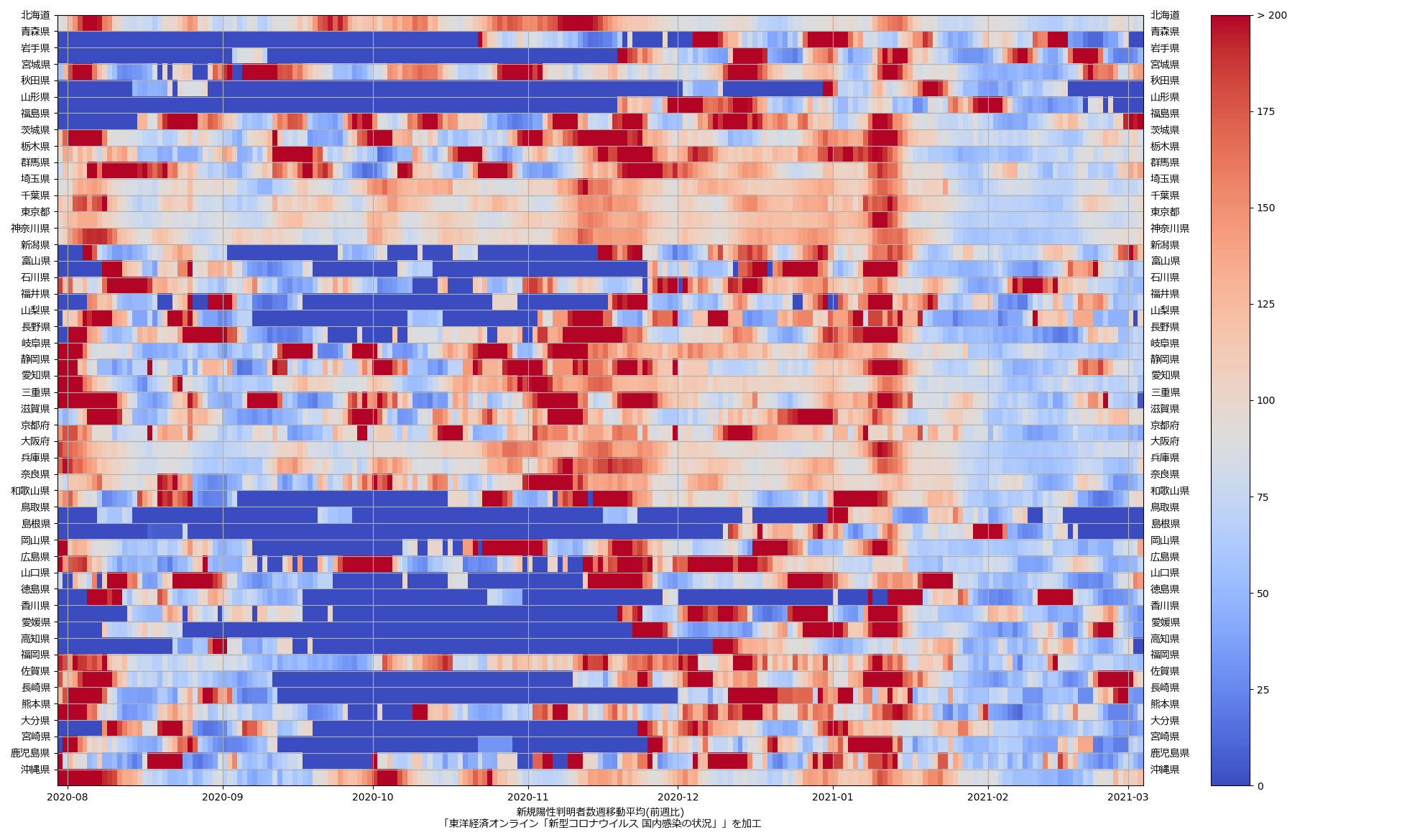
もう一つは、「ステージング」には直結出来ないんだけれど、そのステージングの指標の一つの「前週比」を可視化したらどんななんだろうかと、やってみた:
1 # -*- coding: utf-8-unix -*-
2 import io
3 import datetime
4 import numpy as np
5 import matplotlib.pyplot as plt
6 import matplotlib.font_manager
7 import matplotlib.ticker as ticker
8 from matplotlib.colors import BoundaryNorm
9
10
11 _PREFCODE = {
12 '北海道': 1,
13 '青森県': 2,
14 '岩手県': 3,
15 '宮城県': 4,
16 '秋田県': 5,
17 '山形県': 6,
18 '福島県': 7,
19 '茨城県': 8,
20 '栃木県': 9,
21 '群馬県': 10,
22 '埼玉県': 11,
23 '千葉県': 12,
24 '東京都': 13,
25 '神奈川県': 14,
26 '新潟県': 15,
27 '富山県': 16,
28 '石川県': 17,
29 '福井県': 18,
30 '山梨県': 19,
31 '長野県': 20,
32 '岐阜県': 21,
33 '静岡県': 22,
34 '愛知県': 23,
35 '三重県': 24,
36 '滋賀県': 25,
37 '京都府': 26,
38 '大阪府': 27,
39 '兵庫県': 28,
40 '奈良県': 29,
41 '和歌山県': 30,
42 '鳥取県': 31,
43 '島根県': 32,
44 '岡山県': 33,
45 '広島県': 34,
46 '山口県': 35,
47 '徳島県': 36,
48 '香川県': 37,
49 '愛媛県': 38,
50 '高知県': 39,
51 '福岡県': 40,
52 '佐賀県': 41,
53 '長崎県': 42,
54 '熊本県': 43,
55 '大分県': 44,
56 '宮崎県': 45,
57 '鹿児島県': 46,
58 '沖縄県': 47,
59 }
60 def _vis(dattko):
61 #
62 era = datetime.date(2020, 1, 16)
63 #
64 fontprop = matplotlib.font_manager.FontProperties(
65 fname="c:/Windows/Fonts/meiryo.ttc")
66
67 era = "2020/1/16" # 木曜日
68 era = datetime.date(*map(int, era.split("/")))
69 #
70 k, subj = "testedPositive_movavg", "新規陽性判明者数週移動平均"
71 #
72 skip = 7*4*7
73 Z = dattko[k]
74 # 「前週比」の計算で、分母が1未満だと発散してウザいので、シンプルに1としておく。
75 Z[np.where(Z < 1)] = 1
76 Z /= np.roll(Z, 7, axis=0)
77 Z *= 100
78 Z = Z[skip:]
79 Z[np.where(np.isnan(Z))] = 0
80 #
81 T = np.array([era + datetime.timedelta(t + skip) for t in range(len(Z))])
82 Y = np.arange(48)
83 X, Y = np.meshgrid(T, Y)
84 #
85 fig, ax1 = plt.subplots(tight_layout=True)
86 fig.set_size_inches(16.53 * 1.2, 11.69)
87
88 ax1.invert_yaxis()
89 ax1.tick_params(labelright=True)
90 ax1.yaxis.set_major_formatter(
91 ticker.FuncFormatter(
92 lambda x, pos=None: {
93 pc: pn for (pn, pc) in _PREFCODE.items()}.get(x + 1, "")))
94 for lab in ax1.get_yticklabels():
95 lab.set_fontproperties(fontprop)
96 #
97 norm = BoundaryNorm([0, 70, 90, 100, 200], 220)
98 CS1 = ax1.pcolor(X, Y, Z.T, norm=norm, cmap="coolwarm")
99 ax1.set_yticks(range(47))
100 cbar1 = fig.colorbar(CS1)
101 ax1.set_xlabel(
102 "{}({})\n「東洋経済オンライン「新型コロナウイルス 国内感染の状況」」を加工".format(
103 subj, "前週比"),
104 fontproperties=fontprop)
105 ax1.grid(True)
106 fig.savefig("{}_{}_{}.png".format(k, "cpw", str(T[-1])))
107 #plt.show()
108 plt.close(fig)
109
110
111 if __name__ == '__main__':
112 _vis(np.load(io.open("toyokeizai_online_covid19.npz", "rb")))
これも最新データだとこんな絵:
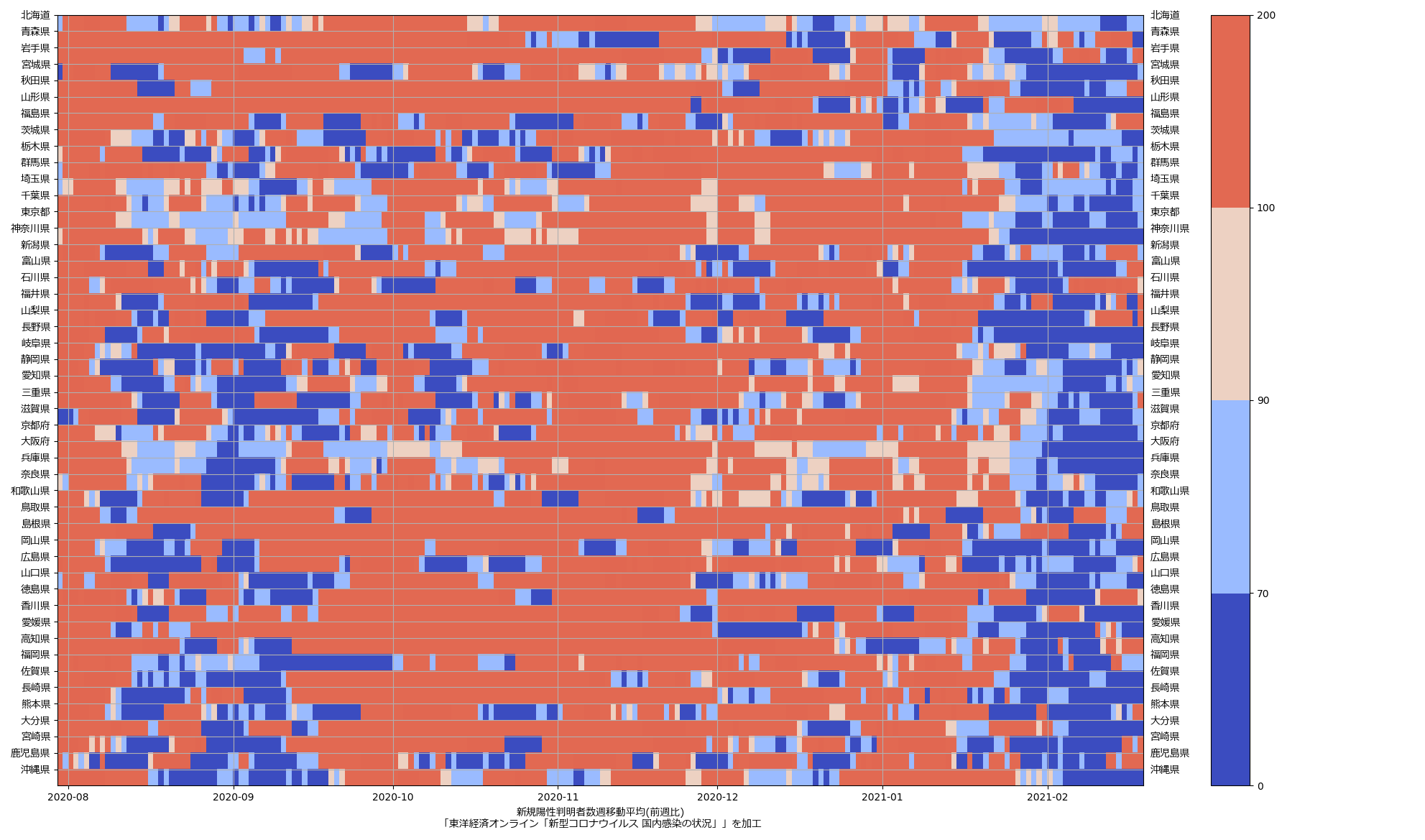
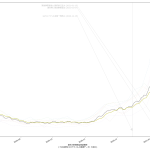
まぁさすがにこれは「こういう質の良い見える化をしたらいいのに」とは言えんね、わかりやすいとは思えん。が、まぁ全体の傾向を一瞥するのには悪くないかもしれんね、今まさに「下がっていってる最中」だということが、最近の「真っ青っぷり」で表現出来てる。
「倍加時間」もしくは実効再生産数を計算して推定するのと「前週比」を計算するのは、「過去履歴の傾き」を見ることなので、本質的にはほとんど同じ意味。正直ワタシ的には「やってみた」以上の意味はないのだが、なんというか、この「前週比」を指標にしてるのって、「理解しやすさ」以上の意味があるんだろうか、って思う。しかも「1倍 or not」って、ラフ過ぎるだろ、と。
ほんとはさぁ…、「老婆でも小学生でも」の主張のために、道具を Python + Matplotlib に縛らずに、たとえば Google Drive のワークシートを使うとか、LibreOffice でやるならどんなだとか、あるいは「お仕事としてこういうことをしなければならない人」向けには、WEB で(つまりおそらく javascript で)実現する方法、とかも示せたら良かったのかもしれない、とはずっと思ってるんだよね。まぁ、気が向いたらそっち方面もやってみるかもしれないし、やらないかもしれない。「猿でも出来る」わけではないからね、学習と手間は必要だ、そのための情報を提供できるスキルがワタシにあるのならば、それを伝えるのにはやぶさかではない。
2021-02-21追記:
こういうのはつきものだし、どういう場合であっても「単一の指標だけで判断することは危険」なのだとはいえ、前週比のほう、「一人が一人になりました、前週比1未満を満たしておらず危険ですきゃー」となっちゃってる見せ方はさすがにヒド過ぎるよな、と。「Z[np.where(Z < 1)] = 1」としてただけの部分を以下のように:
1 # 1.「100%」となるケースにおいて、純然たるゴミといえるパターン:
2 # 前週も今週も(限りなく)0
3 # このケースは「無意味」ということで nan としておく。としないと、まったく問題が
4 # ない「一人が一人になった!」として「前週比1倍未満ではない」ものとしてピックアップ
5 # することになり、馬鹿げている。
6 # 2.「前週比」の計算で、分母が1未満だと発散してウザいので、シンプルに1としておく。
7 Z[np.where(np.logical_and(Z < 1, np.roll(Z, 7, axis=0) < 1))] = np.nan
8 Z[np.where(Z < 1)] = 1
とするといいかなと:
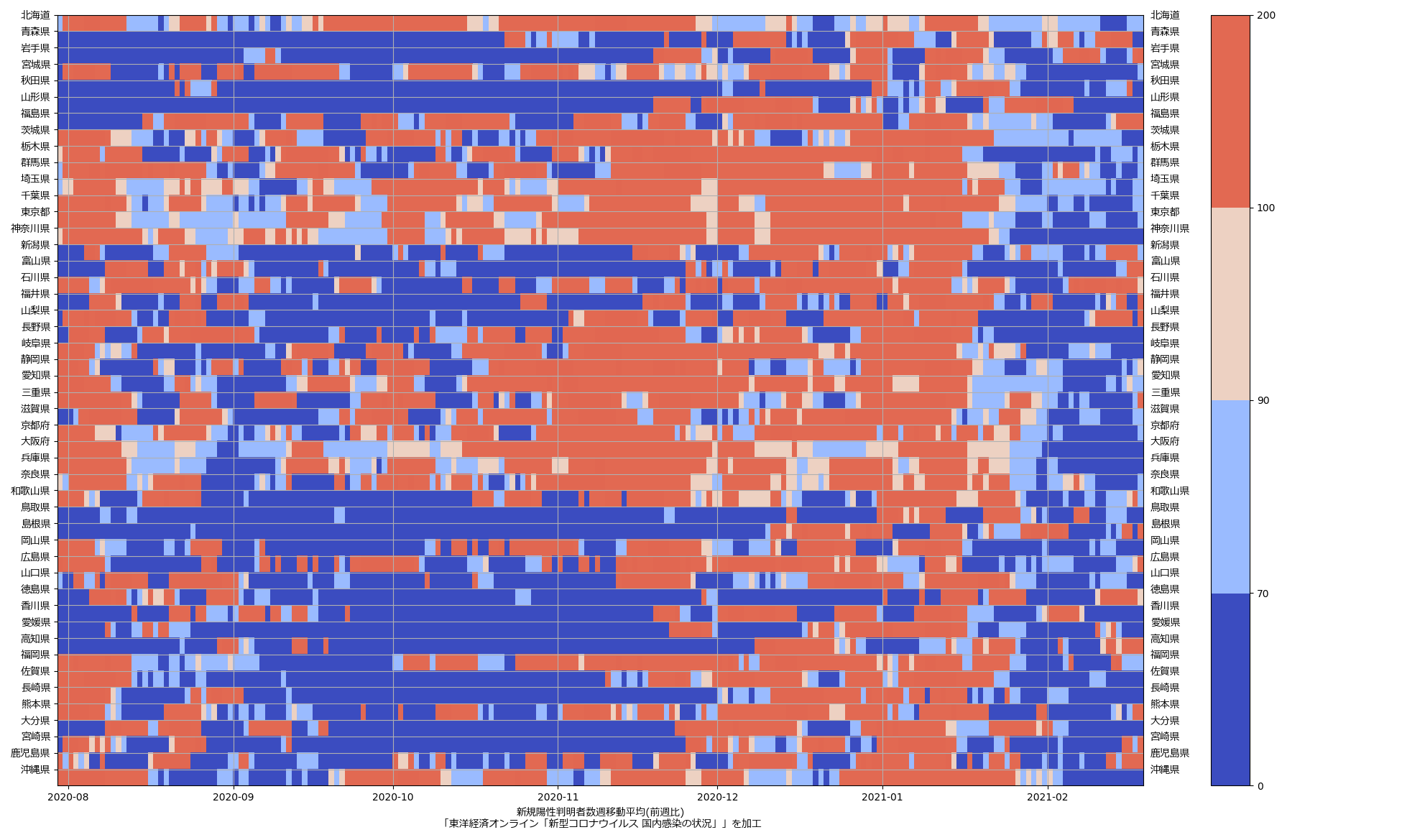
狼少年的になっちゃうのが一番よくないんだよね、こういうのって。
2021-02-22追記:
「人口比 (3?)」への追記というよりは(2)、(1)への追記としてのほうが相応しいのかもしれんけれど:
1 # -*- coding: utf-8-unix -*-
2 import io
3 import datetime
4 import numpy as np
5 import matplotlib.pyplot as plt
6 import matplotlib.font_manager
7 import matplotlib.ticker as ticker
8 from matplotlib.colors import LogNorm, PowerNorm, LightSource
9
10
11 _PREFCODE = {
12 '北海道': 1,
13 '青森県': 2,
14 '岩手県': 3,
15 '宮城県': 4,
16 '秋田県': 5,
17 '山形県': 6,
18 '福島県': 7,
19 '茨城県': 8,
20 '栃木県': 9,
21 '群馬県': 10,
22 '埼玉県': 11,
23 '千葉県': 12,
24 '東京都': 13,
25 '神奈川県': 14,
26 '新潟県': 15,
27 '富山県': 16,
28 '石川県': 17,
29 '福井県': 18,
30 '山梨県': 19,
31 '長野県': 20,
32 '岐阜県': 21,
33 '静岡県': 22,
34 '愛知県': 23,
35 '三重県': 24,
36 '滋賀県': 25,
37 '京都府': 26,
38 '大阪府': 27,
39 '兵庫県': 28,
40 '奈良県': 29,
41 '和歌山県': 30,
42 '鳥取県': 31,
43 '島根県': 32,
44 '岡山県': 33,
45 '広島県': 34,
46 '山口県': 35,
47 '徳島県': 36,
48 '香川県': 37,
49 '愛媛県': 38,
50 '高知県': 39,
51 '福岡県': 40,
52 '佐賀県': 41,
53 '長崎県': 42,
54 '熊本県': 43,
55 '大分県': 44,
56 '宮崎県': 45,
57 '鹿児島県': 46,
58 '沖縄県': 47,
59 }
60
61
62 def _get_scales():
63 import csv
64 reader = csv.reader(io.open("pp.txt", encoding="cp932"), delimiter="\t")
65 fac = []
66 for row in reader:
67 fac.append((_PREFCODE[row[1]], int(row[4].replace(",", ""))))
68 fac.sort()
69 return (
70 (lambda z: z, "", ""),
71 (lambda z: z * np.array([(100000. / n) for pc, n in fac]), "(10万人換算)", "_per100000"),
72 (lambda z: z * np.array([(fac[12][1] / n) for pc, n in fac]), "(東京換算)", "_asTokyo"),
73 (lambda z: z / np.nanmax(z, axis=0), "(都道府県ごと最大値との比)", "_emphPeaks"),
74 )
75
76
77 def _vis(dattko):
78 scales = _get_scales()
79 #
80 era = datetime.date(2020, 1, 16)
81 #
82 fontprop = matplotlib.font_manager.FontProperties(
83 fname="c:/Windows/Fonts/meiryo.ttc")
84
85 era = "2020/1/16" # 木曜日
86 era = datetime.date(*map(int, era.split("/")))
87 #
88 skip = 7*4*8 + 7*2
89 jmeanings = {
90 "testedPositive": "新規陽性者数",
91 "testedPositive_movavg": "新規陽性者数7日移動平均",
92 "hospitalized": "入院治療等を要する者",
93 "hospitalized_movavg": "入院治療等を要する者7日移動平均",
94 "serious": "重症者数",
95 "serious_movavg": "重症者数7日移動平均",
96 "deaths": "死者数",
97 "deaths_movavg": "死者数7日移動平均",
98 }
99 #
100 for i, (k0, fac, norm) in enumerate((
101 ("serious", scales[0], PowerNorm(0.4)),
102 ("serious", scales[1], PowerNorm(0.4)),
103 ("serious", scales[2], PowerNorm(0.4)),
104 ("serious", scales[3], PowerNorm(3)),
105 ("deaths", scales[0], PowerNorm(0.4)),
106 ("deaths", scales[1], PowerNorm(0.4)),
107 ("deaths", scales[2], PowerNorm(0.4)),
108 ("deaths", scales[3], PowerNorm(3)),
109 ("hospitalized", scales[0], PowerNorm(0.4)),
110 ("hospitalized", scales[1], PowerNorm(0.4)),
111 ("hospitalized", scales[2], PowerNorm(0.4)),
112 ("hospitalized", scales[3], PowerNorm(3)),
113 )):
114 for k in (k0, k0 + "_movavg"):
115 Z = fac[0](dattko[k])
116 Z = Z[skip:]
117 Z[np.where(np.isnan(Z))] = 0
118 Z[np.where(Z < 0)] = 0
119 T = np.array([era + datetime.timedelta(t + skip) for t in range(len(Z))])
120 Y = np.arange(48)
121 #
122 X, Y = np.meshgrid(T, Y)
123 #
124 fig, ax1 = plt.subplots(tight_layout=True)
125 fig.set_size_inches(16.53 * 1.2, 11.69)
126
127 ax1.invert_yaxis()
128 ax1.tick_params(labelright=True)
129 ax1.yaxis.set_major_formatter(
130 ticker.FuncFormatter(
131 lambda x, pos=None: {pc: pn for (pn, pc) in _PREFCODE.items()}.get(x + 1, "")))
132 for lab in ax1.get_yticklabels():
133 lab.set_fontproperties(fontprop)
134 #
135 CS1 = ax1.pcolor(X, Y, Z.T, norm=norm, cmap="coolwarm")
136 ax1.set_yticks(range(47))
137 cbar1 = fig.colorbar(CS1)
138 ax1.set_xlabel(
139 "{}{}\n「東洋経済オンライン「新型コロナウイルス 国内感染の状況」」を加工".format(
140 jmeanings[k], fac[1]),
141 fontproperties=fontprop)
142 ax1.grid(True)
143 fig.savefig("{}{}_{}.png".format(k, fac[2], str(T[-1])))
144 #plt.show()
145 plt.close(fig)
146
147
148 if __name__ == '__main__':
149 _vis(np.load(io.open("toyokeizai_online_covid19.npz", "rb")))
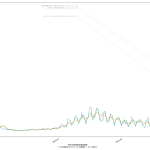
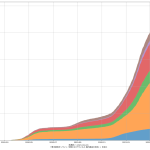
色んな指標ごとに都度都度やってたらダルくなってきて、の、少しだけ整理したヤツね。最新データを使えばこんな絵になる:
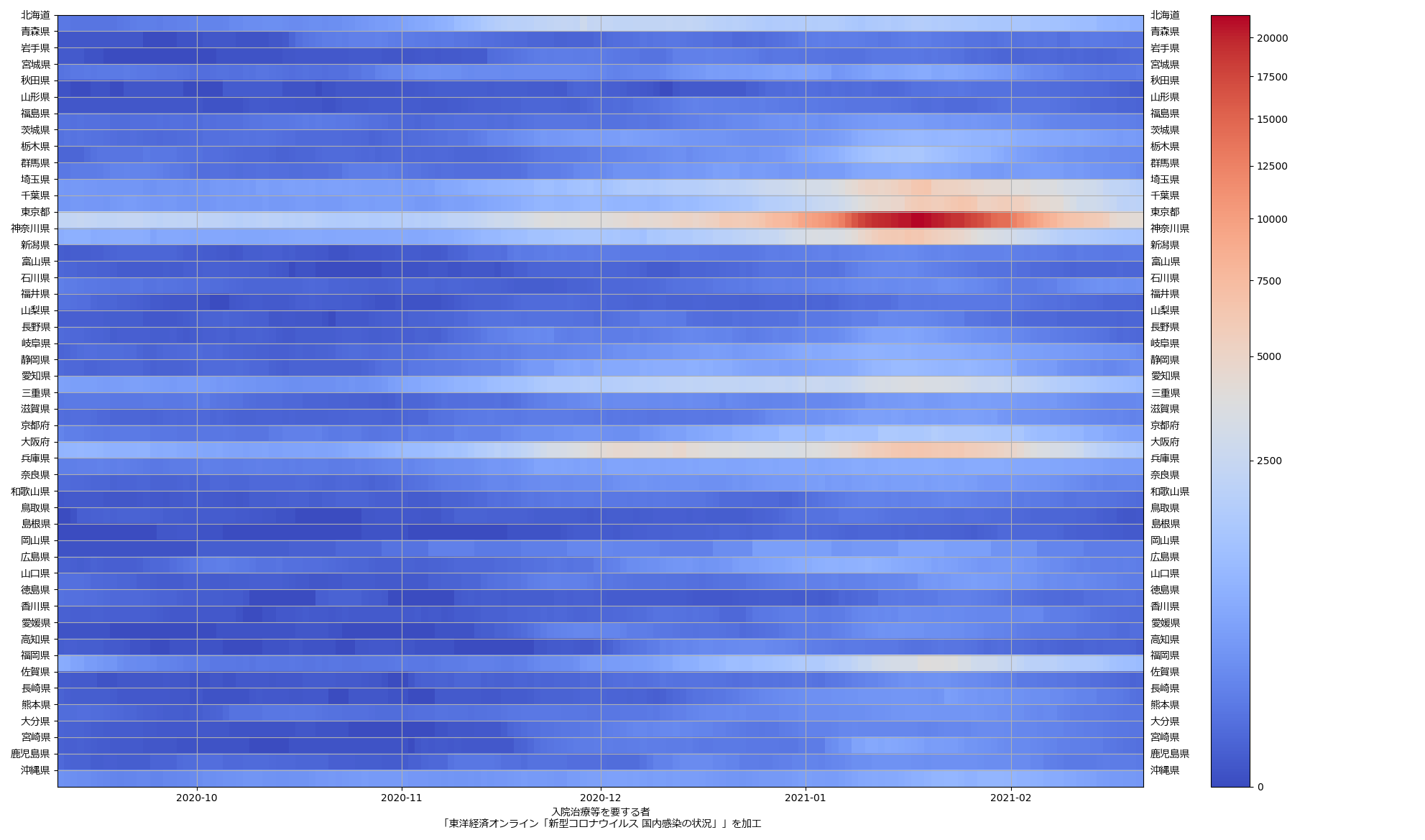
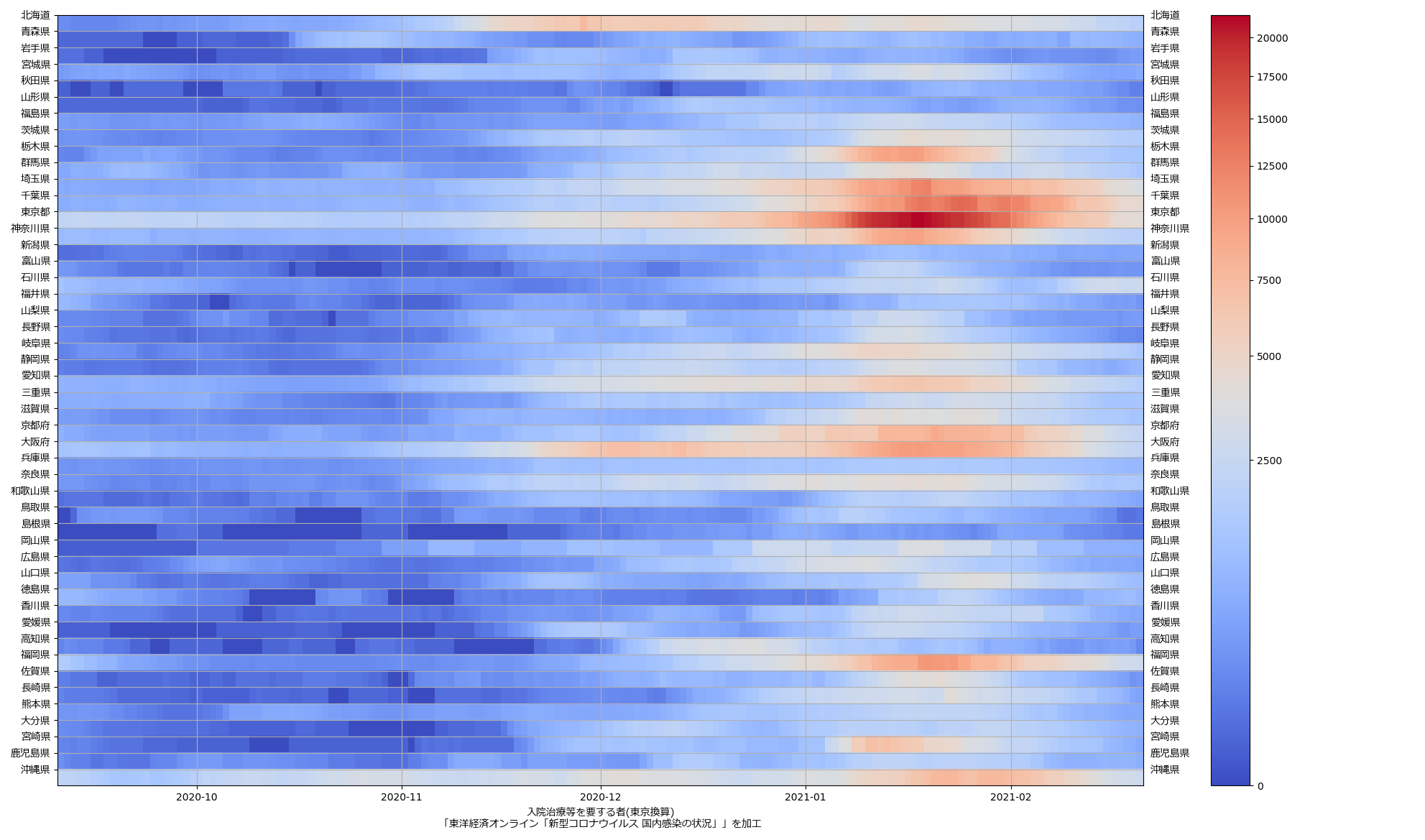
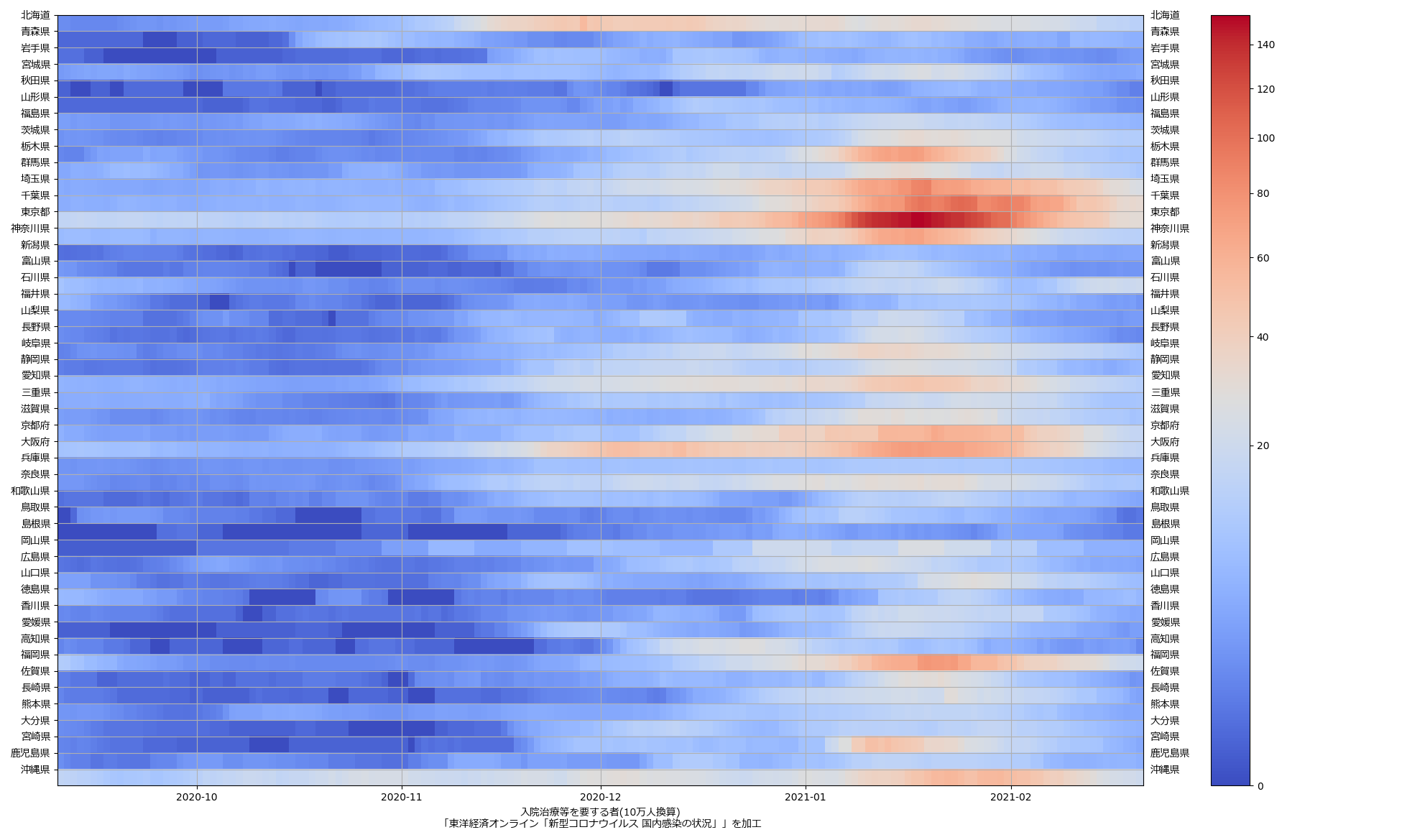
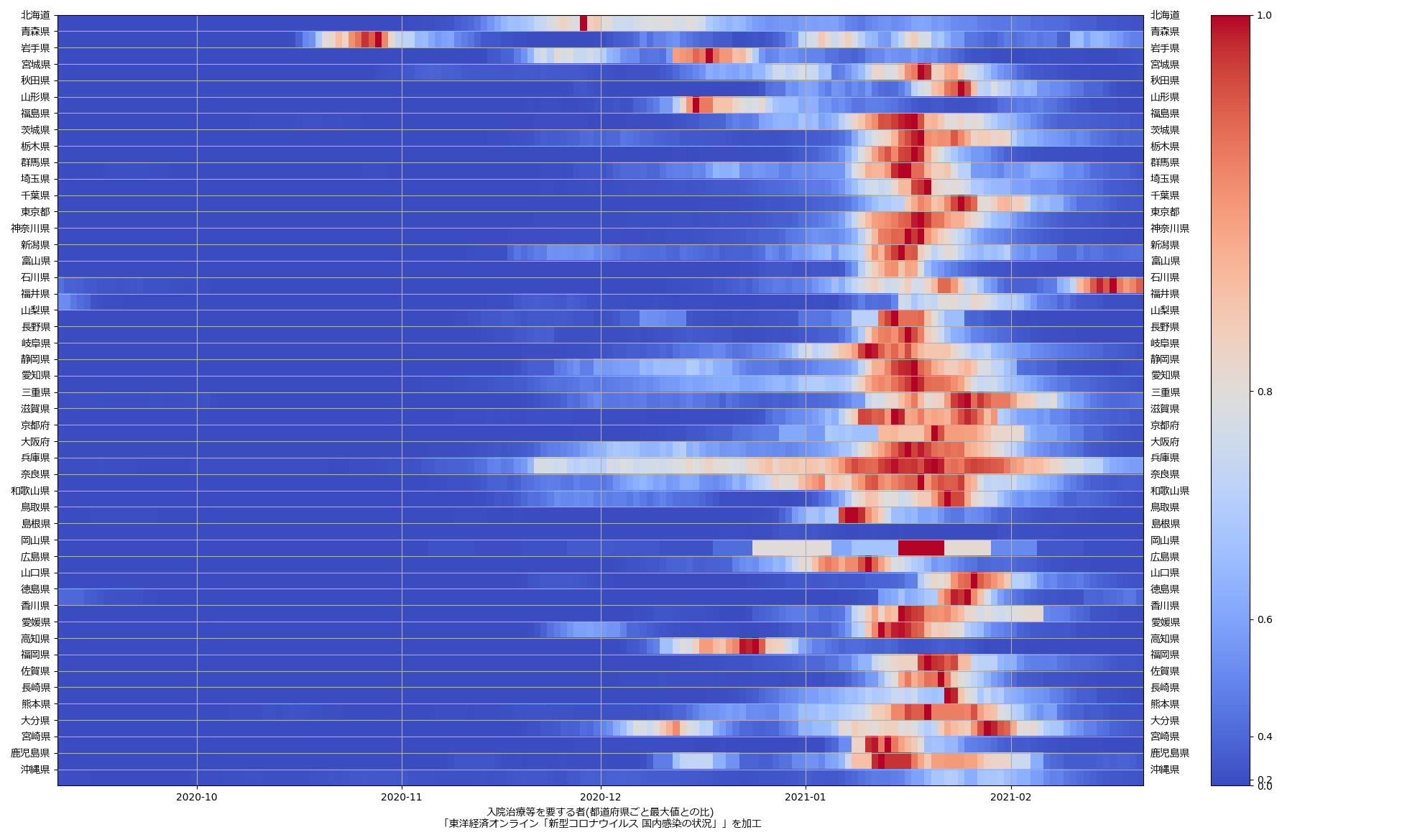
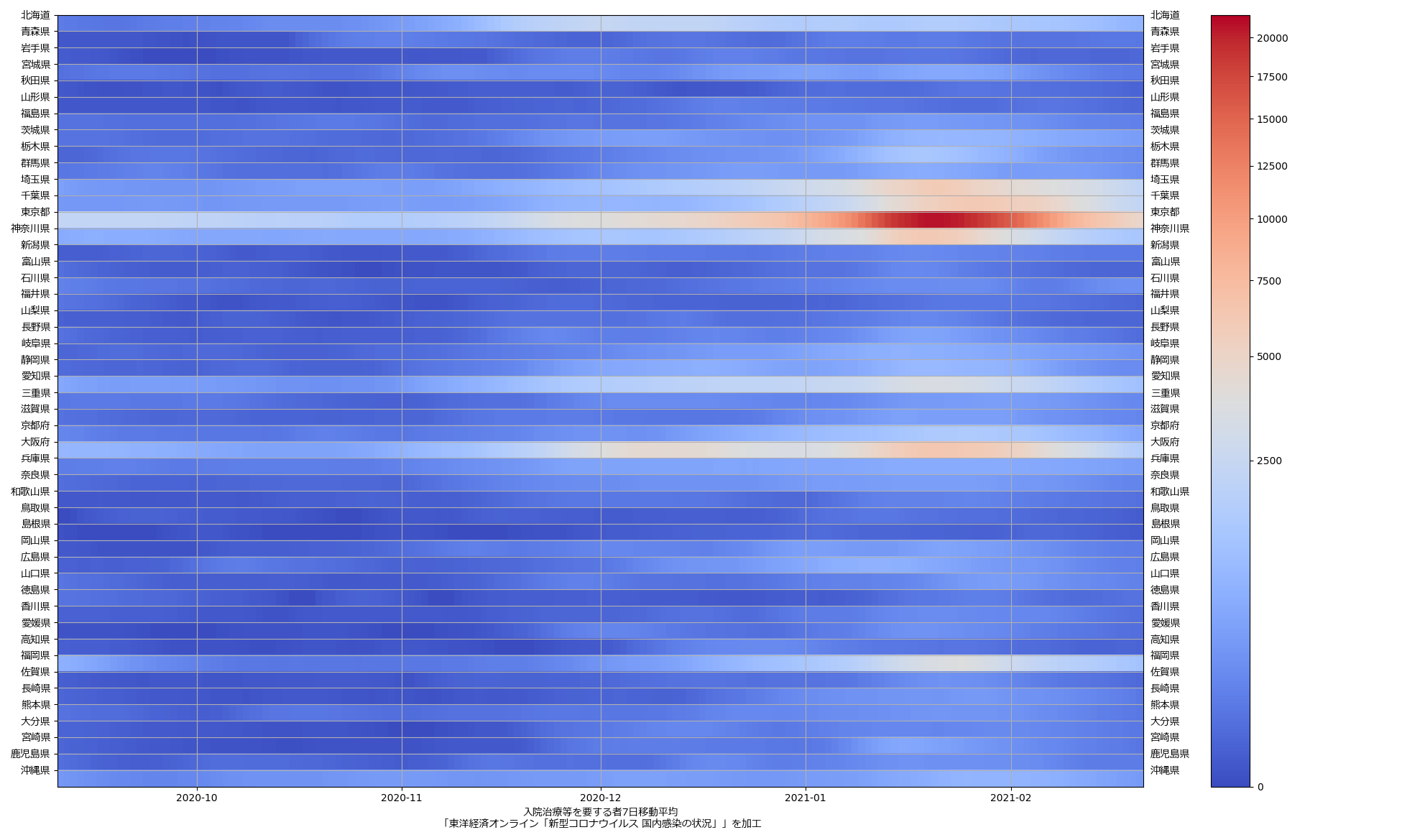
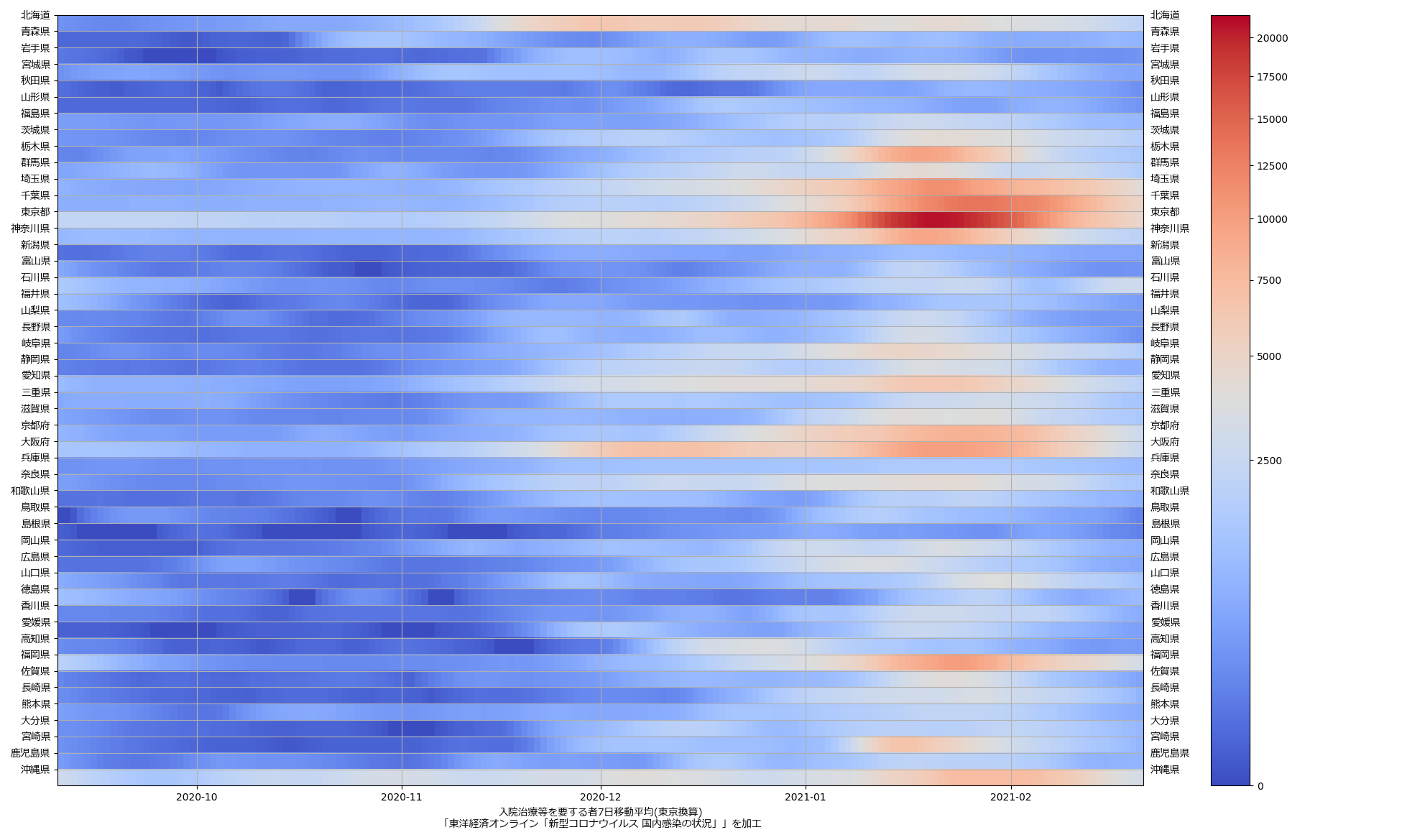
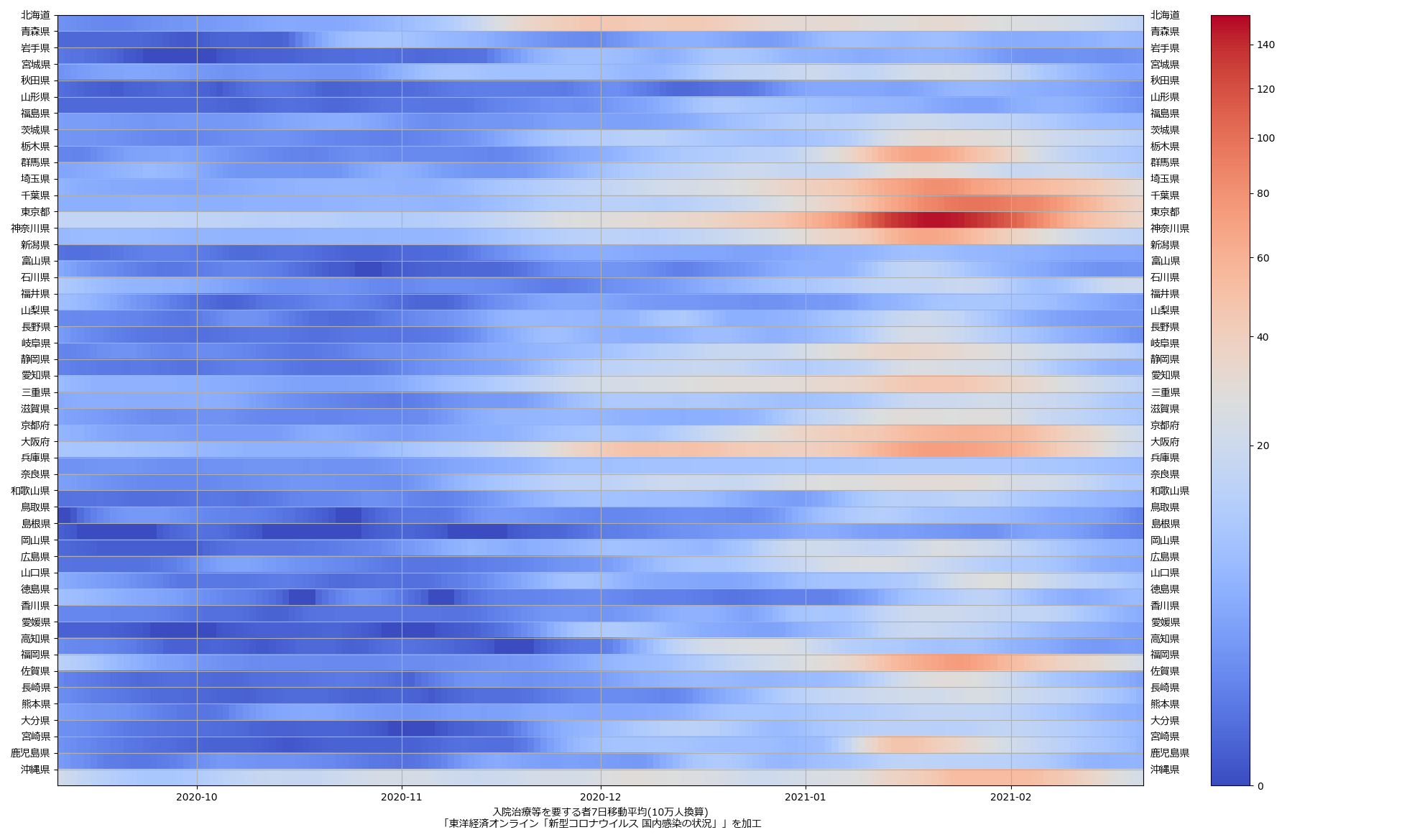
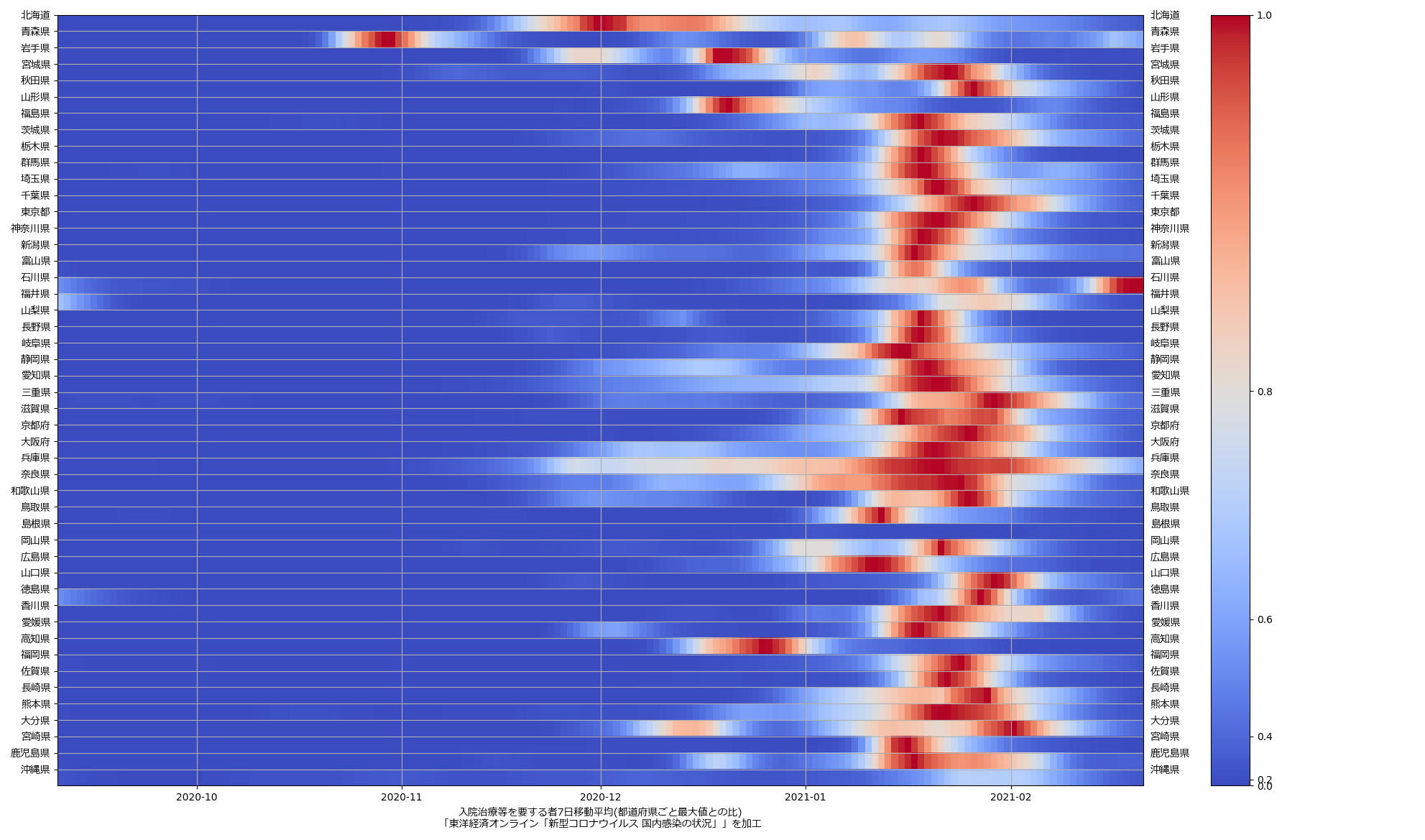
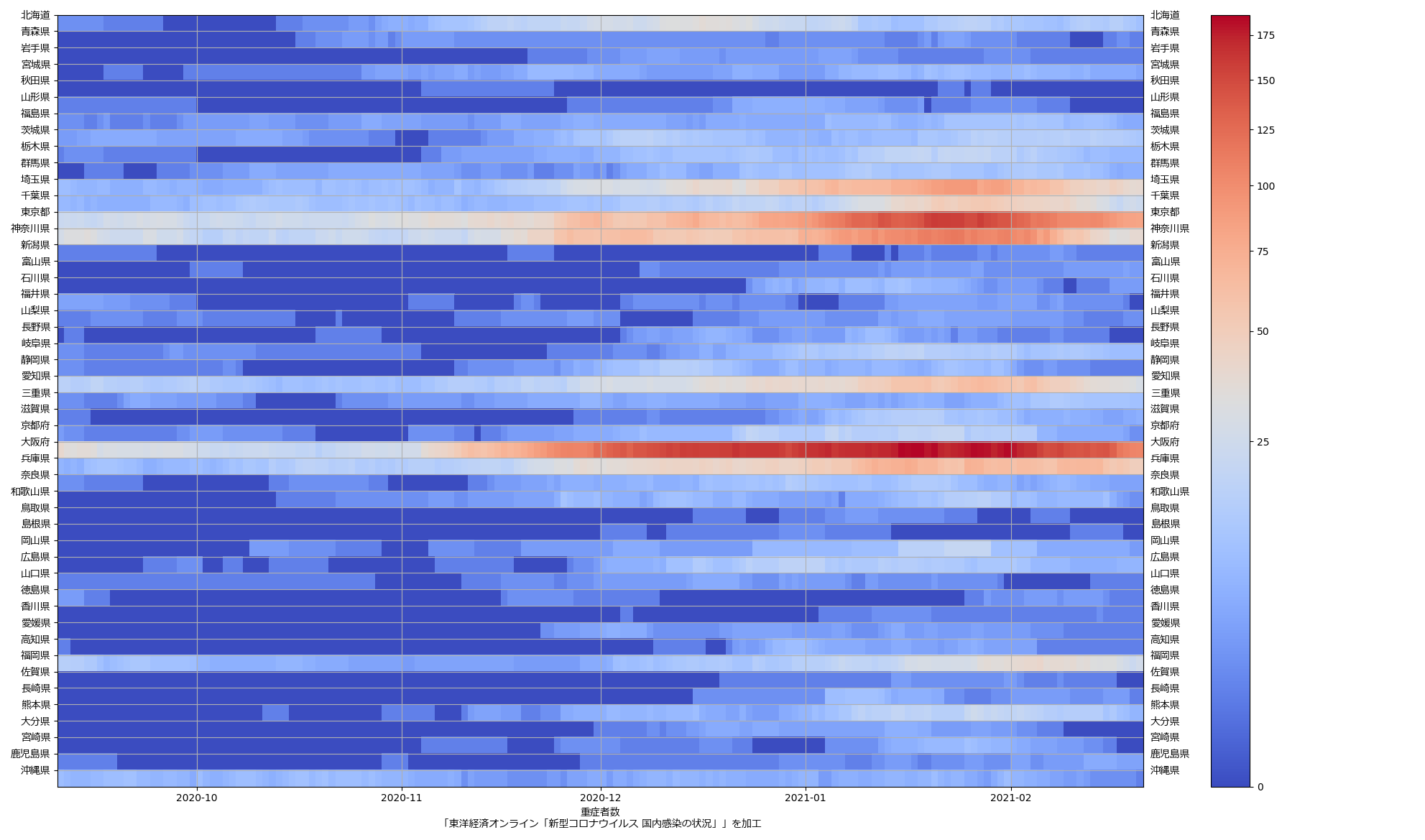
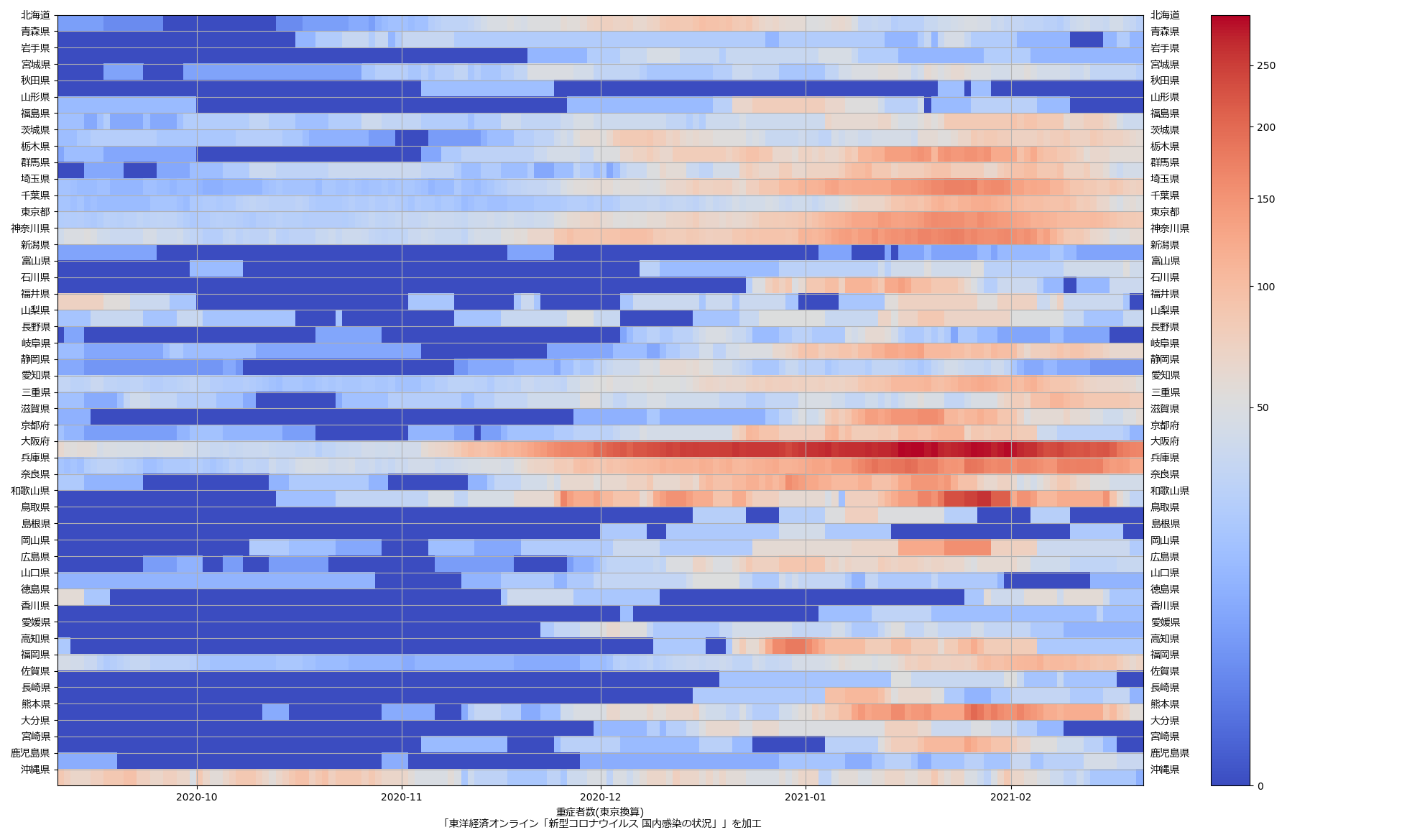
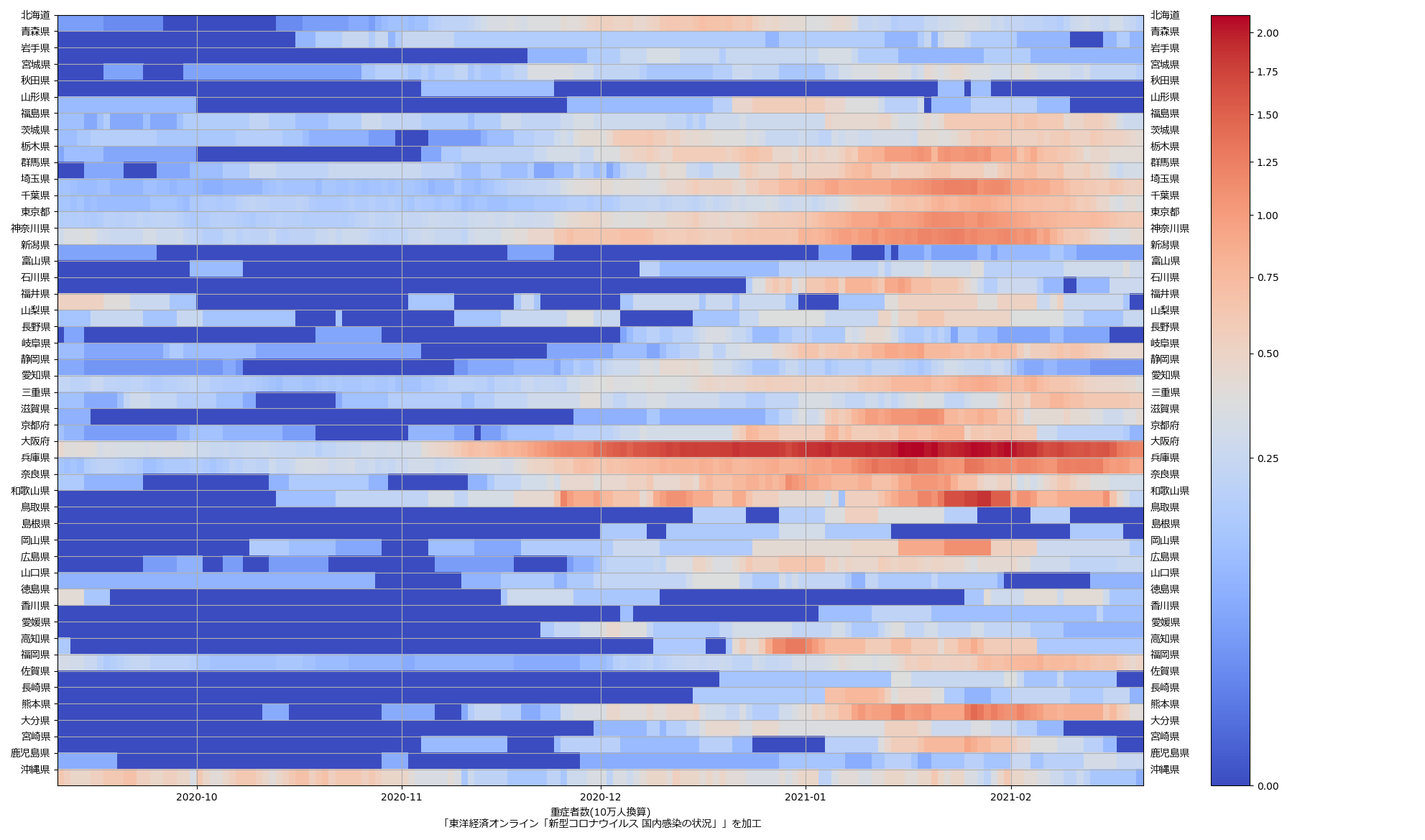
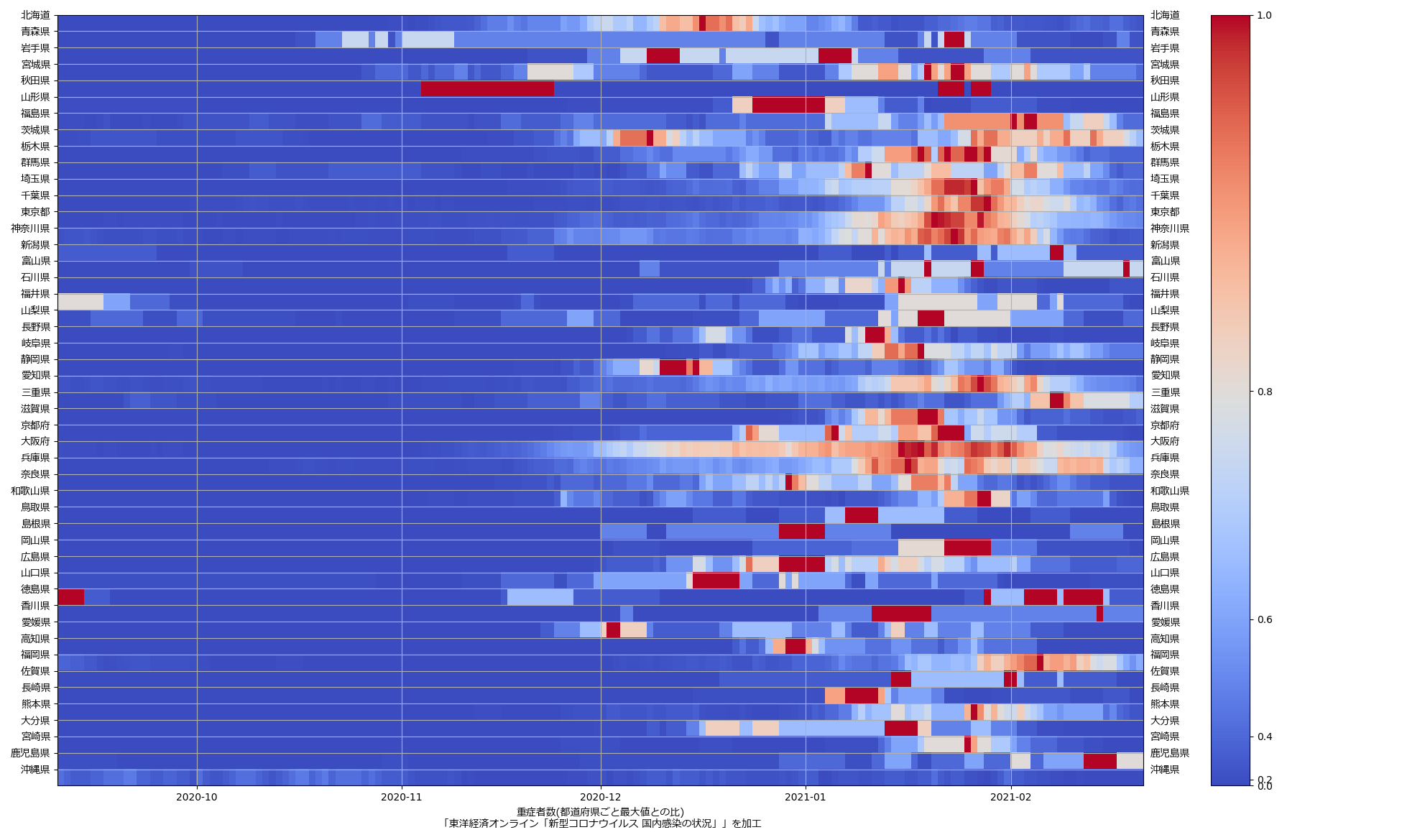
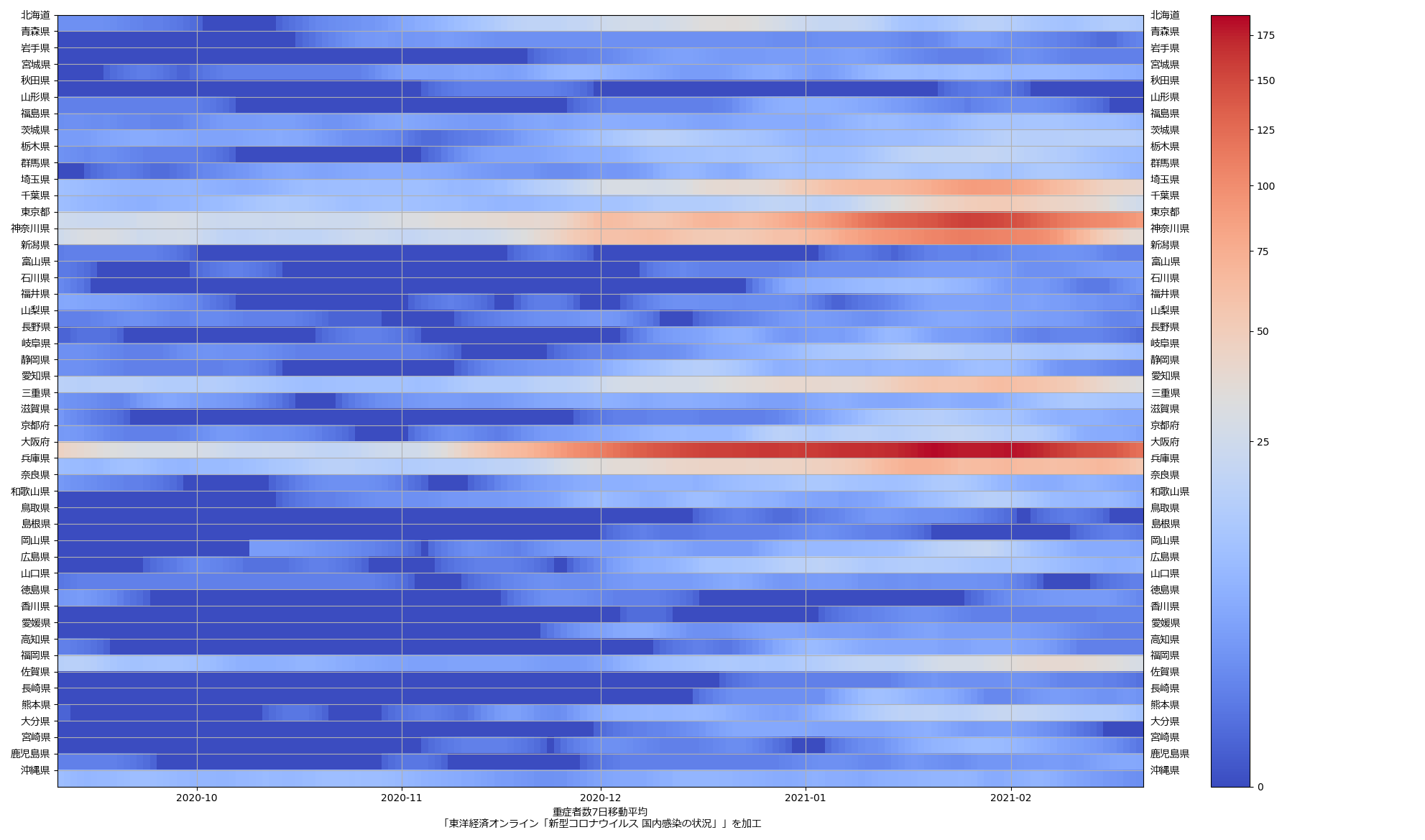
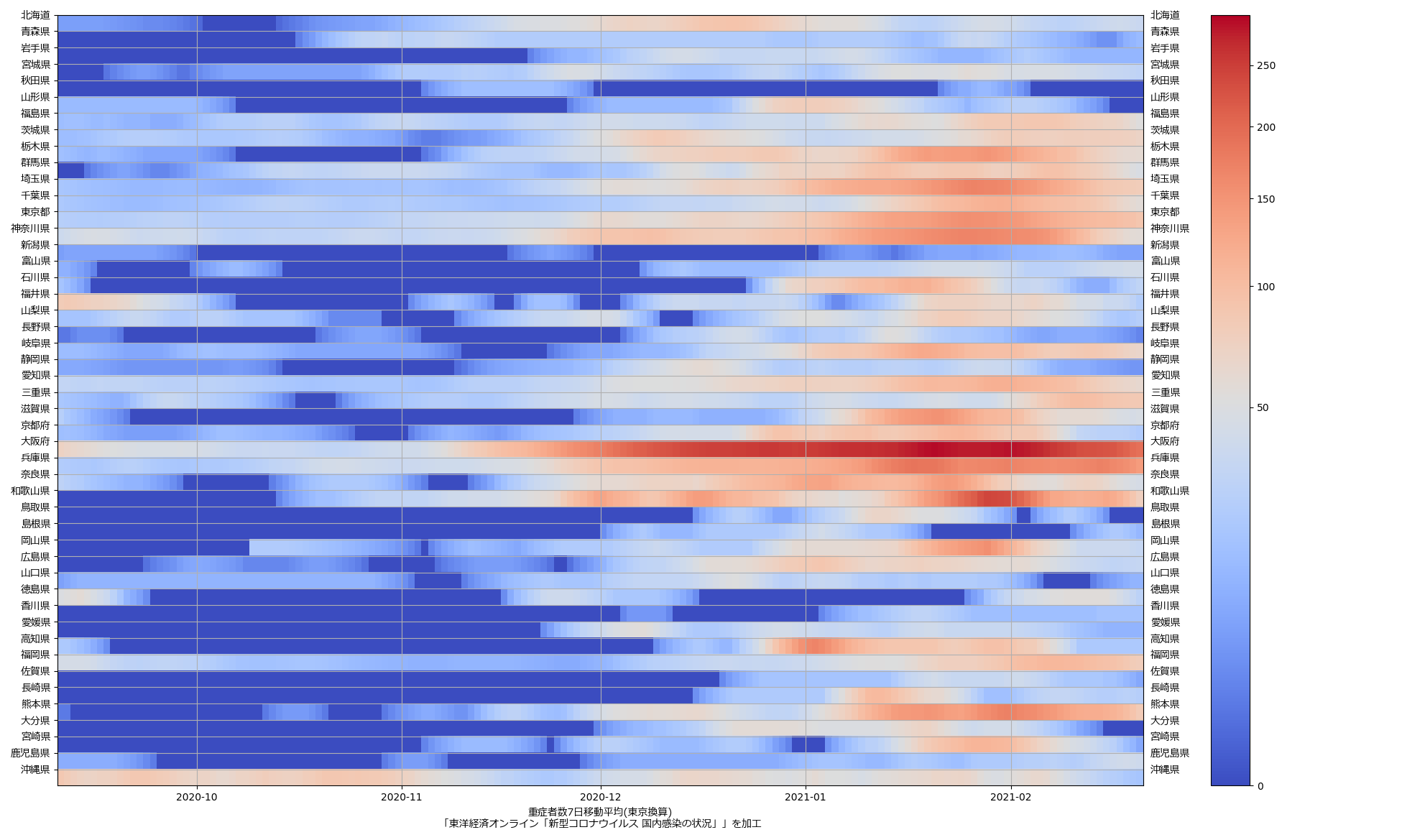
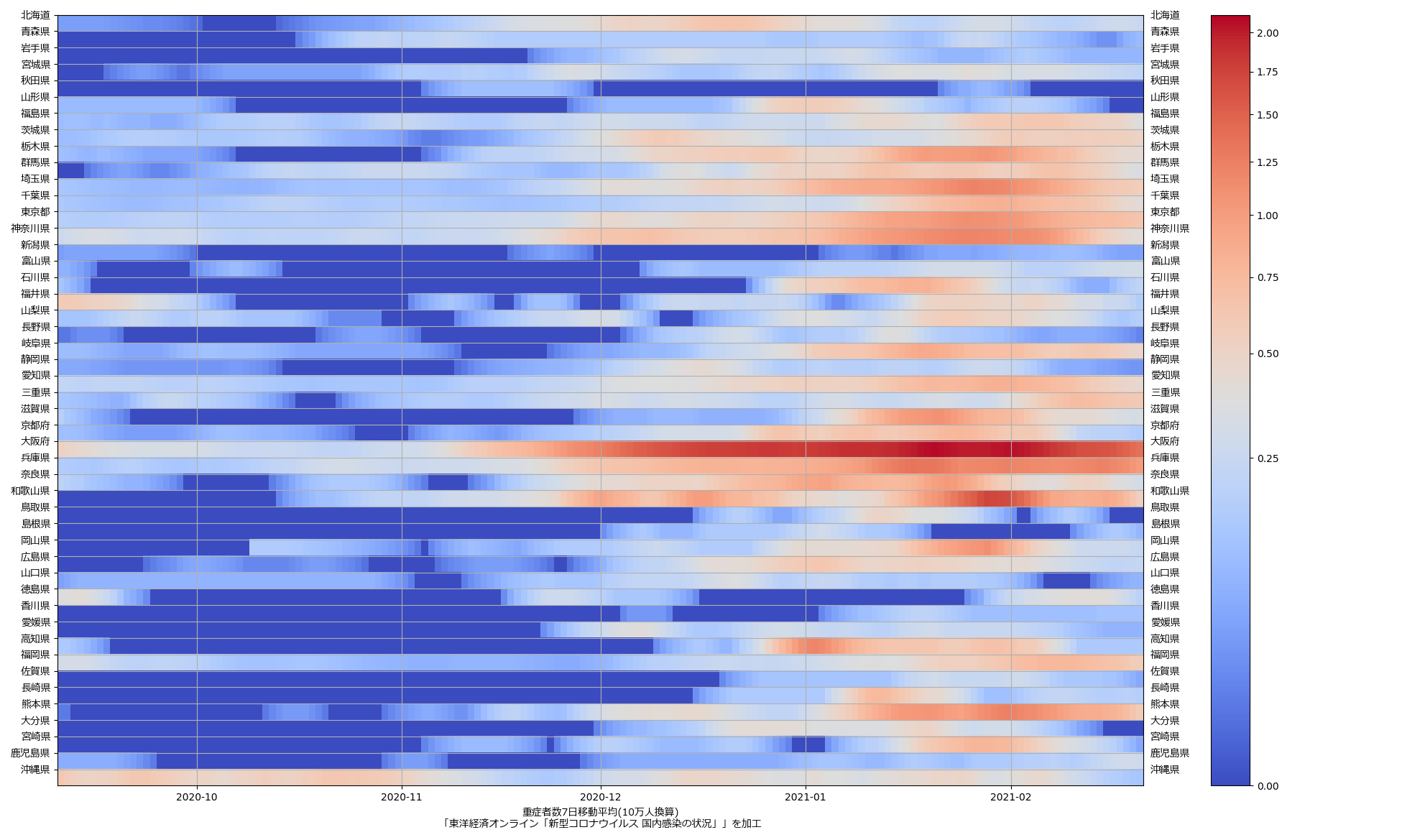
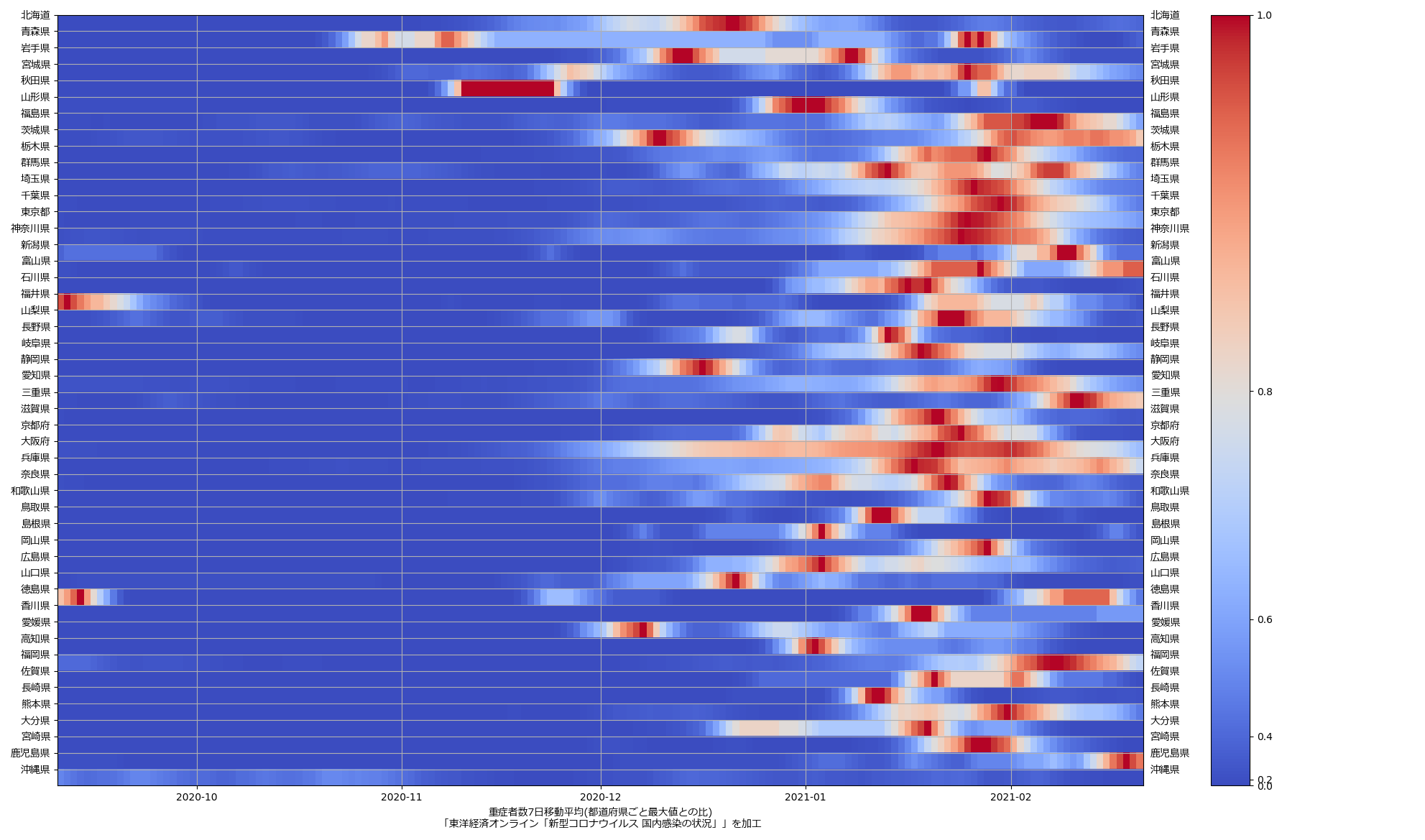
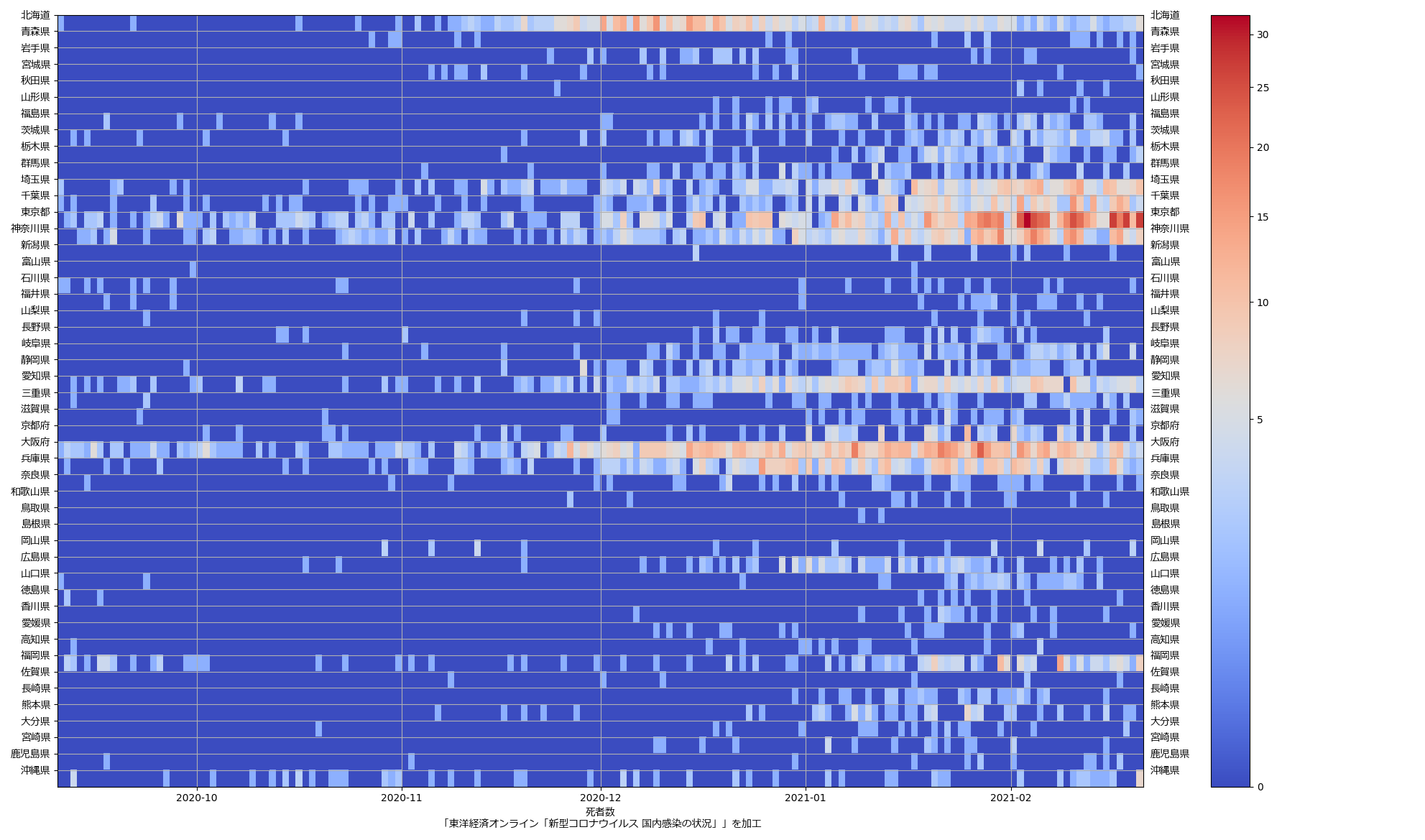
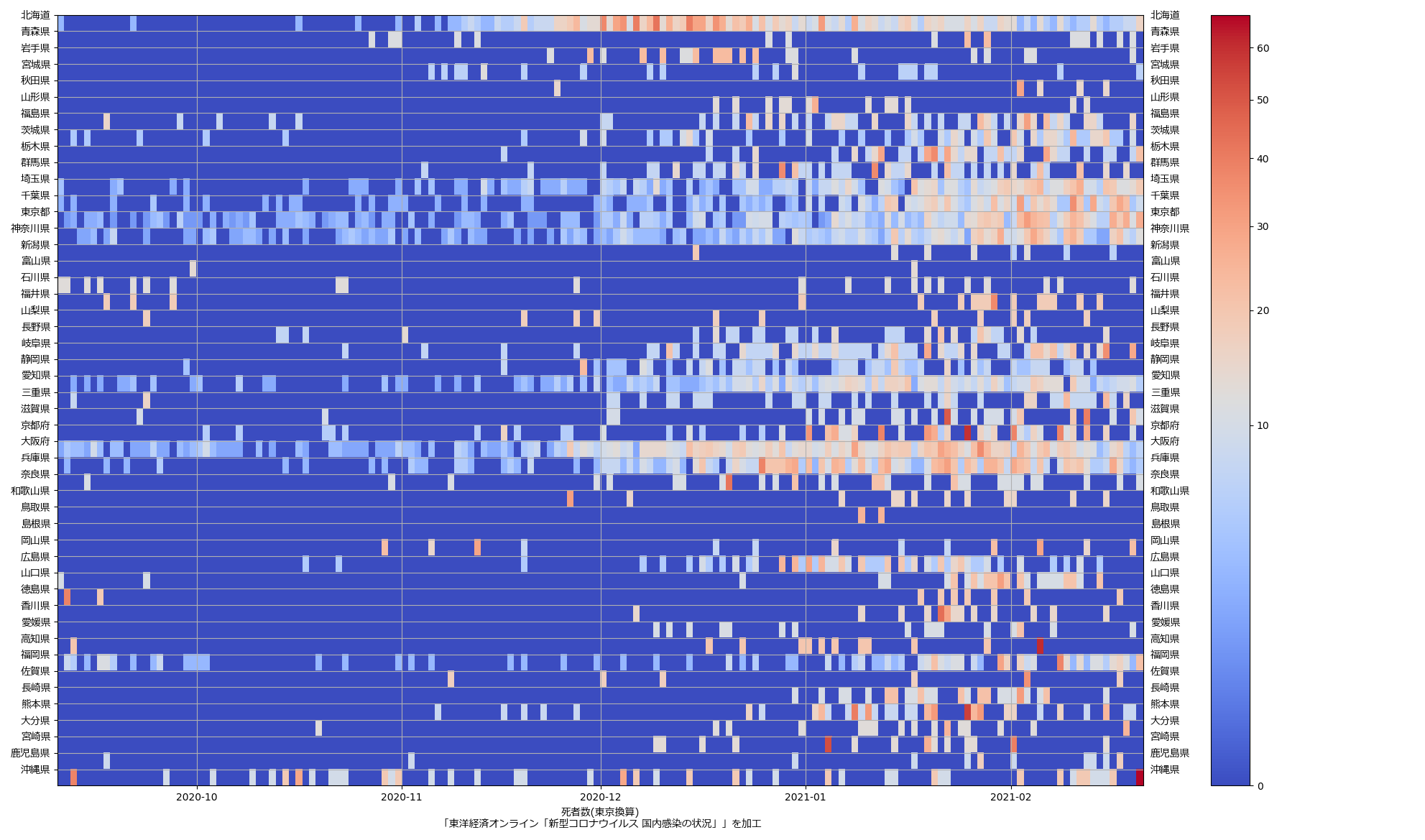
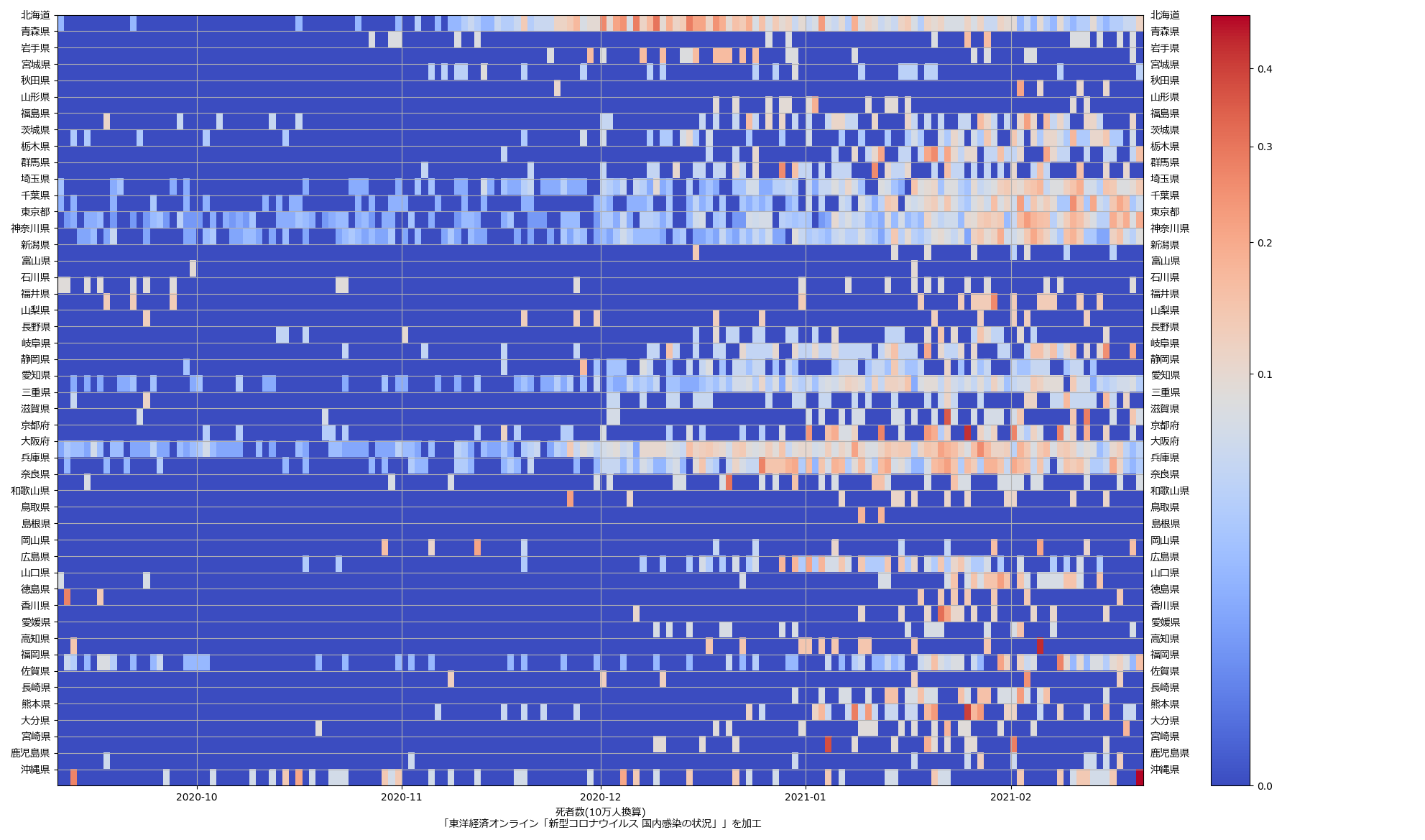
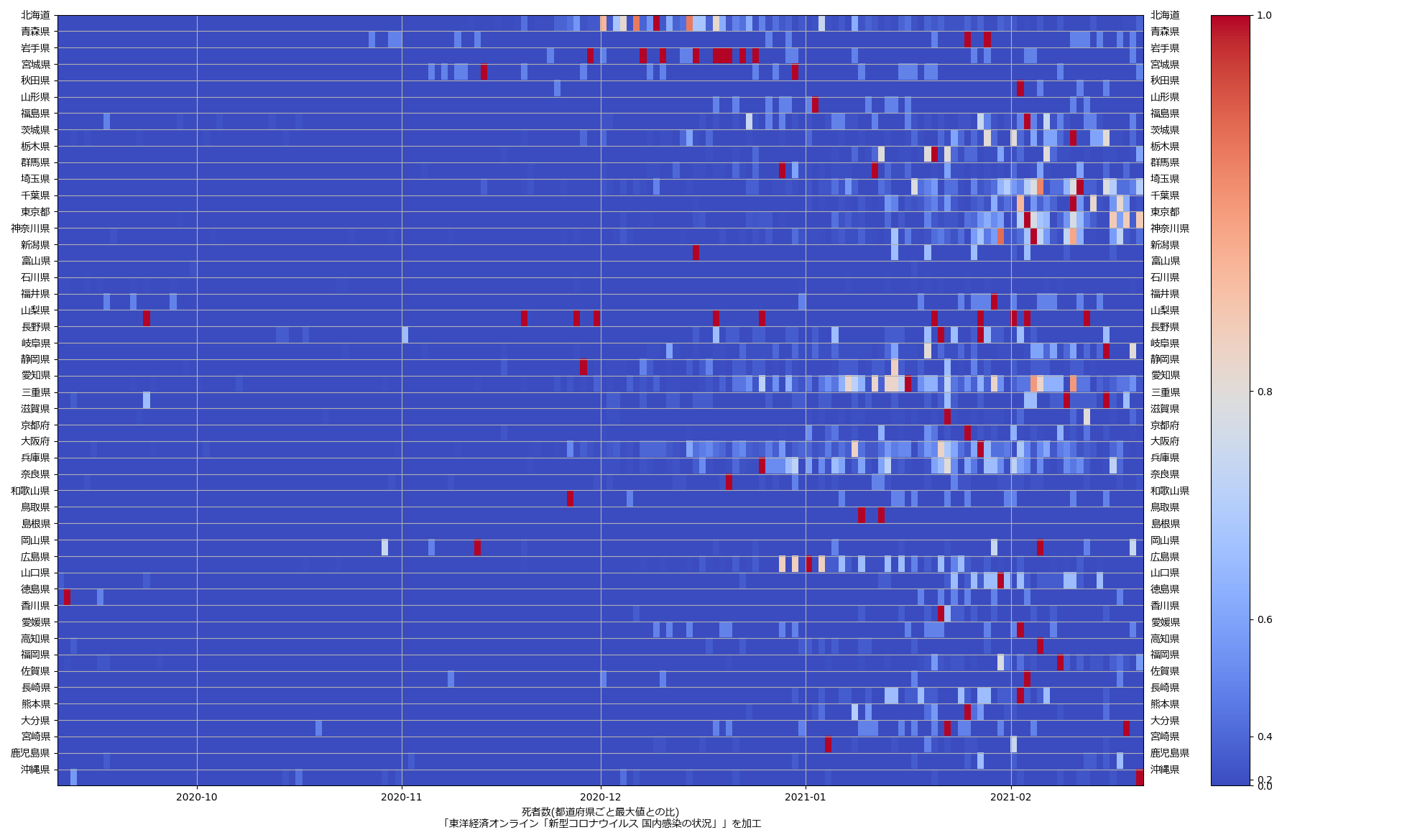
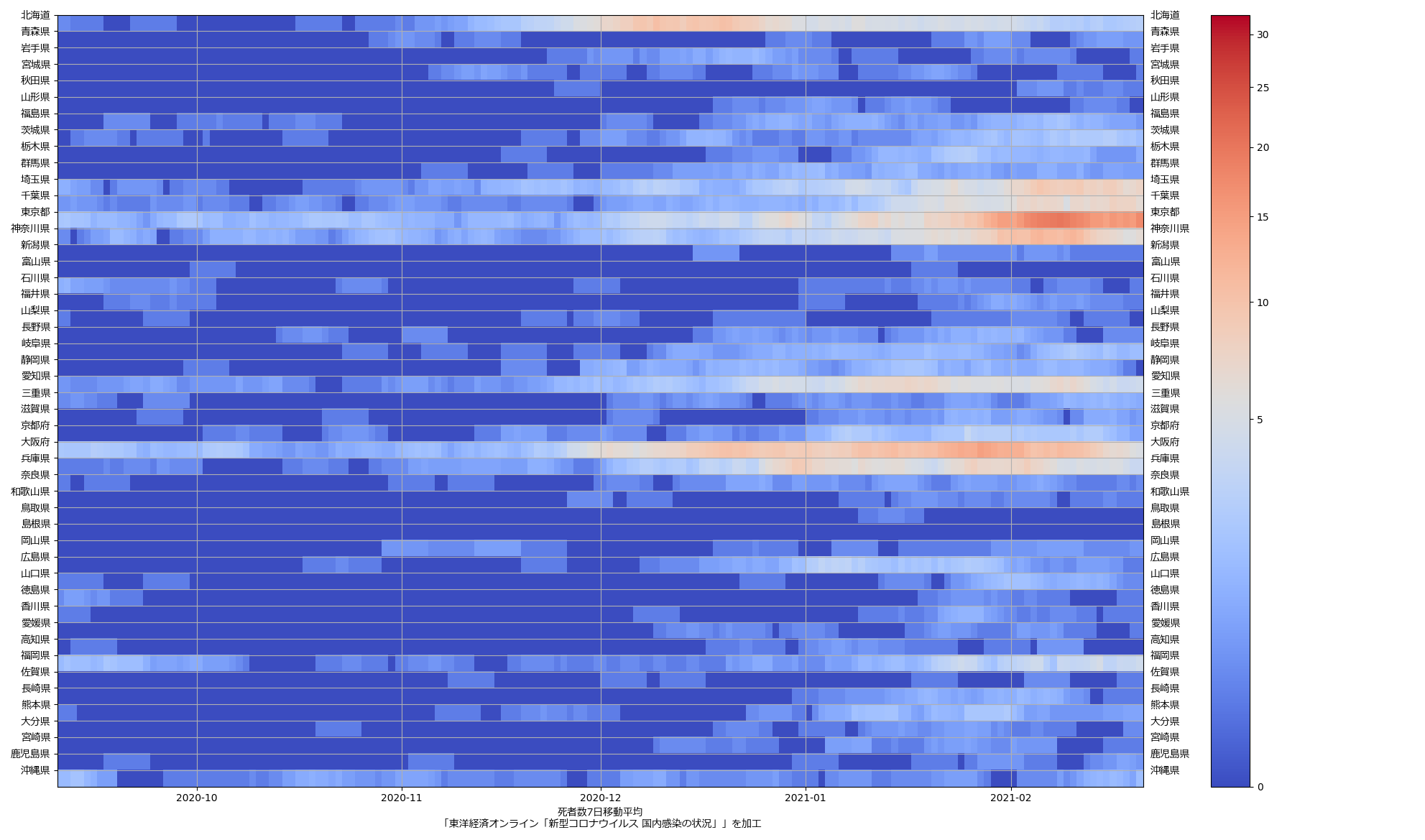

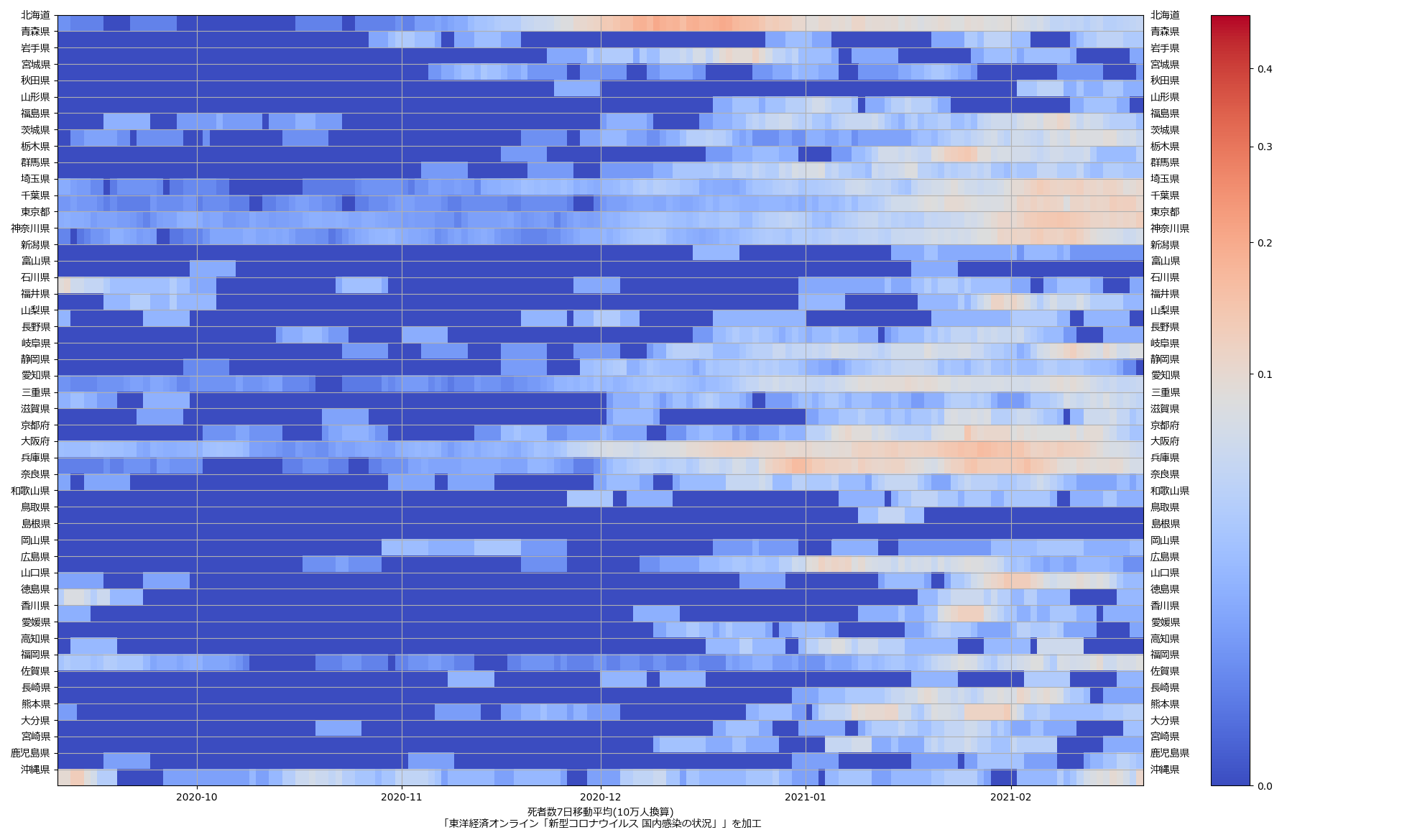
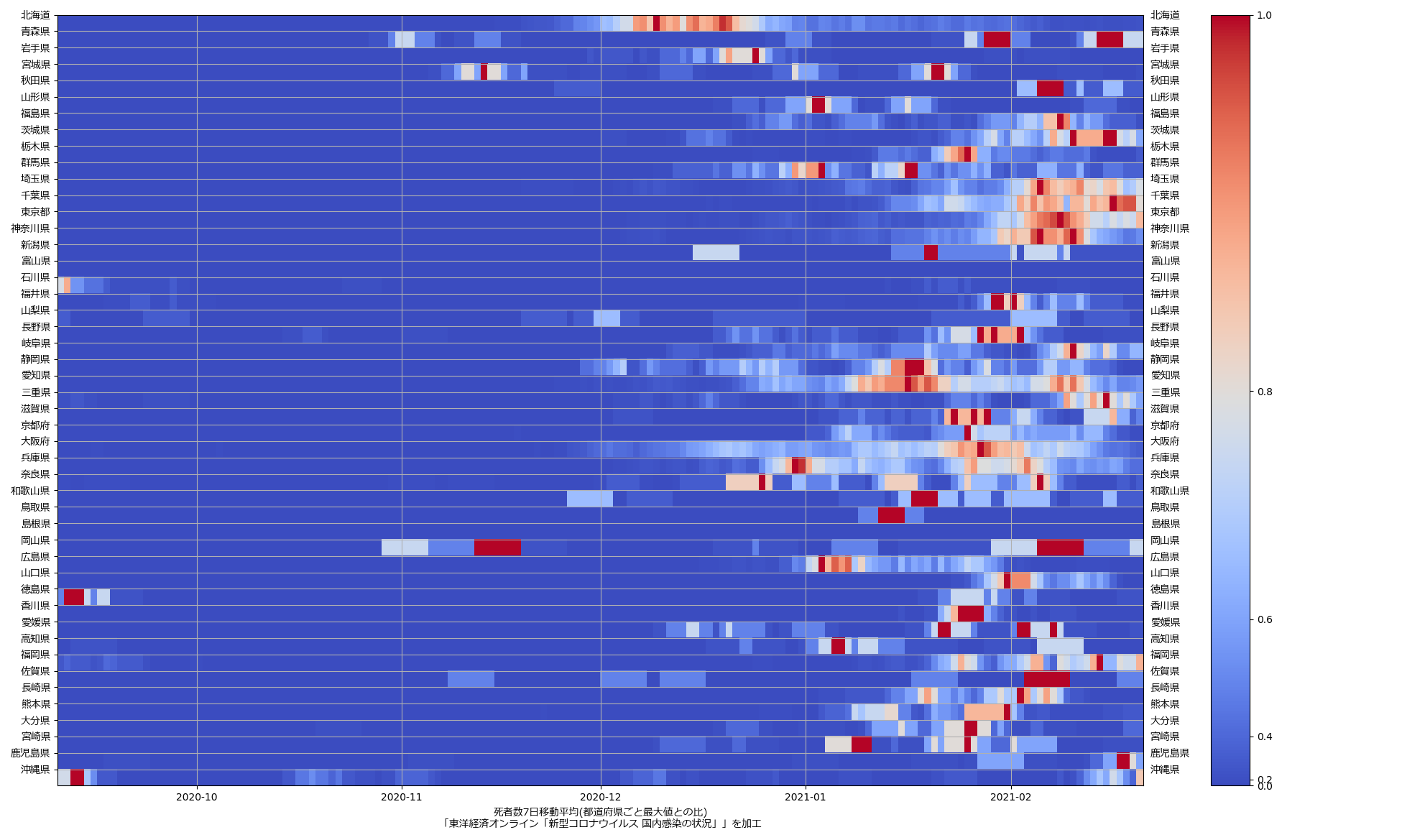
ここ何日か大阪問題について言ってきたが、改めて。注目して欲しいのは「重症者数(東京換算)」と「死亡者数(東京換算)」。後者にあまり差がないことにより、「大阪の重傷者数が多いのは東京と基準が異なるからである」というところの説得力が失われ、すなわち「本当に重症者が多い」ということがわかる、という点。ワタシがずっと主張してるのが、つまりそういうこと。「皆で同じ可視化を共有し、同じ問題意識を持つべきである」てこと。こういうちゃんとした分析的視点をこそ、メディアが率先して伝えるべきなのではないのか、てことね。
大阪問題、といってるけれど、正直2月5日頃に吉村知事が言い出した頃と今とではだいぶ状況が変わってる。そこで「300を切ったら」と言い出した時にはさすがに絶句した。というか、300という数字そのものより、2月7日の週にでも解除できる、という姿勢が見受けられたことに絶句したんだけどね。けど、今は一応重症者数も緩やかながら減少に転じ始めてるし、言ってることも「2月末」と随分慎重になった。「2月末」の妥当性についても、正直重症者数の数からいえばもろ手で賛成とは言わないけど、絶対論外だというほどでもない。
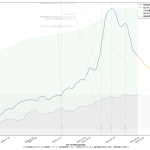
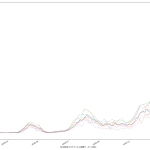
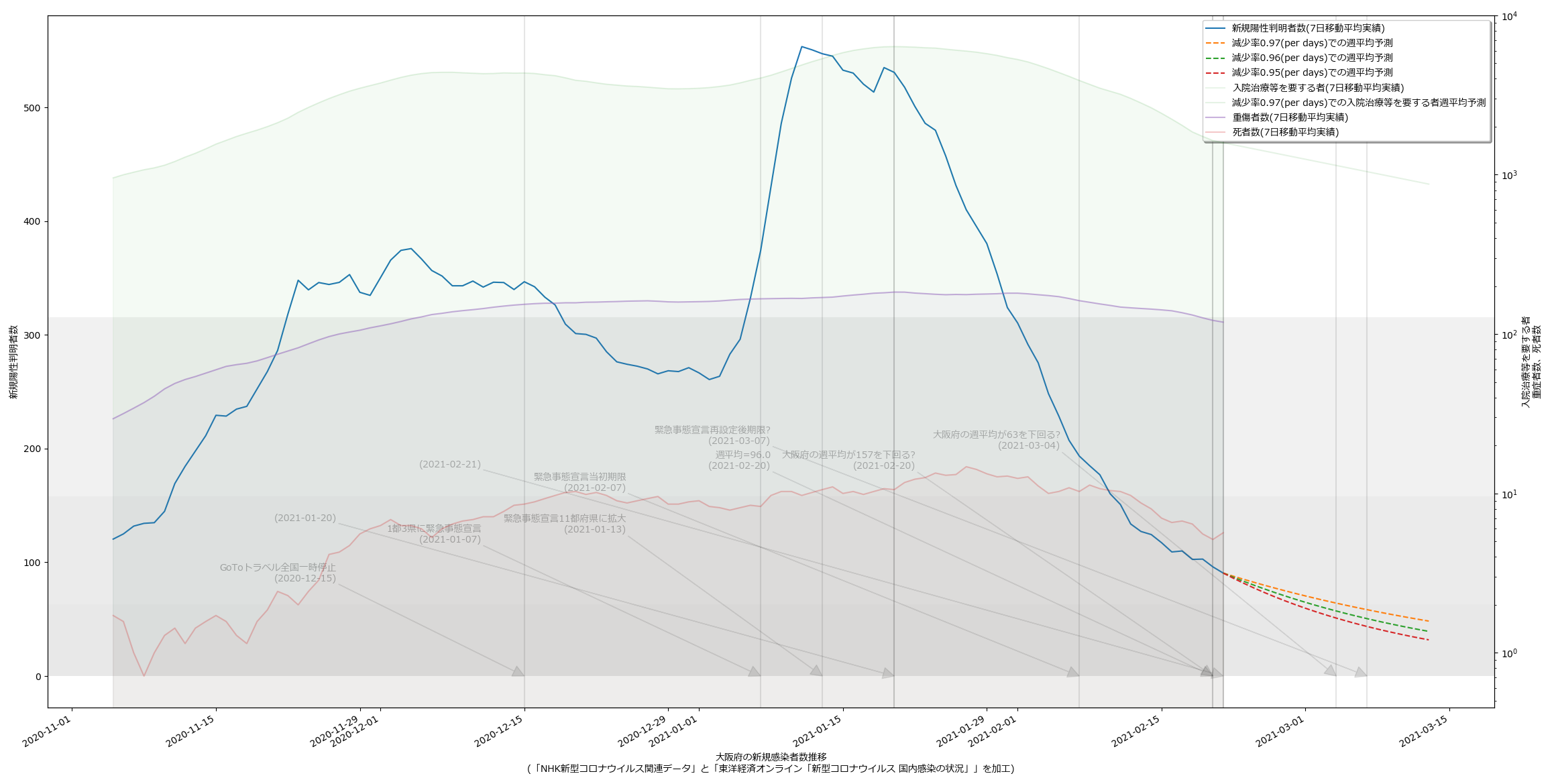
本日時点だと、大阪より東京の方が気になる傾向にあるやもしれん。死者数の推移がね、今ちょっと…:

報道でも伝えられる通り、新規感染者数の下げ止まりも気にはなるけれど、死者数が若干上昇傾向なのは、注視しておく必要がありそうだと思う。大阪はこんなね:
2021-03-05追記:
今回の追記も、「良い可視化を共有せよ」という主張を本題とするなら蛇足、その手法の方についての追記。スクリプトの改善は「前週比」の方だけで示す:
1 # -*- coding: utf-8-unix -*-
2 import io
3 import datetime
4 import numpy as np
5 import matplotlib.pyplot as plt
6 import matplotlib.font_manager
7 import matplotlib.ticker as ticker
8 from matplotlib.colors import BoundaryNorm, Normalize
9
10
11 _PREFCODE = {
12 '北海道': 1,
13 '青森県': 2,
14 '岩手県': 3,
15 '宮城県': 4,
16 '秋田県': 5,
17 '山形県': 6,
18 '福島県': 7,
19 '茨城県': 8,
20 '栃木県': 9,
21 '群馬県': 10,
22 '埼玉県': 11,
23 '千葉県': 12,
24 '東京都': 13,
25 '神奈川県': 14,
26 '新潟県': 15,
27 '富山県': 16,
28 '石川県': 17,
29 '福井県': 18,
30 '山梨県': 19,
31 '長野県': 20,
32 '岐阜県': 21,
33 '静岡県': 22,
34 '愛知県': 23,
35 '三重県': 24,
36 '滋賀県': 25,
37 '京都府': 26,
38 '大阪府': 27,
39 '兵庫県': 28,
40 '奈良県': 29,
41 '和歌山県': 30,
42 '鳥取県': 31,
43 '島根県': 32,
44 '岡山県': 33,
45 '広島県': 34,
46 '山口県': 35,
47 '徳島県': 36,
48 '香川県': 37,
49 '愛媛県': 38,
50 '高知県': 39,
51 '福岡県': 40,
52 '佐賀県': 41,
53 '長崎県': 42,
54 '熊本県': 43,
55 '大分県': 44,
56 '宮崎県': 45,
57 '鹿児島県': 46,
58 '沖縄県': 47,
59 }
60
61
62 class MidpointNormalize(Normalize):
63 def __init__(self, vmin=None, vmax=None, vcenter=None, clip=False):
64 self.vcenter = vcenter
65 Normalize.__init__(self, vmin, vmax, clip)
66
67 def __call__(self, value, clip=None):
68 # I'm ignoring masked values and all kinds of edge cases to make a
69 # simple example...
70 x, y = [self.vmin, self.vcenter, self.vmax], [0, 0.5, 1]
71 return np.ma.masked_array(np.interp(value, x, y))
72
73
74 def _vis(dattko):
75 #
76 era = datetime.date(2020, 1, 16)
77 #
78 fontprop = matplotlib.font_manager.FontProperties(
79 fname="c:/Windows/Fonts/meiryo.ttc")
80
81 era = "2020/1/16" # 木曜日
82 era = datetime.date(*map(int, era.split("/")))
83 #
84 k, subj = "testedPositive_movavg", "新規陽性判明者数週移動平均"
85 #
86 skip = 7*4*7
87 Z = dattko[k]
88 # 1.「100%」となるケースにおいて、純然たるゴミといえるパターン:
89 # 前週も今週も(限りなく)0
90 # このケースは「無意味」ということで nan としておく。としないと、まったく問題が
91 # ない「一人が一人になった!」として「前週比1倍未満ではない」ものとしてピックアップ
92 # することになり、馬鹿げている。
93 # 2.「前週比」の計算で、分母が1未満だと発散してウザいので、シンプルに1としておく。
94 Z[np.where(np.logical_and(Z < 1, np.roll(Z, 7, axis=0) < 1))] = np.nan
95 Z[np.where(Z < 1)] = 1
96 Z /= np.roll(Z, 7, axis=0)
97 Z *= 100
98 Z = Z[skip:]
99 Z[np.where(np.isnan(Z))] = 0
100 #
101 T = np.array([era + datetime.timedelta(t + skip) for t in range(len(Z))])
102 Y = np.arange(48)
103 X, Y = np.meshgrid(T, Y)
104 #
105 for i, norm in enumerate((
106 BoundaryNorm([0, 70, 90, 100, 200], 220),
107 MidpointNormalize(vcenter=90, vmax=200),
108 )):
109 fig, ax1 = plt.subplots(tight_layout=True)
110 fig.set_size_inches(16.53 * 1.2, 11.69)
111
112 ax1.invert_yaxis()
113 ax1.tick_params(labelright=True)
114 ax1.yaxis.set_major_formatter(
115 ticker.FuncFormatter(
116 lambda x, pos=None: {
117 pc: pn for (pn, pc) in _PREFCODE.items()}.get(x + 1, "")))
118 for lab in ax1.get_yticklabels():
119 lab.set_fontproperties(fontprop)
120 #
121 CS1 = ax1.pcolor(X, Y, Z.T, norm=norm, cmap="coolwarm")
122 ax1.set_yticks(range(47))
123 cbar1 = fig.colorbar(CS1)
124 # 最大値詐称していることをカラーバーで主張(「> 200」という具合に)しておく。としないと誤解を招く。
125 cbticklbls = [tlobj.get_text() for tlobj in cbar1.ax.get_yticklabels()]
126 cbticklbls[-1] = "> " + cbticklbls[-1]
127 cbar1.ax.set_yticklabels(cbticklbls)
128 #
129 ax1.set_xlabel(
130 "{}({})\n「東洋経済オンライン「新型コロナウイルス 国内感染の状況」」を加工".format(
131 subj, "前週比"),
132 fontproperties=fontprop)
133 ax1.grid(True)
134 fig.savefig("{}_{}_{}_{}.png".format(k, "cpw", str(T[-1]), i + 1))
135 #plt.show()
136 plt.close(fig)
137
138
139 if __name__ == '__main__':
140 _vis(np.load(io.open("toyokeizai_online_covid19.npz", "rb")))
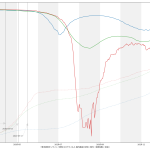
ポイントは二つで、一つはカラーバーのティックラベルの変更、もう一つは「Custom normalization」の実例。前者は些細だけどプレゼンテーションとしては結構重要で、後者は実は前からやりたくてやり方を知らなくて、初めてやってみたやつ。絵はこうなる:
「後者」の目的には、最新の matplotlib.colors には TwoSlopeNorm があるのでそれを使えばいいのだが、ワタシがインストールしてるバージョンにはまだ含まれてないので、まさに Custom normalization に書かれてるそのままを使った。何をしたかったのかはたぶん絵を見ればわかってもらえると思う…んだけど日本語で説明しづらいんだよな…。滑らかな階調で見たくて、なおかつ、その色の傾きが可変、てことなのよ。例えば標高の可視化を例にすると、「500m以上はほとんど茶色でいいが、500m以下の傾きが詳細にわかればいいなぁ」みたいなときに使うやつね。今ワタシがやってみせたヤツだと「前週比が90%以下まではあんまし重要でないのでほとんど真っ青でよろし」という制御をしてる、てこと。
2021-03-27追記:
「良い見える化を共有すべし、いまや小学生でも実現できるほどに容易なのだからなおさら」てのが、一連の話の主題の半分だった、てことはいい?
そうなんだけれど、実際問題 matplotlib はさすがに多少多めの鍛錬が必要で、さすがにそこいらの一般人が初見で怯んでしまう程度には難解なのは問題で、そういう意味で、ワタシの主張を弱めてしまう理由にもなっている。
「matplotlib だから」である、これは。matplotlib の名前の由来はおそらく「matrix plotting library」であろう。これからわかるように、最初に念頭に置かれたのは「行列の可視化」であり、すなわち「NumPy/SciPyとセットで」使われることが前提になっている。となると、これはもうユーザの層が自ずと偏ってきて、つまり「科学技術系」(特に自然科学系)に属する学者や技術者が好むものとなった。「難しいのが当たり前」の世界にいるもんだから、matplotlib に対しても「もっと簡単にすべきだ」なんて流れにはならん気がする。実際ワタシ自身も結構そっち寄り。
で、「ワタシには matplotlib があるのでおk (あるいは R とか gnuplot でもいい)」で思考停止状態だったとも言えるけれど、今回このようなシリーズを書いた手前、ちったぁ「もっと誰にでも」ネタがあればいいなぁ、とは思っていたの。そんなタイミングで、たまたま glances の(optional な)依存パッケージであるところの「pygal」に気付いた。おそらく WEB ベース前提のプロジェクトと思われる。
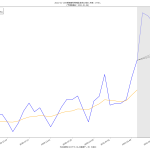
一つには結構古参でなおかつ、「WEBで」の方向性が SVG である点は、「いまどきの HTML5 時代」にはそぐわないのかもしれんけれど、いやまぁ、なにせ簡単だ、これは:
1 >>> import pygal
2 >>> from math import cos
3 >>> xy_chart = pygal.XY()
4 >>> xy_chart.title = 'XY Cosinus'
5 >>> xy_chart.add('x = cos(y)', [(cos(x / 10.), x / 10.) for x in range(-50, 50, 5)])
6 <pygal.graph.xy.XY object at 0x000001F221B730F0>
7 >>> xy_chart.add('y = cos(x)', [(x / 10., cos(x / 10.)) for x in range(-50, 50, 5)])
8 <pygal.graph.xy.XY object at 0x000001F221B730F0>
9 >>> xy_chart.add('x = 1', [(1, -5), (1, 5)])
10 <pygal.graph.xy.XY object at 0x000001F221B730F0>
11 >>> xy_chart.add('x = -1', [(-1, -5), (-1, 5)])
12 <pygal.graph.xy.XY object at 0x000001F221B730F0>
13 >>> xy_chart.add('y = 1', [(-5, 1), (5, 1)])
14 <pygal.graph.xy.XY object at 0x000001F221B730F0>
15 >>> xy_chart.add('y = -1', [(-5, -1), (5, -1)])
16 <pygal.graph.xy.XY object at 0x000001F221B730F0>
17 >>> xy_chart.render_to_png("pygal_example_xychart.png")
18 Traceback (most recent call last):
19 File "<stdin>", line 1, in <module>
20 File "C:\Program Files\Python35\lib\site-packages\pygal\graph\public.py", line 118, in render_to_png
21 import cairosvg
22 ImportError: No module named 'cairosvg'
23 >>> #xy_chart.render_to_file("pygal_example_xychart.svg")
24 >>> xy_chart.render_data_uri()
25 ...
cairo って Windows 版あったかなぁ? あれば png 化も出来ることになる。まぁ WEB 相手だけなら SVG だけでもありがたかろうね。結果はこんなね: