ちょっと毛色が違う話を。
結局のところ、日々ニュースをみながら「こういう図が見たいのになぁ」と思ってる、てことなのよ。
csvを自分の都合のいいデータに加工するスクリプト(週平均もついでに取ってる)
1 # -*- coding: utf-8 -*-
2 import io
3 import sys
4 import csv
5 import datetime
6 import numpy as np
7
8
9 def _tonpa(fn):
10 # rownum=2020/1/16からの日数, colnum=都道府県コード-1
11 result = {
12 "newpat": np.zeros((1, 47)),
13 "newpatmovavg": np.zeros((1, 47)),
14 "newdeath": np.zeros((1, 47)),
15 "newdeathmovavg": np.zeros((1, 47)),
16 }
17 era = "2020/1/16"
18 era = datetime.datetime(*map(int, era.split("/")))
19 reader = csv.reader(io.open(fn, encoding="utf-8-sig"))
20 next(reader)
21 for row in reader:
22 dt, (p, c, d) = row[0], map(int, row[1::2])
23 dt = (datetime.datetime(*map(int, dt.split("/"))) - era).days
24 if dt > len(result["newpat"]) - 1:
25 for k in result.keys():
26 result[k] = np.vstack((result[k], np.zeros((1, 47))))
27 result["newpat"][dt, p - 1] = c
28 result["newpatmovavg"][dt, p - 1] =
29 result["newpat"][max(0, dt - 7):dt + 1, p - 1].mean()
30 result["newdeath"][dt, p - 1] = d
31 result["newdeathmovavg"][dt, p - 1] =
32 result["newdeath"][max(0, dt - 7):dt + 1, p - 1].mean()
33 np.savez(io.open("nhk_news_covid19_prefectures_daily_data.npz", "wb"), **result)
34
35
36 if __name__ == '__main__':
37 fn = "nhk_news_covid19_prefectures_daily_data.csv"
38 _tonpa(fn)
2021-02-02追記:
スクリプトをマジメに読んだ人は気付いたかもしれない。「8日平均」を計算しちゃってる。一連の「主張」の本題とはあまり関係ないとはいえ、さすがにもうちょっと慎重にやるべきでした、すまぬ。正しくは「dt – 6」「dt – 5」…「dt – 1」「dt」の7エレメントでの平均を取らなければならないので、「slice(dt – 6, dt + 1)」。8日平均が役に立たないわけではないけれど、やりたいこととやってることが違うので、間違いは間違い。グラフは滑らかさが若干減って、もうほんの少しだけガタガタになる。
スクリプトをマジメに読んだ人は気付いたかもしれない。「8日平均」を計算しちゃってる。一連の「主張」の本題とはあまり関係ないとはいえ、さすがにもうちょっと慎重にやるべきでした、すまぬ。正しくは「dt – 6」「dt – 5」…「dt – 1」「dt」の7エレメントでの平均を取らなければならないので、「slice(dt – 6, dt + 1)」。8日平均が役に立たないわけではないけれど、やりたいこととやってることが違うので、間違いは間違い。グラフは滑らかさが若干減って、もうほんの少しだけガタガタになる。
上のスクリプトでセーブしたデータを読み込んで可視化を行うやーつ
1 # -*- coding: utf-8 -*-
2 import io
3 import datetime
4 import numpy as np
5 import matplotlib as mpl
6 import matplotlib.pyplot as plt
7 import matplotlib.font_manager
8
9
10 def _vis(dat):
11 era = "2020/1/16" # 木曜日
12 era = datetime.datetime(*map(int, era.split("/")))
13 npat = dat["newpat"][:,12] # 12: 東京 (都道府県コード13)
14 npatma = dat["newpatmovavg"][:,12]
15
16 fontprop = matplotlib.font_manager.FontProperties(fname="c:/Windows/Fonts/meiryo.ttc")
17
18 T = [era + datetime.timedelta(t) for t in range(len(npat))]
19 fig, ax1 = plt.subplots(tight_layout=True)
20 fig.set_size_inches(16.53, 11.69)
21 lines = []
22 for dow in range(7):
23 l, = ax1.plot(T[dow::7], npat[dow::7], linestyle="dotted")
24 lines.append(l)
25 l, = ax1.plot(T, npatma)
26 lines.append(l)
27 ax1.legend(lines, [
28 dow + "曜日" for dow in [
29 "木", "金", "土", "日", "月", "火", "水"]] + ["週平均"],
30 shadow=True, prop=fontprop)
31 ax1.set_xlabel("「NHK新型コロナウイルス関連データ」を加工", fontproperties=fontprop)
32 fig.autofmt_xdate()
33 #plt.show()
34 fig.savefig("nhk_news_covid19_prefectures_daily_data.png")
35 plt.close(fig)
36
37
38 if __name__ == '__main__':
39 fn = "nhk_news_covid19_prefectures_daily_data.npz"
40 _vis(np.load(io.open(fn, "rb")))
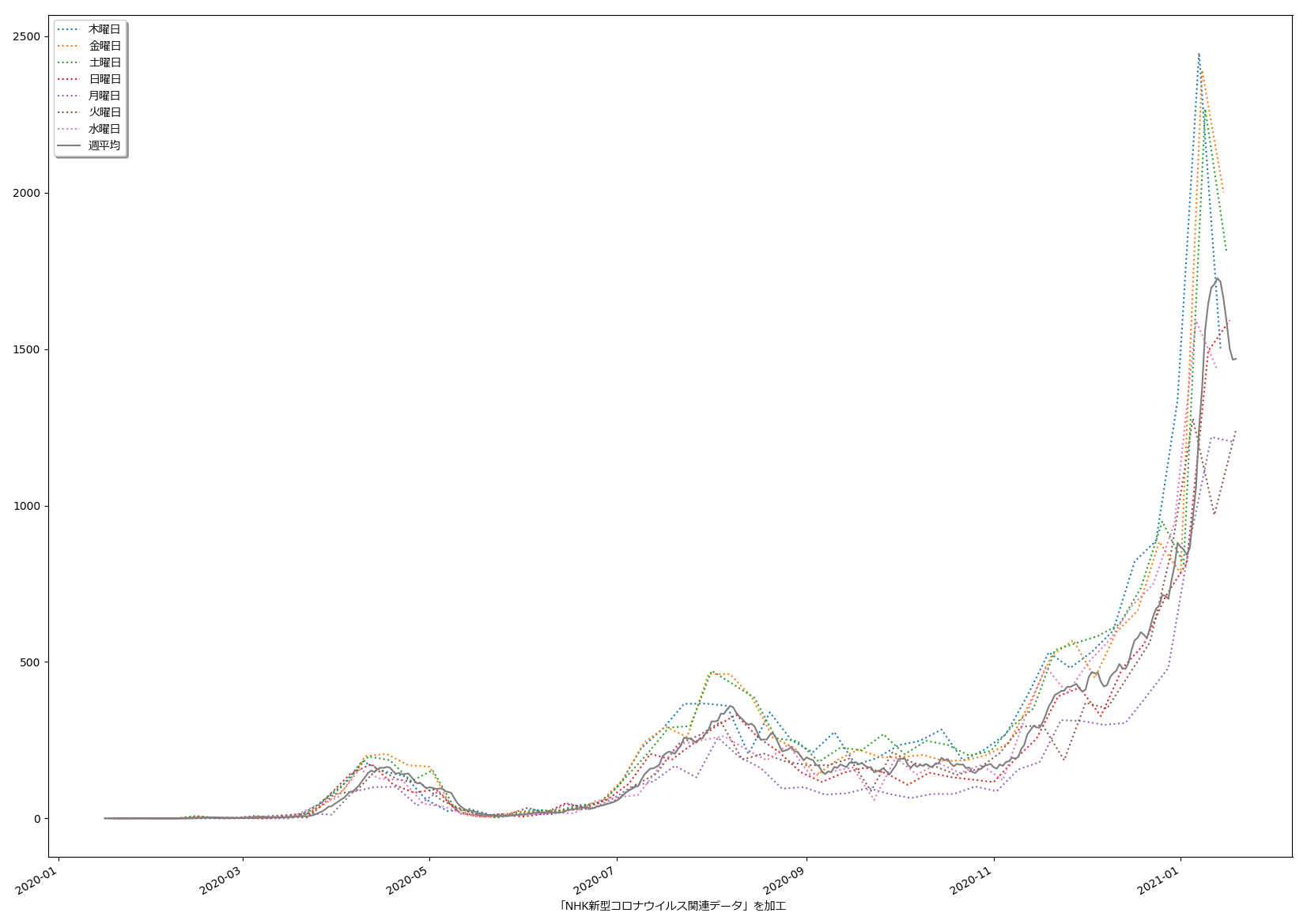
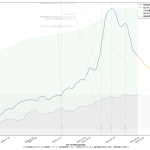
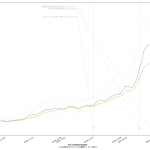
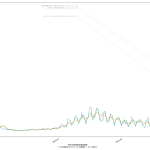
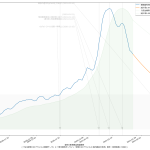
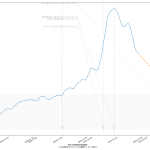
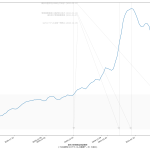
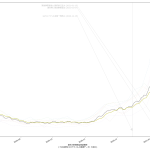
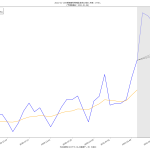
10分くらいででっちあげたので、曜日がズレてたりしたらゴメン。これ、何が言いたいかというと、「曜日ごとに検査数が違う」という特徴がわかってるんだからさ、「曜日ごとの推移をグラフにしたらええやん」と誰しもが思っていたなんてことはないのかな、てことよ。水曜が500件でした、木曜になんと1500件になりました、きゃーびっくりびっくり、なんて反応をする報道は今では皆無で、「木曜~土曜は検査数が増えるので、陽性判明者も増える」ことは、少なくとも「メディアは」知っているわけである。そしてこれが「国民が」とは限らないことが、まぁ問題といえば問題なわけだ。前回までの話と同じで、「同じものをみる」ことって結構大事で、「テレビ局が知っている」だけでなく、つまり「週平均をみることなく日々の数字に一喜一憂すべからず」と言うだけでなく「曜日ごとの推移としてプレゼンす」ればいいんじゃないの、と。
(3)までの話は、バカであろうと機械に予測を行わせる話だった。今回のはそうではなく単に「見せ方」の話ではあるんだけれど、ただ、「水曜が500件でした、木曜になんと1500件になりました、きゃーびっくりびっくり」グラフは、要は「グラフの動きが追いにくい」ということに繋がり、なので、感覚的に推移をとらえることも難しくなっているわけだが、今ワタシがやってみせた見せ方なら、一般人でも一週間後の予測を立てやすいんじゃないのかな、と。