信用はしないでね。
(7)までにやってみていた素人予測はいったん忘れて、「ワイドショーがやってた素人予測」を真似てみようかと。「このまま~%減少を続ければ云々」てやつね。これもどっちがいいとかはなくて、どっちも素人考え。どれも当たらずとも遠からず、という意味で、「まぁまぁ」と言える、てことになる。というか(7)までで言いたかったのは、「政治家の目にもちゃんととまるように、毎日未来予測を見せやがれ」という目的の方であって、予測内容の方はあんまし本題ではなかったわけで。
1 # -*- coding: utf-8 -*-
2 import io
3 import sys
4 import csv
5 import datetime
6 import numpy as np
7
8
9 def _tonpa(fn):
10 # rownum=2020/1/16からの日数, colnum=都道府県コード-1
11 result = {
12 "newpat": np.zeros((1, 47)),
13 "newpatmovavg": np.zeros((1, 47)), # 週平均
14 "newpatmovavg2": np.zeros((1, 47)), # 2週平均
15 "newdeath": np.zeros((1, 47)),
16 "newdeathmovavg": np.zeros((1, 47)),
17 "newdeathmovavg2": np.zeros((1, 47)),
18 "effrepro": np.zeros((1, 48)), # 実効再生産数(47都道府県+全国)
19 }
20 era = "2020/1/16"
21 era = datetime.datetime(*map(int, era.split("/")))
22 reader = csv.reader(io.open(fn, encoding="utf-8-sig"))
23 next(reader)
24 for row in reader:
25 dt, (p, c, d) = row[0], map(int, row[1::2])
26 dt = (datetime.datetime(*map(int, dt.split("/"))) - era).days
27 if dt > len(result["newpat"]) - 1:
28 for k in result.keys():
29 cn = 48 if k == "effrepro" else 47
30 result[k] = np.vstack((result[k], np.zeros((1, cn))))
31 result["newpat"][dt, p - 1] = c
32 result["newpatmovavg"][dt, p - 1] = result[
33 "newpat"][max(0, dt - 7):dt + 1, p - 1].mean()
34 result["newpatmovavg2"][dt, p - 1] = result[
35 "newpat"][max(0, dt - 14):dt + 1, p - 1].mean()
36 result["newdeath"][dt, p - 1] = d
37 result["newdeathmovavg"][dt, p - 1] = result[
38 "newdeath"][max(0, dt - 7):dt + 1, p - 1].mean()
39 result["newdeathmovavg2"][dt, p - 1] = result[
40 "newdeath"][max(0, dt - 14):dt + 1, p - 1].mean()
41 # 実効再生産数は、現京都大学西浦教授提案による簡易計算(を一般向け説明にまとめてくれ
42 # ている東洋経済ONLINE)より:
43 # (直近7日間の新規陽性者数/その前7日間の新規陽性者数)^(平均世代時間/報告間隔)
44 # 平均世代時間は=5日、報告間隔=7日の仮定。
45 # のつもりだが、東洋経済ONLINEで GitHub にて公開(閉鎖予定)されてる計算結果の csv とは
46 # 値が違う。違うことそのものは致し方ないこと。計算タイミングによって結果は変わるし、
47 # NHK まとめと東洋経済ONLINEのデータはシンクロしてないから。思いっきり間違ってるって
48 # ことはなさそう。近い値にはなってる。
49 for dt in range(len(result["newpat"])):
50 # 都道府県別
51 sum1 = result["newpat"][dt-6:dt+1, :47].sum(axis=0)
52 sum2 = result["newpat"][dt-6-7:dt+1-7, :47].sum(axis=0)
53 result["effrepro"][dt, :47] = np.power(sum1 / sum2, 5. / 7.)
54
55 # 全国
56 sum1 = result["newpat"][dt-6:dt+1, :].sum()
57 sum2 = result["newpat"][dt-6-7:dt+1-7, :].sum()
58 result["effrepro"][dt, 47] = np.power(sum1 / sum2, 5. / 7.)
59 np.savez(io.open("nhk_news_covid19_prefectures_daily_data.npz", "wb"), **result)
60
61
62 if __name__ == '__main__':
63 fn = "nhk_news_covid19_prefectures_daily_data.csv"
64 _tonpa(fn)
スクリプトをマジメに読んだ人は気付いたかもしれない。「8日平均」と「15日平均」を計算しちゃってる。一連の「主張」の本題とはあまり関係ないとはいえ、さすがにもうちょっと慎重にやるべきでした、すまぬ。正しくは「dt – 6」「dt – 5」…「dt – 1」「dt」の7エレメントでの平均を取らなければならないので、「slice(dt – 6, dt + 1)」。8日平均が役に立たないわけではないけれど、やりたいこととやってることが違うので、間違いは間違い。グラフは滑らかさが若干減って、もうほんの少しだけガタガタになる。
1 # -*- coding: utf-8 -*-
2 import io
3 import datetime
4 import numpy as np
5 import matplotlib as mpl
6 import matplotlib.pyplot as plt
7 import matplotlib.font_manager
8
9
10 def _vis(dat):
11 fontprop = matplotlib.font_manager.FontProperties(
12 fname="c:/Windows/Fonts/meiryo.ttc")
13
14 era = "2020/1/16" # 木曜日
15 era = datetime.datetime(*map(int, era.split("/")))
16 (wh_sl, wh_n) = (slice(12, 12+1), "東京")
17
18 npat = dat["newpat"][:,wh_sl].sum(axis=1)
19 npatma = dat["newpatmovavg"][:,wh_sl].sum(axis=1)
20
21 T = [era + datetime.timedelta(t) for t in range(len(npat))]
22 fig, ax1 = plt.subplots(tight_layout=True)
23 fig.set_size_inches(16.53 * 1.2, 11.69)
24 skip = 7*4*10
25 #
26 # ワイドショーが最近やってる「単純計算でこのまま~%減少ペースならば云々」そのもの
27 # を。簡単のために、減少率は直近の最大(1月13日)と本日の比較としてみる。
28 # (→10:30追記参照)
29 [t0], = np.where(npatma[skip:] == npatma[skip:].max()) # 1月13日
30 t1 = len(npatma[skip:]) - 1
31 lap = 1 - ((npatma[skip:][t1] / npatma[skip:][t0]) / (t1 - t0)) # per days
32 preds = []
33 val = npatma[skip:][t1]
34 while True:
35 preds.append(val)
36 if val < 500.: # 東京の感染者数週平均が500を下回る?
37 break
38 val *= lap
39 #
40 lines = []
41 l, = ax1.plot(T[skip:], npatma[skip:])
42 lines.append(l)
43 l, = ax1.plot(
44 [era + datetime.timedelta(skip + t)
45 for t in range(t1, t1 + len(preds))], preds)
46 lines.append(l)
47 ax1.legend(
48 lines,
49 ["7日移動平均実績", "減少率{:.2f}(per days)での週平均予測".format(lap)],
50 shadow=True, prop=fontprop)
51 ax1.set_xlabel(
52 "{}の新規感染者数推移\n(「NHK新型コロナウイルス関連データ」を加工)".format(
53 wh_n),
54 fontproperties=fontprop)
55 plt.axhspan(0, 500, facecolor="lightgray", alpha=0.1)
56 fig.autofmt_xdate()
57 #
58 tlast = era + datetime.timedelta(skip + t1 + len(preds) - 1)
59 for evtxt, evdt in (
60 ("GoToトラベル全国一時停止", datetime.datetime(2020, 12, 15)),
61 ("1都3県に緊急事態宣言", datetime.datetime(2021, 1, 7)),
62 ("緊急事態宣言11都府県に拡大", datetime.datetime(2021, 1, 13)),
63 ("東京の週平均が500を下回る?",
64 tlast),
65 ):
66 ax1.annotate("{} ({})".format(evtxt, str(evdt)[:len("????-??-??")]),
67 xy=(evdt, 0), xycoords='data',
68 xytext=(
69 0.5,
70 (evdt - era).days / (tlast - era).days),
71 textcoords='axes fraction',
72 arrowprops=dict(facecolor='black', width=0.0001, alpha=0.1),
73 horizontalalignment='right', verticalalignment='top',
74 alpha=0.3,
75 fontproperties=fontprop)
76 ax1.vlines([evdt], 0, 1, transform=ax1.get_xaxis_transform(), alpha=0.1)
77 #
78 #plt.show()
79 fig.savefig(
80 "nhk_news_covid19_prefectures_daily_data4.png")
81 plt.close(fig)
82
83
84 if __name__ == '__main__':
85 fn = "nhk_news_covid19_prefectures_daily_data.npz"
86 _vis(np.load(io.open(fn, "rb")))
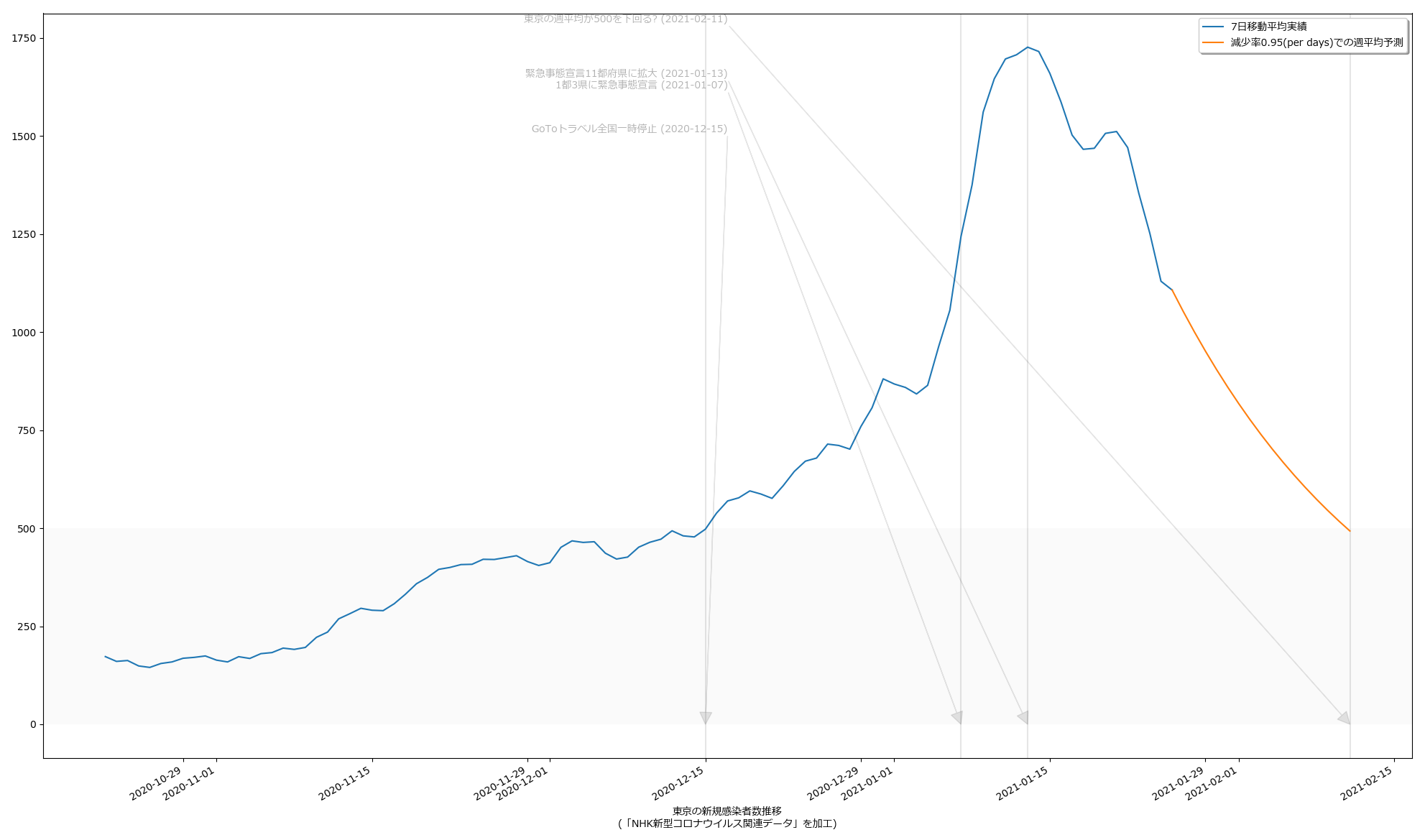
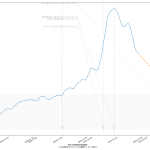
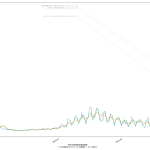
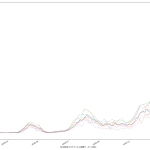
2月11日に500を下回る…のかな? どっちにしても2月7日には下回らなそうってことなんだけれど、思ってるよりは下げ幅が大きいんだよね。もっと時間がかかるんではないかと感じてたんだけれど。
まぁ毎週のことだけれど、木曜~土曜を超えないと、その週の真の姿は見えないのでね、それを待ったうえで再度予測するとどうなるか、てのが一つと、あと当然のことだけど「500の妥当性」ね。専門家の多くが言う「500では全然ダメ」にはワタシも同意してる。「医療逼迫」と騒がれだしたのが感染者数がどれだけだった時期かを思い起こしてみると、てことなんだよね、てのは肌感覚の話。それよりも、本来は、私が今回やった予測のような何がしか感染者数予測に基づいて「病床使用率予測」などをするのが本来は筋。そこまでやれば、宣言解除に足るのかどうかが、もっと誰にでもクリアなものになるんだと思う。「総合的に=なんとなく」では困るってことよさ。
10:00追記:
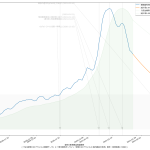
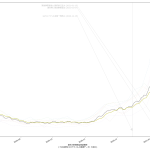
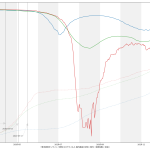
スクリプトは省略するけれど、一応「減少率を少なく見積もった場合」もやってみた:
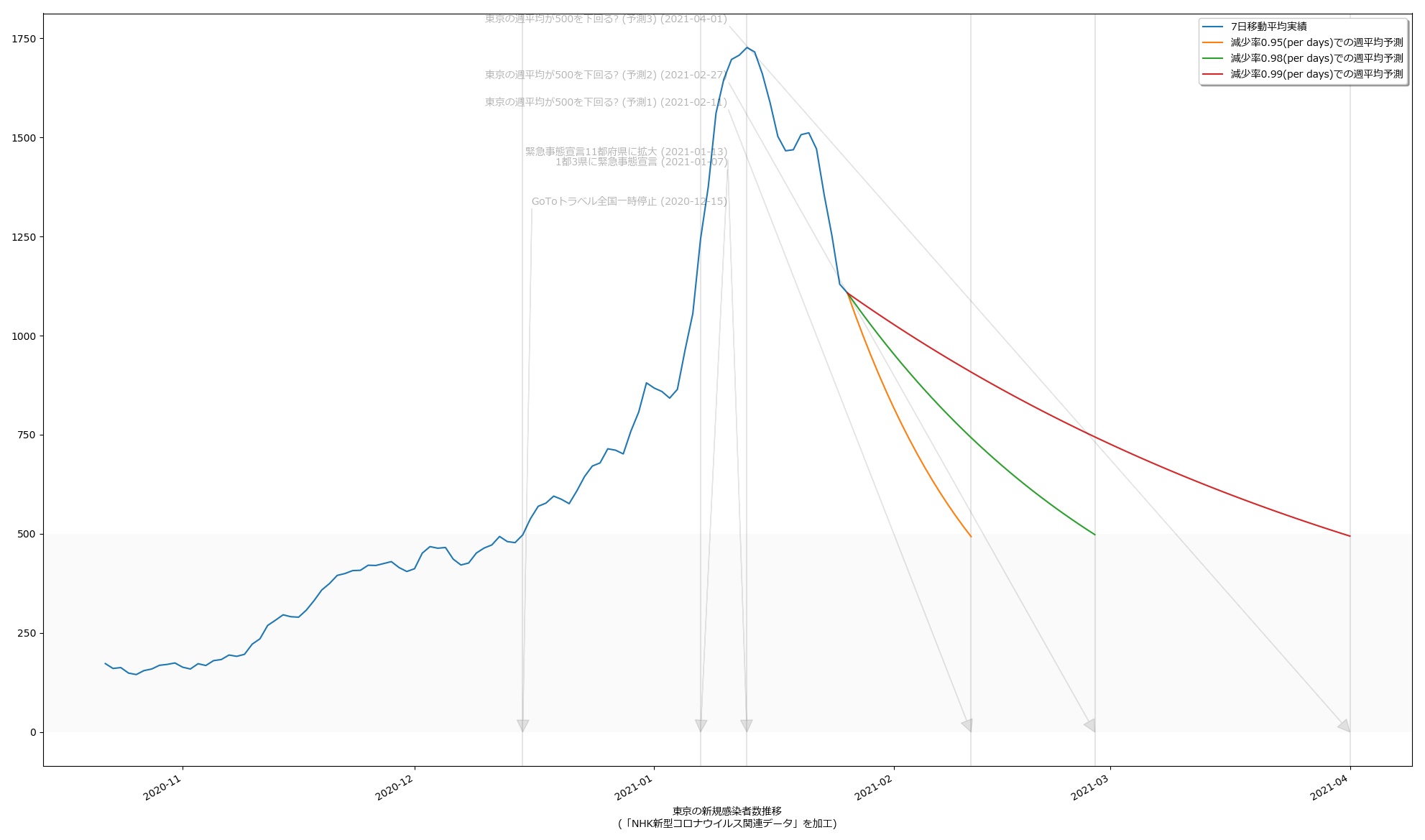
いわゆる「最悪の場合の想定」ってヤツだが、さすがに4月1日なんて結果を目にしたらやりきれなくなる。悪くても予測2の2月27日には達成して欲しいもんである。
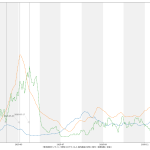
10:30追記:
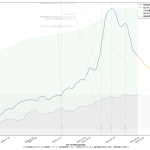
結果として日々5%ずつ減っていくとしたら、というシミュレーションにはなってるので、それを知りたいならなんにも間違いはないのだが、「日々5%」を計算で求めているつもりが、そうなってなさそう。なんだこれは、眠かったのか、あるいは…? 見直してみても何してるのか自分で理解できない。無根拠。この減少率を求めて…のつもりだったんだけどね、そうなってはなさそう。ごめん。