せっかくなのでもう少しだけ。
昨日のとは少し違う見方をしてみたやつ:
1 # -*- coding: utf-8 -*-
2 import io
3 import sys
4 import csv
5 import datetime
6 import numpy as np
7
8
9 def _tonpa(fn):
10 # rownum=2020/1/16からの日数, colnum=都道府県コード-1
11 result = {
12 "newpat": np.zeros((1, 47)),
13 "newpatmovavg": np.zeros((1, 47)),
14 "newdeath": np.zeros((1, 47)),
15 "newdeathmovavg": np.zeros((1, 47)),
16 }
17 era = "2020/1/16"
18 era = datetime.datetime(*map(int, era.split("/")))
19 reader = csv.reader(io.open(fn, encoding="utf-8-sig"))
20 next(reader)
21 for row in reader:
22 dt, (p, c, d) = row[0], map(int, row[1::2])
23 dt = (datetime.datetime(*map(int, dt.split("/"))) - era).days
24 if dt > len(result["newpat"]) - 1:
25 for k in result.keys():
26 result[k] = np.vstack((result[k], np.zeros((1, 47))))
27 result["newpat"][dt, p - 1] = c
28 result["newpatmovavg"][dt, p - 1] =
29 result["newpat"][max(0, dt - 7):dt + 1, p - 1].mean()
30 result["newdeath"][dt, p - 1] = d
31 result["newdeathmovavg"][dt, p - 1] =
32 result["newdeath"][max(0, dt - 7):dt + 1, p - 1].mean()
33 np.savez(io.open("nhk_news_covid19_prefectures_daily_data.npz", "wb"), **result)
34
35
36 if __name__ == '__main__':
37 fn = "nhk_news_covid19_prefectures_daily_data.csv"
38 _tonpa(fn)
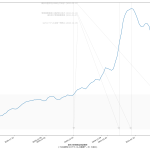
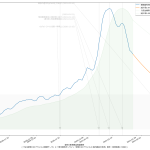
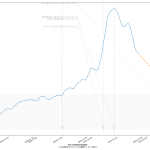
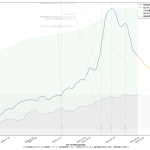
スクリプトをマジメに読んだ人は気付いたかもしれない。「8日平均」を計算しちゃってる。一連の「主張」の本題とはあまり関係ないとはいえ、さすがにもうちょっと慎重にやるべきでした、すまぬ。正しくは「dt – 6」「dt – 5」…「dt – 1」「dt」の7エレメントでの平均を取らなければならないので、「slice(dt – 6, dt + 1)」。8日平均が役に立たないわけではないけれど、やりたいこととやってることが違うので、間違いは間違い。グラフは滑らかさが若干減って、もうほんの少しだけガタガタになる。
1 # -*- coding: utf-8 -*-
2 import io
3 import datetime
4 import numpy as np
5 import matplotlib as mpl
6 import matplotlib.pyplot as plt
7 import matplotlib.font_manager
8
9
10 def _vis(dat):
11 era = "2020/1/16"
12 era = datetime.datetime(*map(int, era.split("/")))
13 npat = dat["newpat"][:,12] # 12: 東京 (都道府県コード13)
14 npatma = dat["newpatmovavg"][:,12]
15 #npat = dat["newpat"].sum(axis=1)
16 #npatma = dat["newpatmovavg"].sum(axis=1)
17 npatmadif = (npatma - np.roll(npatma, 1))
18 npatmadifacc = (npatmadif - np.roll(npatmadif, 1))
19
20 fontprop = matplotlib.font_manager.FontProperties(fname="c:/Windows/Fonts/meiryo.ttc")
21
22 T = [era + datetime.timedelta(t) for t in range(len(npat))]
23 #for t0 in range(0, len(T), 28):
24 for t0 in range(28, len(T) - 27):
25 tlast = min(len(T) - 1, t0 + 28)
26 cspan = slice(t0, tlast + 1)
27 pspan = slice(tlast, tlast + 7)
28
29 T2 = [era + datetime.timedelta(t) for t in range(pspan.start, pspan.stop)]
30 dtbeg, dtend = era + datetime.timedelta(t0), era + datetime.timedelta(tlast)
31 fig, ax1 = plt.subplots(tight_layout=True)
32 fig.set_size_inches(16.53, 11.69)
33 l2, = ax1.plot(T[cspan], npatma[cspan], color="blue")
34 # 予測1: 単に線形で延長
35 # 予測2: 二週前と前週の傾きの差を上積み
36 last = npatma[cspan][-1]
37 cdif = npatmadif[cspan.stop - 7:cspan.stop]
38 cdifacc = npatmadifacc[cspan.stop - 7:cspan.stop]
39
40 prd0 = last
41 prd1 = max(0, last + cdif.mean() * 7)
42 prd2 = max(0, last + (cdif.mean() + cdifacc.mean()) * 7)
43 l4, = ax1.plot(
44 T2, np.linspace(prd0, prd1 + 1, len(T2)), linestyle="dotted", color="black")
45 l5, = ax1.plot(
46 T2, np.linspace(prd0, prd2 + 1, len(T2)), linestyle="dotted", color="red")
47
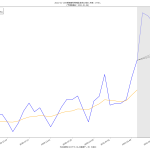
48 tit = "{}の新規陽性判明数週平均(東京)の素人予測: {}~{}人\n(予測実施日: {})".format(
49 str(dtend + datetime.timedelta(7)).partition(" ")[0],
50 int(prd1), int(prd2), str(dtend).partition(" ")[0])
51 ax1.set_title(tit, fontproperties=fontprop)
52 l3, = ax1.plot(T2[:len(npatma[pspan])], npatma[pspan], color="blue", alpha=0.2)
53 ax1.legend(
54 (l2, l4, l5),
55 ("新規陽性判明数週平均", "新規陽性判明数週平均予測1", "新規陽性判明数週平均予測2"),
56 shadow=True, prop=fontprop)
57 ax1.set_xlabel("「NHK新型コロナウイルス関連データ」を加工", fontproperties=fontprop)
58 plt.axvspan(T2[0], T2[-1], facecolor="lightgray", alpha=0.5)
59 fig.autofmt_xdate()
60 fig.savefig("result/{:04d}.png".format(t0))
61 #plt.show()
62 plt.close(fig)
63
64
65 if __name__ == '__main__':
66 fn = "nhk_news_covid19_prefectures_daily_data.npz"
67 _vis(np.load(io.open(fn, "rb")))
要は先日ちょっと言い足りなかったなぁと思ったついでに少し発展させた、てことに過ぎなくて。
前回バージョンは、説明しなかったけど、延長するための傾きを週平均に基づいて取りつつも未加工データのほうに足し合わせていた。求めた傾きをそのまま使わずに、せめて曜日ごとの検査数に基づく重みを掛けて使えば、もう少し現状に合うであろうことはわかっていたが、「中学生でも理解できる単純さ」を優先し、意図的にそれをやらなかった。「バカな素人予測」をやりたかったのだから。今回は「せめて曜日ごとの検査数に基づく重みを掛けて使」ってまで精度を良くする、なんて方向に発展することには価値を感じていないので、もっとシンプルに、週平均についての議論だけにしてしまおうと、生データの方は捨てた。ゆえ、この部分に限っていえば、「よりバカになった」と言える、「思考停止」という意味で。
「中学生でも理解できる」を維持したままの発展として、「増加率」の加味があるだろう。「速度・加速度」とか「一階微分、二階微分」という考えで発想すればこれは高校数学レベルとなるわけなのだが、「おとといから昨日で報告数が5人増え、昨日から今日で8人増えた」という場合に、「明日は、今日の件数+11人かもしれない」と予測するのは中学生でも理解出来、電卓でもそろばんでも筆算でも実施できる。こうした予測も、人によっては日常的に脳内でやってるかもしれない。「増え方が増える」と言えば小学生でも「何言ってるかはわかる」程度にはわかるだろうし。
「ワタシがやらかしたアホ予測のバージョンアップ」そのものについては、およそ、以上である。非常に単純な考えに基づくまさに「アホ予測」ではあるものの、実際こんなに簡単なのに細かくは考慮すべき点がいくつか(いくつも)あって、傾きとしてどれ(どこ(からどこ))を採るべきか、など、本当は言うほど簡単でもない。そしてそうした「よしあし」の研究は、まぁ「学問への一歩」でもある。そこまで発展させようとし始めれば、だんだん専門家の領域に近づいていき、一般人には手の届きにくいところに行くわけだ。
先日の主張を改めて続けよう。言い足りないと思ったこと、てことだ。
要は、ワタシのように「一週間後、やべー」と思考出来る人間と、「二週間前、まだやべーくねー」として手遅れになってから泡食っている「政治家ども」は、つまりは「同じ世界を見ていない」ということなわけだ。分科会までそうなのは非常に謎だけれど、ともかく「日々近未来予想をみている/みていない」のはっきりとした差が、緊張感の差なのであろう、ということ、なのだとしたら。
今回のアホ予測も「中学生でも理解できる」ものである。そして、ビデオを見てもらえばわかる通り、「予め一週間前にびっくりしておく」程度の目的には、割と適っているとみてよいと思う。つまり、どうにも報道は、慎重さのためか「こうしたことは専門家任せ」にしがちだし、普通はそれでいいんだけれど、ただ、「専門家が予測を出してこないから」という理由で予測を出していないことが遠因となって危機感のない政治家が爆誕しているんだとしたら、このように、結構簡単なんだから、メディア自身で日々予測を出したらいいんじゃないの、てのが、私の主張で、先日のでは言い足りないと思ったのは、この「同じ世界を見ていない」問題ね。
違う世界に住んでる問題てのはまぁ、特に永田町相手だと毎日のように感じるわけなんだけれど、少なくとも今般の新型コロナウィルス感染症の問題に関しては、「二週間前の行動の反映なのだから二週間後予測で議論しなければならない」ということがちゃんと届いていない人々がいる、てことがかなり大きな問題なんじゃないのか、てことなんだわ。一般人がそうなのは多少はやむを得ないと思うんだけれど、なんで専門家まで騙されてるんだ、と思いたくなるような発言してるよね、分科会。だいたいさ、なんで「本日ステージ3なのでおk」てなるん、「二週間後ステージ4なのでNG」と考えなきゃダメだと思わん?
なお、「二週間後に4千人に達する」という予測だけではもちろん不十分で、その予測を立てたのなら、二週間後の医療逼迫率の予測も立てる必要がある。こうしたものを、メディアは自前で試みてもいいし、あるいは誰かに要求するのでもいい。実際東京都のモニタリング会議は、大曲先生の発言から想像するに、ワタシの今回のアホ予測に似たことを結局日々やってる。だから、そうした予測をオープンにすることを要求するのでもいい。
毎日二週間後予測をみせられることで緊張感が変わる人々がどの程度多いかはわからない。けれども、「同じ未来予想図をみる」ことはとても必要なことだと思う。正直菅首相の頭をカチ割って中身みてみたいもん、きっと「後手後手な総理」時点では、間違いなく「今日おっけー」と、その日暮らし指向してたハズ。少なくともワタシにはそう見える。少なくとも国民が「遅すぎる」と感じるのは、ワタシがやってみせたラフな予測を、国民が脳内で無意識にやっていることの現れ、と言えると思う。