すぐに使ってやろうとか今の目的の MSBuild 式の評価で乗り換えようと今すぐに思ってるわけではないんだけれど。
一つ前で紹介しといた Python Parsing Tools をみてて、LR(1) のいいのがないかなぁと。ので lrparsing。
が、ドキュメント がどうもテクニカルな内容の方が先んじてて、「手っ取り早く小さな例を動かしてみたい」向きにはちょいキツかった。
なんか「読みやすくて書きやすそうな気配がする」ことまでは雰囲気がわかっても、「自分の目的に耐える」入り口になかなかたどり着けなくて弱る。どういうことかといえば:
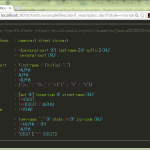
1 import lrparsing
2 from lrparsing import Keyword, List, Prio, Ref, THIS, Token, Tokens
3
4 class ExprParser(lrparsing.Grammar):
5 #
6 # Put Tokens we don't want to re-type in a TokenRegistry.
7 #
8 class T(lrparsing.TokenRegistry):
9 integer = Token(re="[0-9]+")
10 integer["key"] = "I'm a mapping!"
11 ident = Token(re="[A-Za-z_][A-Za-z_0-9]*")
12 #
13 # Grammar rules.
14 #
15 expr = Ref("expr") # Forward reference
16 call = T.ident + '(' + List(expr, ',') + ')'
17 atom = T.ident | T.integer | Token('(') + expr + ')' | call
18 expr = Prio( # If ambiguous choose atom 1st, ...
19 atom,
20 Tokens("+ - ~") >> THIS, # >> means right associative
21 THIS << Tokens("* / // %") << THIS,
22 THIS << Tokens("+ -") << THIS,# THIS means "expr" here
23 THIS << (Tokens("== !=") | Keyword("is")) << THIS)
24 expr["a"] = "I am a mapping too!"
25 START = expr # Where the grammar must start
26 COMMENTS = ( # Allow C and Python comments
27 Token(re="#(?:[^\r\n]*(?:\r\n?|\n\r?))") |
28 Token(re="/[*](?:[^*]|[*][^/])*[*]/"))
29
30 parse_tree = ExprParser.parse("1 + /* a */ b + 3 * 4 is c(1, a)")
31 print(ExprParser.repr_parse_tree(parse_tree))
こんな例が書かれてて、グラマーの定義そのものは、yacc とかに慣れてればおよそ雰囲気がわかるし、コメントも書かれてるしで、「あぁ、始められそうだ」とこれだけなら思うんだけれど、いざ「コピペしてきて動かしてみようとする」とハタと困るのだ:
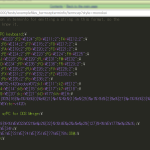
1 >>> print(ExprParser.repr_parse_tree(parse_tree))
2 (START (expr
3 (expr
4 (expr
5 (expr (atom '1')) '+'
6 (expr (atom 'b'))) '+'
7 (expr
8 (expr (atom '3')) '*'
9 (expr (atom '4')))) 'is'
10 (expr (atom (call 'c' '('
11 (expr (atom '1')) ','
12 (expr (atom 'a')) ')')))))
13 >>> # うん、よかね、木が返ってくるのね、理解できたら使い勝手が良かろう…
14 >>> # どうやってこの木を縦断すればいいのかな?
15 >>> parse_tree # をりゃ
16 (START = expr, (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%') << expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' |'!=' | 'is') << expr)), (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%') << expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' | '!=' | 'is') << expr)), (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%') << expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' | '!=' | 'is') << expr)), (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%') << expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' | '!=' | 'is') << expr)), (atom = T.ident=/[A-Za-z_][A-Za-z_0-9]*/ | T.integer=/[0-9]+/ | '(' + expr + ')' | call, (T.integer=/[0-9]+/, '1', 0, 1, 1))), ('+', '+', 2, 1, 3), (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%')<< expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' | '!=' | 'is') << expr)),(atom = T.ident=/[A-Za-z_][A-Za-z_0-9]*/ | T.integer=/[0-9]+/ | '(' + expr + ')' | call, (T.ident=/[A-Za-z_][A-Za-z_0-9]*/, 'b', 12, 1, 13)))), ('+', '+', 14, 1, 15), (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%') << expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' | '!=' | 'is') << expr)), (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%') << expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' | '!=' | 'is') << expr)), (atom = T.ident=/[A-Za-z_][A-Za-z_0-9]*/ | T.integer=/[0-9]+/ | '(' + expr + ')' | call, (T.integer=/[0-9]+/, '3', 16, 1, 17))), ('*', '*', 18, 1, 19), (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%') << expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' | '!=' | 'is') << expr)), (atom = T.ident=/[A-Za-z_][A-Za-z_0-9]*/ | T.integer=/[0-9]+/ | '(' +expr + ')' | call, (T.integer=/[0-9]+/, '4', 20, 1, 21))))), ('is', 'is', 22, 1, 23), (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%') << expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' | '!=' | 'is') << expr)), (atom = T.ident=/[A-Za-z_][A-Za-z_0-9]*/ | T.integer=/[0-9]+/ | '(' + expr + ')' | call, (call = T.ident=/[A-Za-z_][A-Za-z_0-9]*/ + '(' + (List(expr, ',')) + ')', (T.ident=/[A-Za-z_][A-Za-z_0-9]*/, 'c', 25, 1, 26), ('(', '(', 26, 1, 27), (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%') << expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' | '!=' | 'is') << expr)), (atom = T.ident=/[A-Za-z_][A-Za-z_0-9]*/ | T.integer=/[0-9]+/ | '(' + expr + ')' | call, (T.integer=/[0-9]+/, '1', 27, 1, 28))), (',', ',', 28, 1, 29), (expr = (Prioritised(atom), Prioritised(('+' | '-' | '~') >> expr), Prioritised(expr << ('*' | '/' | '//' | '%') << expr), Prioritised(expr << ('+' | '-') << expr), Prioritised(expr << ('==' | '!=' | 'is') << expr)), (atom = T.ident=/[A-Za-z_][A-Za-z_0-9]*/ | T.integer=/[0-9]+/ | '(' + expr + ')' | call, (T.ident=/[A-Za-z_][A-Za-z_0-9]*/, 'a', 30, 1, 31))), (')', ')', 31, 1, 32))))))
17 >>> # なんぢゃこりゃ
18 >>> type(parse_tree)
19 type('tuple')
んんん。
つまり ExprParser.repr_parse_tree すれば解析木を「わかりやすく」プリント出来ることは公式のサンプルからすぐにわかっても、「じゃぁ自分で木をトラバースするにはどうすれば?」がわかりやすく書かれてない。というかすぐには辿りつけない。
何より歯痒かったのが「examples」がリンク切れになってたこと。やむなくファイル名で検索したら GitHub に実体がいた。名前が違うのだが fork したとかは書かれてなくて…なんだろ、「python3 対応したるぜ」と思って fork するだけしてほとんど何もしてないとかってパターンだろか? (“Russell Stuart” != “Kunshan Wang”.) なんにせよこれはありがたくて。talk の例の方がワタシには手っ取り早かった:
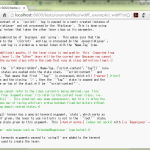
1 import operator
2 from lrparsing import *
3
4 class E(Grammar):
5 e = Ref("e")
6 number = Token(re="[0-9]+")
7 binary_expr = Prio(e << Token("/") << e, e << Token("+") << e)
8 unary_expr = Token("-") + e
9 e = Prio(number, unary_expr, binary_expr)
10 START = e
11
12 @classmethod
13 def eval_node(cls, n):
14 return n[1] if not "eval" in n[0] else n[0]["eval"](n)
15
16 binary_ops = {'+': operator.add, '/': operator.floordiv}
17 unary_ops = {'-': operator.neg}
18 number["eval"] = lambda n: int(n[1], 10)
19 binary_expr["eval"] = lambda n: E.binary_ops[n[2]](n[1], n[3])
20 unary_expr["eval"] = lambda n: E.unary_ops[n[1]](n[2])
21
22 print(E.parse("2 + 3 / -1", tree_factory=E.eval_node))
lambda や operator ばかりなので初見だと読みづらいが、まぁそんなのは普通にメソッドなりにすりゃぁいいだけのこと。ともあれこの例がワタシにとっては十分にヘロワルドとして機能した。
辞書? "eval" というキーがお約束なのか、自由にやれや、てことなのかはまだ読みきれてないけれど、なんにせよこれから書き換えて遊べば、すぐに何か「面白くないもの」は作れるだろう。(関数電卓なんか多分すぐだろう。)
てわけで今のところ印象は良い。