かなりイマサラなネタなんだけれども、「NOAA の Magnetic Declination Estimated Value 計算サービスを python から使う」を書いた際にちと思い出したもんで、自分的には「改めて」。
Contents
Converting xml to dictionary using ElementTree
大前提
- ワタシは xml は大嫌いである。…どうでもいい?
てなはなしではなくて。好き嫌い関係ねーでしょ、必要なときには必要だ、っと。
他の場所でも書いたことがあるんだけれども、Python の xml インフラは、整ってるともいえるし整ってないともいえる、のね。「Pythonic」という意味で、イケてるぜぇ、て部分がある一方で、肝心のパーサが標準では expat しか持ってないてことが結構な大問題になることがある。特にこれな:
Expatは、Pythonのように多くのエンコードをサポートしておらず、またエンコーディングのレパートリを拡張することはできません; サポートするエンコードは、UTF-8, UTF-16, ISO-8859-1 (Latin1), ASCII です。 encoding [1] が指定されると、文書に対する明示的、非明示的なエンコード指定を上書き (override) します。
どっかでも書いたけど、「いまどき utf-8 以外使うかいな」ってのは、「おバカさんにはちっとも常識じゃない」なんて、この業界ではザラです。つまり「shift-jis じゃないなんて自己中だ」と吹聴してまわる「自称技術者」は今だって後を経たないのだ、ってこと。当然のことながらそういうのに限って発言力があったり政治力がある。
ので、「標準 python 以外使いたくない」事情がない限りは、lxml入れといた方がいい。
今回ネタにしてる etree は、python 標準ライブラリにもあり、lxml にもあります。全く同じものではないけれど、ちょっと手を入れれば lxml でも標準 python でも動きます。ケド、lxml が使えず、xml が shift-jis とかだとアウトです。パーサで落っこちちゃう。
1 Traceback (most recent call last):
2 File "qqqq.py", line 15, in <module>
3 tree = etree.parse("some.xml")
4 File "<string>", line 62, in parse
5 File "<string>", line 38, in parse
6 ValueError: multi-byte encodings are not supported
StackOverflowより
ここね。
大きく2つの answer が人気がある。
Answer 1
一つ目の短いほうは、少しだけ書き換えれば要はこう:
1 try:
2 from lxml import etree
3 except ImportError:
4 from xml.etree import cElementTree as etree
5
6 def etree_to_dict(t):
7 tag = t.tag
8
9 d = {tag: map(etree_to_dict, list(t))}
10 d.update(('@' + k, unicode(v)) for k, v in t.attrib.iteritems())
11 d['text'] = unicode(t.text)
12
13 return d
unicode 関係は適宜どうにかしてみてくださいな。たとえば:
1 from io import BytesIO
2 tree = etree.parse(BytesIO("""
3 <root>
4 <e />
5 <e>text</e>
6 <e name="value" />
7 <e name="value">text</e>
8 <e> <a>text</a> <b>text</b> </e>
9 <e> <a>text</a> <a>text</a> </e>
10 <e> text <a>text</a> </e>
11 </root>
12 """))
13 d = etree_to_dict(tree.getroot())
14
15 import json
16 print(json.dumps(d, indent=2))
では結果はこう:
1 {
2 "text": "\n ",
3 "root": [
4 {
5 "text": "None",
6 "e": []
7 },
8 {
9 "text": "text",
10 "e": []
11 },
12 {
13 "@name": "value",
14 "e": [],
15 "text": "None"
16 },
17 {
18 "@name": "value",
19 "e": [],
20 "text": "text"
21 },
22 {
23 "text": " ",
24 "e": [
25 {
26 "a": [],
27 "text": "text"
28 },
29 {
30 "text": "text",
31 "b": []
32 }
33 ]
34 },
35 {
36 "text": " ",
37 "e": [
38 {
39 "a": [],
40 "text": "text"
41 },
42 {
43 "a": [],
44 "text": "text"
45 }
46 ]
47 },
48 {
49 "text": " text ",
50 "e": [
51 {
52 "a": [],
53 "text": "text"
54 }
55 ]
56 }
57 ]
58 }
この回答者自身がこう言ってる:
This works as long as you don’t actually have an attribute text; if you do, then change the third line in the function body to use a different key. Also, you can’t handle mixed content with this.
text というタグを持つ要素やら属性で困るぞ、mixed content は扱えないぞ、てことな。ただそれだけじゃなくて、あんまし嬉しくない構造だと思う。現実のまともな xml で使ってみればわかるんだけど、ちょうど DOM を使ってるときに感じるストレスと全く同じ「どこまでいってもリストだらけ」で苦しむことになる。(要素が一つしかないことが既知だろうと [0] を必要とするので、たとえば d['xxx'][0]['yyy'][0]['zzz'][0] みたいなことになる。)
Answer 2
結論からはこっちが吉。長いのでちょっとイヤにはなりそうだけれども。
1 try:
2 from lxml import etree
3 except ImportError:
4 from xml.etree import cElementTree as etree
5
6 from collections import defaultdict
7
8 def etree_to_dict(t):
9 d = {t.tag: {} if t.attrib else None}
10 children = list(t)
11 if children:
12 dd = defaultdict(list)
13 for dc in map(etree_to_dict, children):
14 for k, v in dc.iteritems():
15 dd[k].append(v)
16 d = {t.tag: {k:v[0] if len(v) == 1 else v for k, v in dd.iteritems()}}
17 if t.attrib:
18 d[t.tag].update(('@' + k, v) for k, v in t.attrib.iteritems())
19 if t.text:
20 text = t.text.strip()
21 if children or t.attrib:
22 if text:
23 d[t.tag]['#text'] = text
24 else:
25 d[t.tag] = text
26 return d
さっきと同じく unicode まわりは適宜どうにかしてみて。
回答者による説明にある通り、このマッピングはこれ↓に従ったもの:
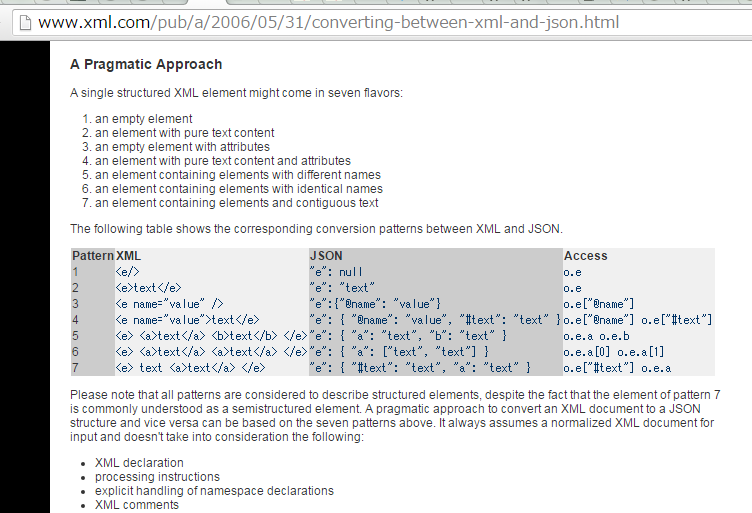
さっきと同じく:
1 from io import BytesIO
2 tree = etree.parse(BytesIO("""
3 <root>
4 <e />
5 <e>text</e>
6 <e name="value" />
7 <e name="value">text</e>
8 <e> <a>text</a> <b>text</b> </e>
9 <e> <a>text</a> <a>text</a> </e>
10 <e> text <a>text</a> </e>
11 </root>
12 """))
13 d = etree_to_dict(tree.getroot())
14
15 import json
16 print(json.dumps(d, indent=2))
結果:
1 {
2 "root": {
3 "e": [
4 null,
5 "text",
6 {
7 "@name": "value"
8 },
9 {
10 "#text": "text",
11 "@name": "value"
12 },
13 {
14 "a": "text",
15 "b": "text"
16 },
17 {
18 "a": [
19 "text",
20 "text"
21 ]
22 },
23 {
24 "a": "text",
25 "#text": "text"
26 }
27 ]
28 }
29 }
遥かに使いやすいのですわ。
実際「@」だとか「#text」だとかがどーなんだ、てのはあるにはあるんだけれど、回答者曰く:
Not necessarily pretty, but it is unambiguous, and simpler XML inputs result in simpler JSON.

ちなみにこれの逆変換も書かれてるんで、必要であればそっちも参考にしてみれば?
StackOverflow での Answer 2 でもちょいと不満
namespace がくっついた xml を扱ってみればすぐにわかる。
たとえば VisualStudio のプロジェクトファイルを扱うとこんなことに:
1 {
2 "{http://schemas.microsoft.com/developer/msbuild/2003}Project": {
3 "{http://schemas.microsoft.com/developer/msbuild/2003}ItemDefinitionGroup": [
4 {
5 "{http://schemas.microsoft.com/developer/msbuild/2003}Link": {
6 "{http://schemas.microsoft.com/developer/msbuild/2003}SubSystem": "Console",
7 "{http://schemas.microsoft.com/developer/msbuild/2003}AdditionalLibraryDirectories": "$(OutDir)",
8 "{http://schemas.microsoft.com/developer/msbuild/2003}AdditionalDependencies": "Geographic_d.lib",
9 "{http://schemas.microsoft.com/developer/msbuild/2003}GenerateDebugInformation": "true"
10 },
11 "{http://schemas.microsoft.com/developer/msbuild/2003}ClCompile": {
12 "{http://schemas.microsoft.com/developer/msbuild/2003}PrecompiledHeader": "",
13 "{http://schemas.microsoft.com/developer/msbuild/2003}WarningLevel": "Level4",
14 "{http://schemas.microsoft.com/developer/msbuild/2003}Optimization": "Disabled",
15 "{http://schemas.microsoft.com/developer/msbuild/2003}AdditionalIncludeDirectories": "../include;../man",
16 "{http://schemas.microsoft.com/developer/msbuild/2003}PreprocessorDefinitions": "WIN32;_DEBUG;_CONSOLE;%(PreprocessorDefinitions)"
17 },
18 "@Condition": "'$(Configuration)|$(Platform)'=='Debug|Win32'"
19 },
20 ...
これの置き換えのシカケは欲しいでしょうよ。あとさ…、値をフィルタしたくない? たとえば上の例だと、セミコロン区切り(Windows のパスのリスト)をリストとしたい、とか。
てなわけで、たとえばこんなんが嬉しいのかな、と思う:
1 # -*- coding: utf-8 -*-
2 #
3 import re
4 # ↓lxml も使いたければここ書き換えてみて。
5 try:
6 from xml.etree import cElementTree as ET
7 except ImportError:
8 from xml.etree import ElementTree as ET
9 from collections import defaultdict
10
11
12 _TAGSUB_RGX = re.compile(r'^\{[^{}]+\}')
13 DEFAULT_TAGSUB=lambda s: _TAGSUB_RGX.sub('', s)
14 DEFAULT_VALUECONVERTER=lambda k, v: v
15
16
17 #
18 #
19 #
20 def etree_to_dict(
21 tree,
22 tagsub=DEFAULT_TAGSUB,
23 valueconverter=DEFAULT_VALUECONVERTER):
24
25 tag = tagsub(tree.tag)
26 d = {tag: {} if tree.attrib else None}
27 children = list(tree)
28 if children:
29 dd = defaultdict(list)
30 for dc in (etree_to_dict(c, tagsub, valueconverter) for c in children):
31 for k, v in dc.iteritems():
32 dd[k].append(v)
33 d = {
34 tag: {
35 k: v[0] if len(v) == 1 else v for k, v in dd.iteritems()}}
36 if tree.attrib:
37 d[tag].update(
38 ('@' + k, valueconverter('@' + k, v))
39 for k, v in tree.attrib.iteritems())
40 if tree.text:
41 text = tree.text.strip()
42 if children or tree.attrib:
43 if text:
44 d[tag]['#text'] = valueconverter(tag, text)
45 else:
46 d[tag] = valueconverter(tag, text)
47 return d
48
49
50 #
51 #
52 #
53 def xmlfile_to_dict(
54 xmlfile,
55 tagsub=DEFAULT_TAGSUB,
56 valueconverter=DEFAULT_VALUECONVERTER):
57
58 doc = ET.parse(xmlfile)
59 return etree_to_dict(
60 doc.getroot(), tagsub, valueconverter)
tagsub でタグ名の置換、valueconverter でリーフのテキストをなにがしか変換する。たとえば:
1 xmlfile_to_dict(
2 "some.vcxproj",
3 valueconverter=lambda k, v: v.split(";") if ";" in v else v)
みたいな具合に使う。
まぁまぁかな…。