出来合いのソフトウェアを探し回って疲れ果てるくらいなら作ってしまった方が早い、と考えるタイプの、なおかつ、毎度短時間で書いてしまって整理しないので何度も書くハメになる、あるいは zip なんかこの世から消えてしまいたまえ。
探せばありそうな気は毎度するんだけどね、Windows であってもMSYS生活なワタシにとっては、スクリプト書いちゃえばいいじゃん、という類の、「zip だったものを別のアーカイバで再圧縮」なタスク。
だって毎度10分かからんで書けてしまいますもの、シェルスクリプトで。普段ならこんなかな:
1 #! /bin/sh
2 trap 'rm -fr .tmp' 0 1 2 3 15
3
4 for i in "$@" ; do
5 rm -fr ".tmp"
6 bn=`basename $i .zip`
7 mkdir ".tmp"
8 unzip "$i" -d ".tmp"
9 ( # sub-shell
10 cd ".tmp"
11 tar cvf ../"${bn}".tar * && bzip2 -9v ../"${bn}".tar
12 ) && rm -fv "$i"
13 done
今ほんとに10分以内で書いた。正確に測ってないけど、多分5分くらい。だからこそ整理しないまま下手すりゃ、というか確実に「紛失」し、忘れ去り、何ヶ月も何年も経ってから「出来合いのソフトウェアを探し回って疲れ果てるくらいなら作ってしまった方が早い」を繰り返す。最初から残すつもりないんだもん、aaa.sh なんて名前にするのは、ほんとに毎度。あぁバッドサイクル。
でさ、一生このままバッドサイクル繰り返したって別に死にやしないと思うんだけど、今回立体地形図を作りたいてことから、国土地理院の基盤地図情報を結構大量にダウンロードしていて、「今でしょ」なタイミングかなと思って。何せ非力なネット環境で苦労してダウンロードしてるもんだから、もったいなくて消せないけれど、圧縮率のとっても低い zip だもんで、かさばってしょーがないし。これからも興味のある地域のをダウンロードし続けるからさ、さすがに今回は「残る」ものがいい。
マイクロソフトが Windows XP で正式搭載してからというもの、残念ながら「zip が最もポータブルなアーカイバ」になってしまった。デファクトスタンダードといってよい。なんであれ標準めいたものを決定付けたマイクロソフトの功績は大きいとは思うものの、いかんせん、「なんでよりによって zip」。ほんとうは、真に「エンドユーザ目線」では、圧縮率を重視して欲しい。「いつでもどこででも使える」というポータビリティは、多くの場合はフリーソフトウェア群が「追いついて来る」から、どこかの大きな組織が「決断」さえしてしまえば、ユーザは結構平気で付いてくるはずである。(zip の日本語ファイル問題も致命傷だと思うんだけどなぁ。)
てわけで、「国土地理院の基盤地図情報」なんてさぁ、「デラ・でっかい」わけっす。メジャーじゃなくても高圧縮なものを使う、て決断、出来ないもんなんだろうか?
とはいえなにゆえにそういう決断ができないのかは想像がつく。一つには「エンドユーザのため」(思い込み)。一つには「標準だから」(あなたの決断次第で世界は変わるかもしれないのに)。一つには「標準インフラで作れるから」(スキルがないだけ)。一つには「周囲を説得できないから」(する気もないくせに)。たぶんきっとおそらく確実に絶対に、エンドユーザ不在の決断しか出来ないわけだ。
なんでエンドユーザ目線では「圧縮率最優先」と思うのか? 20年前じゃあるまいし。いや、それは違う。ディスクを湯水のように使えるようになれば、「人はほんとうに湯水のように使う」ので、ファイルサイズは大きくなる一方だ。ネットワークが高速になれば、「人は転送サイズに無頓着になる」ので、取り回しに苦労する大きなサイズのファイルは増える一方だ。ところが一方では、最近はコストパフォーマンスの良さやタブレット端末の普及により、光回線よりも無線回線が選ばれることが多く、むしろ存分に快適とは言えないネット環境を持つユーザは、一昔前とそんなに変わらなくなって来てるんじゃないか?
企業が業務で使うデータが「大きい」場合に一番困るのは、最初にワールドワイドなネットから持ってくる際ではない。企業内 LAN 内の「ファイルサーバ」との行き来が大変なのだ。どこでもかしこでも高速回線で繋いでいるわけではない。大抵の企業では、1GB のファイルを移動するだけでも大変なことになるであろう。ある程度のサイズになってくると、自PCで長時間かけて「圧縮」してから長時間かけて移動した方が、圧縮しないまま移動するよりも何百倍も早い場合がある。例えば圧縮に1時間かけて10分で移動出来るのに、そのまま移動すると10時間かかる、なんてザラだ。
つまりファイルが大きければ大きいほど、LAN 環境が普通であれば普通であるほど、「圧縮率こそが高速化の鍵」というのは、至極もっともな話なのである。移動に10時間かかるファイルを2つ、なんて、丸一日作業ぶっとびかねんぞ。そんなヘビィな移動、PCの CPU パワーも喰らうしな。
てわけで、zip なんかなくなってしまえばいいのに。
なんて極端な議論はまぁ脇に置いといて。だいたいにして、Microsoft だけじゃなくて、zip 依存のもの、多過ぎるもん。Python の egg とか wheel もだし、Java の jar もだし。実際なくなったらワタシだって泣くよ。
最初に書いたシェルスクリプトじゃなくて、整理して残しておこうと思ったのは Python で作ったヤツ。MSYSの古いやつを使ってると unzip は標準で入ってないしね。Python だと zip, tar, gzip, bzip2 が標準で使えるし。
てわけで、「不完全過ぎる zip2tar」:
1 #! /bin/env python
2 # -*- coding: utf-8 -*-
3 import sys
4 import os
5 import tarfile
6 import zipfile
7 import StringIO
8 import calendar
9 import datetime
10 import argparse
11
12
13 _ts = int((datetime.datetime.now() -
14 datetime.datetime.utcnow()).total_seconds())
15
16
17 def _process_one_zip(
18 zfn,
19 remove_original_zip,
20 compressor,
21 compresslevel):
22
23 if compressor == "bz2":
24 op = tarfile.TarFile.bz2open
25 ext = ".bz2"
26 else:
27 op = tarfile.TarFile.gzopen
28 ext = ".gz"
29
30 with zipfile.ZipFile(zfn, 'r') as zf:
31 with op(
32 os.path.splitext(zfn)[0] + ".tar" + ext,
33 mode="w",
34 compresslevel=compresslevel) as tf:
35
36 for zi in zf.infolist():
37 d = zf.read(zi)
38 ti = tarfile.TarInfo(zi.filename)
39 ti.size = zi.file_size
40 ti.uname = os.environ["USERNAME"]
41 ti.gname = os.environ["USERNAME"]
42 ti.mtime = calendar.timegm(zi.date_time) - _ts
43 cont = StringIO.StringIO(d)
44 tf.addfile(ti, cont)
45 print("%s: %s" % (zi.file_size, zi.filename))
46 if remove_original_zip:
47 try:
48 os.unlink(zfn)
49 print("remove %s" % zfn)
50 except IOError as e:
51 print(str(e))
52
53
54 if __name__ == '__main__':
55 parser = argparse.ArgumentParser()
56 parser.add_argument('zipfile', nargs='+')
57 parser.add_argument(
58 '--remove-original-zip', action='store_true', default=False)
59 parser.add_argument(
60 '--level', type=int, default=9)
61 parser.add_argument(
62 '--compressor', choices=["bz2", "gz"], default="bz2")
63 args = parser.parse_args(sys.argv[1:])
64
65 for zfn in args.zipfile:
66 _process_one_zip(
67 zfn,
68 args.remove_original_zip,
69 args.compressor,
70 args.level)
tarfile、zipfile は毎日使うもんではないんで、「一瞬で」は書けてないけど、多分初版は1時間以内で書いたと思う。欲が出て「gzip にも出来るようにしとこう」「圧縮率も変えたい」とやってたら1時間は超えた。こうなってくると「毎度毎度」書きたくはない。ちゃんと残ってないとイヤン。
どんだけ「不完全」か? 簡単に列挙しとく。
- zip内がフォルダ階層を持ってる場合のテストを一切してない(ダメかもしんない)
- 日本語ファイル名が含まれてたらお亡くなることでせう。
- でもどーせzip内の日本語ファイル名、ぶっ壊れるから、いいんでね? (utf8だったりcp932だったりするがそれを区別する方法がない
- ↑に関連し、PAX_FORMATについての戦略を考えるべきなのね、ほんとはね。
- undocument な仕様(tarfile.TarFile.bz2open、tarfile.TarFile.gzopen)への依存。
- しかもそれって Python 3.x では違う場所。
- ていうか Python 2.7 でしか動きません。
- エントリの属性(日付・ユーザなど)にはかなり無頓着。これは Windows と Unix 両方に色目使うと致し方ないところもあるので許せ。
- といいつつ Windows の MSYS をベースに作ったので、環境変数 USERNAME は Unix ではアヤシイ。これ、確か Windows 固有だったような? (今手許ですぐさま linux 動かす気にはなれないので確認はしません。
- 属性に使える情報取得には「Unixでしか使えない」os関数が必要だったりすんのよ。
なんてこと書くと全然使い物にならんほど酷いものに感じるかもしれんけど、別にそうでもないよ。今のワタシには十分。必要に応じて育てればいいことであるし。
ところでほんとは「毎度探し回るのがイヤで」というのは、今回は少しウソ。ちょっとだけ探ったの。zip⇔7zipを CUI でやりたくてさ。公式 7zip はコマンドラインから使いにくいし、ってことで、Python から使える 7zip のラッパーはないかしら、と。これはあったんだけれど、libarchive という Unix 生まれのライブラリへの ctypes ラッパーだった。ということはつまり、libarchive の Windows 版が必要、ということになる。うーん、後にしよう、と。
その Python ラッパーはサンプルコードを見る限り、とても使いやすそうだったので、興味はあるんだけれども、libarchive のハードルの高さがわからんのでね。こういうの、ダメなときは全然ダメだからねぇ。
さて。「立体地形図を作りたい」でこれまでダウンロードしてきた「基盤地図情報 数値標高モデル」なんだけれども、気付いたら 1337 個も持っていた。これでもせいぜい関東と東海北陸の一部と宮城県のみ、なのね、すげーサイズになっておる。これを件のスクリプトで、tar + bzip2 (圧縮レベル9) に全部再圧縮してみた。なお、これをするのに起こったのがこれ。
せっかくなので、zip 時点でのファイルサイズを記録しておき、再圧縮後のファイルサイズも記録した。感覚的にはだいたいいつでも半分くらいのサイズにはなるのはわかっているのだが、実際の正確なところを見ておきたい。サイズの記録はこんなよ:
1 me@host: ~$ stat -c '%n: %s' *.zip | sort > size_zip.txt
2 me@host: ~$ stat -c '%n: %s' *.bz2 | sort > size_bz2.txt
結果の抜粋:
1 FG-GML-4839-56-DEM5A.zip: 580748
2 FG-GML-4939-46-DEM5A.zip: 1312806
3 FG-GML-4939-55-DEM5A.zip: 655821
4 FG-GML-4939-56-DEM5A.zip: 4394515
5 FG-GML-5039-64-DEM5A.zip: 1879913
6 FG-GML-5039-65-DEM5A.zip: 120052
7 FG-GML-5137-75-DEM5A.zip: 152167
1 FG-GML-4839-56-DEM5A.tar.bz2: 362235
2 FG-GML-4939-46-DEM5A.tar.bz2: 839239
3 FG-GML-4939-55-DEM5A.tar.bz2: 416133
4 FG-GML-4939-56-DEM5A.tar.bz2: 2824203
5 FG-GML-5039-64-DEM5A.tar.bz2: 1249817
6 FG-GML-5039-65-DEM5A.tar.bz2: 68765
7 FG-GML-5137-75-DEM5A.tar.bz2: 75430
抜粋した範囲では、2/3~1/2くらい? これを正確に見たいわけ。
中身は全部が同じ形式の XML (GML) なわけなので、「圧縮率のバリエーション」の真の姿を現すものではないけれど、このサイズ比を可視化して、わかった気になってみたいな、と思ってさ。
ヒストグラムでも作ってみるか:
1 # -*- coding: utf-8 -*-
2 # size_zip.txt
3 # FG-GML-4839-56-DEM5A.zip: 580748
4 #
5 # size_bz2.txt
6 # FG-GML-4839-56-DEM5A.tar.bz2: 362235
7 d = {}
8 for fn in ("size_zip.txt", "size_bz2.txt"):
9 with open(fn, "r") as fi:
10 for line in fi.readlines():
11 line = line.strip()
12 if not line:
13 break
14 n, s = line.split(": ")
15 n = n.split(".")[0].replace(
16 "FG-GML-", "").replace(
17 "DEM", "")
18 if n not in d:
19 d[n] = [int(s)]
20 else:
21 d[n].append(float(s))
22
23 import numpy as np
24 import matplotlib.pyplot as plt
25
26 num_bins = 50
27
28 n, bins, patches = plt.hist(
29 [100 * d[k][1] / d[k][0] for k in d],
30 num_bins,
31 #normed=1,
32 facecolor='green',
33 alpha=0.5)
34
35 bz2total = sum((d[k][1] for k in d))
36 ziptotal = sum((d[k][0] for k in d))
37 plt.title(
38 "bz2 total: {:.1f} [MBytes]\nzip total: {:.1f} [MBytes]\n{:.1f} [%]".format(
39 bz2total / (1024.**2),
40 ziptotal / (1024.**2),
41 bz2total / ziptotal * 100))
42
43 plt.grid(True)
44 plt.xlabel('(size of bz2) / (size of zip) [%]')
45 plt.ylabel('Occurs')
46 #plt.subplots_adjust(left=0.15)
47 #plt.show()
48 plt.savefig("size_vis_hist.png", bbox_inches="tight")

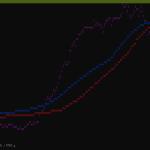
ふーん、凄いね。最悪でも 75% のサイズにはなってる。1337 個だからそれなりの母集団。これまでの感覚には合うし、物によっては 1/5 のサイズにさえなってるね。全体ではおよそ 2/3 か。半分にはならない、のは、ピークが 65% あたりにあることから腑に落ちますな。
なんにしても bz2 の圧縮率が高いというよりは、zip の圧縮率が低い、てことね。
上の方で書いた「過激な文句」では触れなかったんだけれど、なんかね、基盤地図情報ダウンロードのサイト自体が重いみたいで、「あたしんち」のネットワーク環境に問題がなくてもとんでもない速度のことが多いのね。2MB ごときのダウンロードに10分かかっちゃう、みたいなことが頻発すんの。日によって、時間によっては数秒なのに。これ、随分前から「あたしんち」以外からもそうなので、そういうサイトなんだと思う。だからこそ、2MB が 1MB になるのはとんでもなく大きいわけで。だって10分が5分だよ? 10個ダウンロードするのに、100分が50分。全然違うでしょう。tar + bz2 でも 7zip でもいいんだけど、とにかくこういう「大きなファイルを大量に」配布するようなサービスは、ファイルを小さくする努力をして欲しいわけさ。
あんまり意味はないんだけれど、散布図も書いてみる:
1 # -*- coding: utf-8 -*-
2 # size_zip.txt
3 # FG-GML-4839-56-DEM5A.zip: 580748
4 #
5 # size_bz2.txt
6 # FG-GML-4839-56-DEM5A.tar.bz2: 362235
7 d = {}
8 for fn in ("size_zip.txt", "size_bz2.txt"):
9 with open(fn, "r") as fi:
10 for line in fi.readlines():
11 line = line.strip()
12 if not line:
13 break
14 n, s = line.split(": ")
15 n = n.split(".")[0].replace(
16 "FG-GML-", "").replace(
17 "DEM", "")
18 if n not in d:
19 d[n] = [int(s)]
20 else:
21 d[n].append(float(s))
22
23 import numpy as np
24 import matplotlib.pyplot as plt
25 from matplotlib.ticker import FormatStrFormatter
26
27 fig, ax = plt.subplots()
28 ax.xaxis.set_major_formatter(FormatStrFormatter('%.1f'))
29
30 ax.scatter(
31 [d[k][0] / (1024.**2) for k in d],
32 [100 * d[k][1] / d[k][0] for k in d])
33
34 ax.grid(True)
35 ax.set_xlabel('size of zip [MBytes]')
36 ax.set_ylabel('(size of bz2) / (size of zip) [%]')
37
38 #plt.show()
39 plt.savefig("size_vis_scatter.png", bbox_inches="tight")

何がわかるって、特に何もわからない気はするけれどもね。大きくなるほど圧縮しにくくはなるけれど、なんでしょうか、2~5MB あたりのサイズが苦手なのかしら? ちょっと特徴的な散布図だね。まぁ当たり前だけどファイルの中身に依存することなので、基盤地図情報数値標高モデルだけの集合では、特に何かが言えるわけではありませんよ。ので、色んなサンプルで試してみたくはなるよね。
えーっと、で、結局何が言いたかったんだっけか。
あ、「hoge命名はやめよう」だった。(ちげーよ。)
2022-01-18 追記:
まず Python 3.x での日本語問題に関しては このネタに 2021-07-04 に追記した。毎度泣きそうになる、zip てると。
んでね、ちいとばかし拡張したんだけれど、さすがにここに貼り付けての管理はうっといので、gist に:
2022-01-19 追記:
昨日追記のはこのネタの 2021-07-04 追記とともにあってもまだ「日本語なんかきらいだ」から抜け出せないんだよね。一応コードみてもらえればわかる通り、一番最初に書いたときにはやってなかった PAX_FORMAT 指示も出来るようにしてあるんだけれどそれでもなお。
理由はぶっちゃけ簡単で、ワタシが使ってる MSYS の tar、それに 7zip すらも、この PAX_FORMAT を理解しないから。のでせっかく正しく utf-8 エンコーディング出来ても、そいつらが展開時は「呪詛」る。せっかくのエッチなファイル名が禍々しいものとなってしまう。(まぁパス区切りの解釈もとちってフォルダが復元されないこともあるわいな。)
まぁあんまし気分は良くないけれど、「python ユーザであるワシとしては」、Python の tarfile 自身で展開する心意気が残念ながら良かろう:
1 [me@host: ~]$ py -3 -m tarfile -v -e えっちな音声.tar.bz2
2 'えっちな音声.tar.bz2' file is extracted.
あとちょっと細かい話なんだけれど、今回改めて作業をやり直してる中で「圧縮率」については考えを改める必要がある…というよりか言い方を気をつけないとなと思った。確かにテキスト主体のアーカイブを作ろうとすると zip の圧縮率は非常によくないのだけれど、逆にバイナリファイル…というか正確に言えば「もともと圧縮率が優秀なビデオや音声ファイル」相手に圧縮する場合、たぶんフォーマットの冗長性の関係だと思うんだけれど、どうやら gz、bz2、xz のいずれよりも zip が小さくなる。まぁこれは仕方ないんだよね。(zip ファイルをさらに zip 圧縮…を繰り返せばいずれ限りなくゼロになる…わけない、の法則。)
2022-01-23 追記:
tar のPAXフォーマットを解するアンパッカー、選択肢をもう一つ見つけた。Go の標準ライブラリね。まだ自分でお試ししてみてはいないけれど、ドキュメントによればちゃんと理解するようなのできっと展開出来ろう。
このライブラリの使用例は標準ライブラリのドキュメント自身にもあるが、管理を Gist でやってるこのブログ記事のもいいかもしんない。
Go についてのネタはここ数日ちょこちょこ書いてる(text/templateの話)。そことかでも書いてるけど、Windows 版の Go の、いま時点バージョンでの一番のおいしさって「特別なランタイム依存がない EXE を何も意識せずに素直に作れる」ことなのね。つまり、書くのにちょっと苦労したとしても、一度書いておけば、Windows であればおそらくあと10年でも20年でも使い続けられる EXE になる、てことなのよね。なのでちょっと苦労してみる価値はある、と思う。(これについて自分でやってみるかは今後のワタシの気分次第。今は「出来るハズだよ」のメモのみに留めとく。)
2022-01-24 10時追記:
Goでの tar アンパックをやってみようとしているのだが、その前に「流儀」の問題に気付いた。
今時点での Rev 6→8を見て欲しいのだが、これは何かというと「ディレクトリかどうかに応じて add_file する内容を変える」という、まぁ非常に当たり前のことをしている。
けれどもどうもこの「ディレクトリエントリ」を追加する流儀と追加しない流儀のどちらもあって、どちらもどうやら正しいらしいのね。7zip で zip にアーカイブしようとすればこれはディレクトリエントリが追加される。何でパックしたのかはわからないけれど、とあるダウンロードしてきたエロ音声zip は、階層を持っているのにフラットにファイルエントリだけが追加されていた。(なおかつ、どうも「ディレクトリエントリだけ先に固める」流儀もある模様。)
なんというかワタシの zip2tar として「ディレクトリエントリが入っていて然るべきなのに入ってないなら入れちまえ」ってやりたくなってる。というのも、この Untar 実践例掲載のブログ記事の真似をして作ると「ディレクトリエントリが予め最初の方にまとめられていて、なので先に MkdirAll 祭りれる」という構造になっつまっておるから。無論その Untar の作りもダメなんだけれど、でもそもそも「先にディレクトリエントリを固めておく」のって、結構便利なんじゃないかしら、と思ってね。
…、うん、そう。結局我慢しきれなくて「Goでの tar アンパックをやってみようとしている」。出来たらここに追記するつもり。
2022-01-24 13時追記:
ひとまず @skdomino 氏のあんましよろしくない例をほぼ丸パクリだが一応「階層を持っているのにフラットにファイルエントリだけが追加されている」ものでも問題なくアンパック出来る、なおかつ 「bzip2 でも無圧縮でも」対応したヤツ:
1 package main
2
3 import (
4 "io"
5 "os"
6 "path/filepath"
7 "archive/tar"
8 "compress/gzip"
9 "compress/bzip2"
10 "flag"
11 "fmt"
12 )
13
14 func EnsureDir(target string) error {
15 if _, err := os.Stat(target); err != nil {
16 if err := os.MkdirAll(target, 0755); err != nil {
17 return err
18 }
19 }
20 return nil
21 }
22
23 // Untar takes a destination path and a reader; a tar reader loops over the tarfile
24 // creating the file structure at 'dst' along the way, and writing any files
25 func Untar(dst string, r io.Reader) error {
26 tr := tar.NewReader(r)
27
28 for {
29 header, err := tr.Next()
30
31 switch {
32
33 // if no more files are found return
34 case err == io.EOF:
35 return nil
36
37 // return any other error
38 case err != nil:
39 return err
40
41 // if the header is nil, just skip it (not sure how this happens)
42 case header == nil:
43 continue
44 }
45
46 // the target location where the dir/file should be created
47 target := filepath.Join(dst, header.Name)
48
49 // the following switch could also be done using fi.Mode(), not sure if there
50 // a benefit of using one vs. the other.
51 // fi := header.FileInfo()
52
53 // check the file type
54 switch header.Typeflag {
55
56 // if its a dir and it doesn't exist create it
57 case tar.TypeDir:
58 if err := EnsureDir(target); err != nil {
59 return err
60 }
61
62 // if it's a file create it
63 case tar.TypeReg:
64 if err := EnsureDir(filepath.Dir(target)); err != nil {
65 return err
66 }
67 f, err := os.OpenFile(target, os.O_CREATE|os.O_RDWR, os.FileMode(header.Mode))
68 if err != nil {
69 return err
70 }
71
72 // copy over contents
73 if _, err := io.Copy(f, tr); err != nil {
74 return err
75 }
76 fmt.Println(target)
77
78 // manually close here after each file operation; defering would
79 // cause each file close to wait until all operations have completed.
80 f.Close()
81 }
82 }
83 }
84
85 func UncompReader(fn string) (io.Reader, error) {
86 ext := filepath.Ext(fn)
87 r, err := os.Open(fn)
88 if ext == ".tar" || err != nil {
89 return r, err
90 }
91 if ext == ".gz" || ext == ".tgz" {
92 return gzip.NewReader(r)
93 } else if ext == ".bz2" || ext == ".tbz2" {
94 return bzip2.NewReader(r), nil
95 }
96 panic("unknown format")
97 }
98
99 func main() {
100 var destdir string
101 fs := flag.NewFlagSet(os.Args[0], flag.PanicOnError)
102 fs.SetOutput(os.Stdout)
103 fs.StringVar(&destdir, "destdir", ".", "destination directory")
104 fs.StringVar(&destdir, "d", ".", "destination directory")
105 fs.Parse(os.Args[1:])
106 r, err := UncompReader(fs.Arg(1))
107 if err != nil {
108 panic(err)
109 }
110 //defer r.Close()
111 err = Untar(destdir, r)
112 if err != nil {
113 panic(err)
114 }
115 }
defer のコメントアウトが解せんのだわ。Close()メソッドを持つインターフェイス「io.ReadCloser」を返却したかったのに、bzip2.NewReader が「エラーは返さないし io.Reader でしかないし」てことで、bzip2 だけが異端で Closer を返せなかったの。一個のアーカイブしか相手にせずにそれ相手にしたら終わるだけ、の今のこの例に限れば Close() 出来ないことは何の問題も起こさないのでまぁいいんだけれど…。
あと、もはや「zip2tar」の Go バージョンも考えたくなってきたわよ。そこまでやっちゃうかも、今後の気分次第だけど。
2022-01-28 12時追記:
いまいちど「日本語なんかきらいだ」問題についての整理。こういうことである:
- 昔の zip の「非ASCII文字」の扱いは「仕様がない」かった。つまり「個々に個々」であり、そうして作られた zip がどんな文字コードを使っているのかを識別する術もなかった。
- 今の zip の「非ASCII文字」の扱いは「問答無用で utf-8」となった。詳細はあまりよく理解してないが一応この新形式かどうかは区別出来るみたい。(出来ないと勘違いしてたけど、zipfile.py でちゃんと区別してる。)
- 昔の tar は昔の zip と同じである。ただ、幸いなことにこれを使う文化は UNIX 系のみに偏っていたので、荒れ方はなんともならないというほどでもない、かったかもしれない、と信じたい。
- 「新しい掛け声に基づく tar」は「zip の二の舞にならないように」してあって、「ちゃんと拡張」してある。つまり「そうして作られた」ことを識別出来る。これが PAX フォーマット。
古い Python は 1. のものを問題なく扱える。というか「日本で作った SJIS な zip を、日本語版 Windows で動いている CPython で」問題ない。が、2. の扱いを誤る。対して、新しい Python は 2. のものを問題なく扱える代わりに、1. の扱いを誤る。正確にはコードページとして「cp437」を使う文字言語圏でのみ正しいが、日本ではダメ。そして、tar の PAX は Python 2.7 時代から既に使えたので「Python や新しいめの UNIX だけで生活する分には完全に救世主」であるものの、Windows でかなりメジャーな 7zip がこれを理解せず、また、MSYS のような古い UNIX (もどき) では tar コマンドそのものが PAX を知らない。
ここまではおけ?
で、「zip2tar を Go で作っちゃってもええんちゃうか」て気分になってる、と言ったけれど、それはこの「日本語なんか」問題の 1.、2. をクリアしててこそ、の話。どうなんだろうか、と思った、てわけ。
結論からは、状況としては今の新しい Python と似た状態。すなわち「zip は utf-8 なんだぞこのやろー」という掛け声に無垢に従った zip だけに対して正しいが、cp932 な zip はやっぱり呪詛る。お試しはひとさまのブログ記事のこれを一箇所書き換えるだけですぐに試せる。コードはなぜか固定ファイル名を入力としてるのでそれを「os.Args[1]」に変えるだけ。
そういうわけで、「zip2tar を Go で」はもうやることを夢見るのは今はやめておこうと思う。流通している zip が完全に utf-8 のものに置き換わった頃合いにはそれは嬉しいこともあるかもしれんけれど、あと何年かかるんだよ、てこと。今でもかなり sjis な zip は手に入ってしまう、残念ながら。まぁこれはひとまず諦めるしかないかなと。
それよかそもそも「旧 sjis zip から新 utf-8 zip へのコンバータ」を検討したくなってきたよ。Python の場合は Python 3.x 系の zipfile.py に手を入れることで可能だが、Go でやろうとする場合どうなるんだろうか? そもそも Go での文字コードの扱いはワタシには完全に未知の世界で、よくわからんのよね。あるいは全然別のインフラを使って可能だろうか? うん、ちょっと色々考えてみよう。頭が整理出来たらなんか書くかもしれん…し、まとまらなければ何も書かないかもしれない。見ていなっよってい…じゃなくて「未定な予定」もとい、予定は未定。
2022-01-28 15時追記:
「12時追記」後にすぐに考え直した。「いや、そもそも新しい zip に対応できているのであれば、固定の不明エンコーディングな zip に対応するために必要な箇所は特定出来るはずで、ゆえにソースコードを読みさえすれば、すぐに答えが見つかるんじゃね?」と。
Windows 版の場合、標準ライブラリのソースは c:/Program Files/Go/src/ の下に見つかる。「ソースも入れとくれ」みたいな指定をインストーラでした記憶はないが、少なくともワタシnGo ではそこにある。して案の定:
265 // readDirectoryHeader attempts to read a directory header from r.
266 // It returns io.ErrUnexpectedEOF if it cannot read a complete header,
267 // and ErrFormat if it doesn't find a valid header signature.
268 func readDirectoryHeader(f *File, r io.Reader) error {
269 var buf [directoryHeaderLen]byte
270 if _, err := io.ReadFull(r, buf[:]); err != nil {
271 return err
272 }
273 b := readBuf(buf[:])
274 if sig := b.uint32(); sig != directoryHeaderSignature {
275 return ErrFormat
276 }
277 f.CreatorVersion = b.uint16()
278 f.ReaderVersion = b.uint16()
279 f.Flags = b.uint16()
280 f.Method = b.uint16()
281 f.ModifiedTime = b.uint16()
282 f.ModifiedDate = b.uint16()
283 f.CRC32 = b.uint32()
284 f.CompressedSize = b.uint32()
285 f.UncompressedSize = b.uint32()
286 f.CompressedSize64 = uint64(f.CompressedSize)
287 f.UncompressedSize64 = uint64(f.UncompressedSize)
288 filenameLen := int(b.uint16())
289 extraLen := int(b.uint16())
290 commentLen := int(b.uint16())
291 b = b[4:] // skipped start disk number and internal attributes (2x uint16)
292 f.ExternalAttrs = b.uint32()
293 f.headerOffset = int64(b.uint32())
294 d := make([]byte, filenameLen+extraLen+commentLen)
295 if _, err := io.ReadFull(r, d); err != nil {
296 return err
297 }
298 f.Name = string(d[:filenameLen])
299 f.Extra = d[filenameLen : filenameLen+extraLen]
300 f.Comment = string(d[filenameLen+extraLen:])
301
302 // Determine the character encoding.
303 utf8Valid1, utf8Require1 := detectUTF8(f.Name)
304 utf8Valid2, utf8Require2 := detectUTF8(f.Comment)
305 switch {
306 case !utf8Valid1 || !utf8Valid2:
307 // Name and Comment definitely not UTF-8.
308 f.NonUTF8 = true
309 case !utf8Require1 && !utf8Require2:
310 // Name and Comment use only single-byte runes that overlap with UTF-8.
311 f.NonUTF8 = false
312 default:
313 // Might be UTF-8, might be some other encoding; preserve existing flag.
314 // Some ZIP writers use UTF-8 encoding without setting the UTF-8 flag.
315 // Since it is impossible to always distinguish valid UTF-8 from some
316 // other encoding (e.g., GBK or Shift-JIS), we trust the flag.
317 f.NonUTF8 = f.Flags&0x800 == 0
318 }
319 // ... 省略
つまり列挙されるエントリで「NonUTF8」という主張を返してくれるので、このフラグが立っていればゴニョればいいのだな、と理解。
Go での文字コードの扱いは未知…、そう、上で言った通り、やってみるのは今回が初なので、きっと「ダサい方法」なんだろうとは思うのだが、一応出来たんだわよ。ひとさまのブログ記事のこれをベースにして:
1 package main
2
3 import (
4 "archive/zip"
5 "fmt"
6 "io"
7 "bytes"
8 "bufio"
9 "log"
10 "os"
11 "path/filepath"
12 "strings"
13 "golang.org/x/text/encoding/japanese" // 要 go get
14 "golang.org/x/text/transform"
15 )
16
17 func main() {
18 files, err := Unzip(os.Args[1], "output-folder")
19 if err != nil {
20 log.Fatal(err)
21 }
22
23 fmt.Println("Unzipped:\n" + strings.Join(files, "\n"))
24 }
25
26 // Unzip will decompress a zip archive, moving all files and folders
27 // within the zip file (parameter 1) to an output directory (parameter 2).
28 func Unzip(src string, dest string) ([]string, error) {
29
30 var filenames []string
31
32 r, err := zip.OpenReader(src)
33 if err != nil {
34 return filenames, err
35 }
36 defer r.Close()
37
38 for _, f := range r.File {
39 var fname string
40 if f.NonUTF8 {
41 enc := japanese.ShiftJIS
42 tr := transform.NewReader(bytes.NewBuffer([]byte(f.Name)), enc.NewDecoder())
43 sc := bufio.NewScanner(tr)
44 for sc.Scan() {
45 fname += string(sc.Bytes())
46 }
47 } else {
48 fname = f.Name
49 }
50
51 // Store filename/path for returning and using later on
52 fpath := filepath.Join(dest, fname)
53
54 // Check for ZipSlip. More Info: http://bit.ly/2MsjAWE
55 if !strings.HasPrefix(fpath, filepath.Clean(dest)+string(os.PathSeparator)) {
56 return filenames, fmt.Errorf("%s: illegal file path", fpath)
57 }
58
59 filenames = append(filenames, fpath)
60
61 if f.FileInfo().IsDir() {
62 // Make Folder
63 os.MkdirAll(fpath, os.ModePerm)
64 continue
65 }
66
67 // Make File
68 if err = os.MkdirAll(filepath.Dir(fpath), os.ModePerm); err != nil {
69 return filenames, err
70 }
71
72 outFile, err := os.OpenFile(fpath, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, f.Mode())
73 if err != nil {
74 return filenames, err
75 }
76
77 rc, err := f.Open()
78 if err != nil {
79 return filenames, err
80 }
81
82 _, err = io.Copy(outFile, rc)
83
84 // Close the file without defer to close before next iteration of loop
85 outFile.Close()
86 rc.Close()
87
88 if err != nil {
89 return filenames, err
90 }
91 }
92 return filenames, nil
93 }
このやり方で進める場合「ShiftJIS 以外」を扱う手段がない。というか、あったとしても「手動の巨大な静的ディスパッチャ」が必要になる。世界に現存する文字コード種ぶんの。むろん import も。ので、文字コード変換部分はほかのライブラリに委ねるべき。という問題は確かにあるんだけれど、でも「NonUTF8」という目印があって、このフラグが立ってれば文字コード変換すればよいと判断可能、という設計になってること自体が非常にありがたいことで、こういうことであれば、ちゃんと整理したくなる。つまり「旧zipから新zipへのコンバータ」と「zip2tar の Go バージョン」の両方をちゃんと書いてみようという気になる。
実際にそれをするかは気分次第、については変わらんけど、でも、最初に思ったよりはずっとやってみようと腰を上げる確率は高いと思う。まぁ期待せずに待っとってくれ。
2022-01-28 23時追記:
上で「勘違いしてたっ」と言ったことも勘違いだったことに気付いた。
- 昔の zip の「非ASCII文字」の扱いは「仕様がない」かった。つまり「個々に個々」であり、そうして作られた zip がどんな文字コードを使っているのかを識別する術もなかった。
- 今の zip の「非ASCII文字」の扱いは「問答無用で utf-8」となった。詳細はあまりよく理解してないが一応この新形式かどうかは区別出来るみたい。(出来ないと勘違いしてたけど、zipfile.py でちゃんと区別してる。)
- 昔の tar は昔の zip と同じである。ただ、幸いなことにこれを使う文化は UNIX 系のみに偏っていたので、荒れ方はなんともならないというほどでもない、かったかもしれない、と信じたい。
- 「新しい掛け声に基づく tar」は「zip の二の舞にならないように」してあって、「ちゃんと拡張」してある。つまり「そうして作られた」ことを識別出来る。これが PAX フォーマット。
古い Python は 1. のものを問題なく扱える。というか「日本で作った SJIS な zip を、日本語版 Windows で動いている CPython で」問題ない。が、2. の扱いを誤る。対して、新しい Python は 2. のものを問題なく扱える代わりに、1. の扱いを誤る。正確にはコードページとして「cp437」を使う文字言語圏でのみ正しいが、日本ではダメ。そして、tar の PAX は Python 2.7 時代から既に使えたので「Python や新しいめの UNIX だけで生活する分には完全に救世主」であるものの、Windows でかなりメジャーな 7zip がこれを理解せず、また、MSYS のような古い UNIX (もどき) では tar コマンドそのものが PAX を知らない。
こう上で書いたけれど、この「出来ないと勘違いしてたけど」部分、実は勘違いじゃなかった。Go のライブラリ実装を読み直してて理解した。コメントはこう説明している:
Might be UTF-8, might be some other encoding; preserve existing flag.
Some ZIP writers use UTF-8 encoding without setting the UTF-8 flag.
Since it is impossible to always distinguish valid UTF-8 from some
other encoding (e.g., GBK or Shift-JIS), we trust the flag.
つまり「正しくは、「utf-8 を使う新形式を使っておるのぞ」とちゃんと高らかに宣言した上で utf-8 にせねばならぬ」のだがそうせずに問答無用で utf-8 やがったヤツらもおる」てハナシで、その「ヤツら」とは、ワタシの薄い記憶によれば Microsoft。だったと思う。何かでこの情報を読んで怒りを感じた記憶があるのよね。で、その「怒りを感じた」ときにはワタシは「正しくは」をちゃんと理解してなかったのだけは確かで、つまりやっぱり誤解そのものはしてたんだよね。
そういうわけで、「識別できない形で utf-8 っておるのもおる」ことにも備えるためにも、「shiftjis 固定」はダメ、てこと。すなわち golang.org/x/text/encoding の世界でやってては埒が明かないんである。で探し回ったら、ようやっと mahonia を見つけた。iconv だの python でサポートされてるエンコーディング群だのに較べて品揃えが少ないような気もするが、少なくともいわゆる CJKV のものは揃っているみたいなので、まぁ困る人は少ない気がするよね。うん、これを使ってみよう。てわけで、「zip2tar を Go で」の前段の「shiftjis 固定でない unzip を Go で」:
1 package main
2
3 import (
4 "archive/zip"
5 "fmt"
6 "io"
7 "log"
8 "os"
9 "path/filepath"
10 "strings"
11 "github.com/ogier/pflag"
12 "github.com/axgle/mahonia"
13 )
14
15 type UnarchArgs struct {
16 src string
17 destdir *string
18 dirheadEncoding *string
19 }
20
21 func main() {
22 arg := UnarchArgs{}
23 arg.dirheadEncoding = pflag.StringP(
24 "encoding", "e", "shiftjis", "specify encoding of directory header")
25 arg.destdir = pflag.StringP(
26 "destdir", "d", ".", "specify destination directory")
27 ousage := pflag.Usage
28 pflag.Usage = func() {
29 ousage()
30 os.Exit(1)
31 }
32 pflag.Parse()
33 arg.src = pflag.Arg(0)
34
35 files, err := Unzip(arg)
36 if err != nil {
37 log.Fatal(err)
38 }
39
40 fmt.Println("Unzipped:\n" + strings.Join(files, "\n"))
41 }
42
43 // Unzip will decompress a zip archive, moving all files and folders
44 // within the zip file (parameter 1) to an output directory (parameter 2).
45 func Unzip(arg UnarchArgs) ([]string, error) {
46
47 var filenames []string
48
49 r, err := zip.OpenReader(arg.src)
50 if err != nil {
51 return filenames, err
52 }
53 defer r.Close()
54
55 for _, f := range r.File {
56 var fname, fpath string
57 if f.NonUTF8 {
58 dec := mahonia.NewDecoder(*arg.dirheadEncoding)
59 fname = dec.ConvertString(f.Name)
60 } else {
61 fname = f.Name
62 }
63 if *arg.destdir == "." {
64 fpath = "." + string(os.PathSeparator) + fname
65 } else {
66 fpath = filepath.Join(*arg.destdir, fname)
67 }
68
69 // Check for ZipSlip. More Info: http://bit.ly/2MsjAWE
70 if !strings.HasPrefix(fpath, filepath.Clean(*arg.destdir) + string(os.PathSeparator)) {
71 return filenames, fmt.Errorf("%s: illegal file path", fpath)
72 }
73
74 filenames = append(filenames, fpath)
75
76 if f.FileInfo().IsDir() {
77 // Make Folder
78 os.MkdirAll(fpath, os.ModePerm)
79 continue
80 }
81
82 // Make File
83 if err = os.MkdirAll(filepath.Dir(fpath), os.ModePerm); err != nil {
84 return filenames, err
85 }
86
87 outFile, err := os.OpenFile(fpath, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, f.Mode())
88 if err != nil {
89 return filenames, err
90 }
91
92 rc, err := f.Open()
93 if err != nil {
94 return filenames, err
95 }
96
97 _, err = io.Copy(outFile, rc)
98
99 // Close the file without defer to close before next iteration of loop
100 outFile.Close()
101 rc.Close()
102
103 if err != nil {
104 return filenames, err
105 }
106 }
107 return filenames, nil
108 }
pflagの話はこのネタの中に書いた。試した中ではマシなコマンドラインパースね。(完全に満足はしてないけど標準のよりはずっと良い、てなことを書いた。)
さて、ここまで出来ていれば zip2tar の Go バージョンはすぐだ。が、そこまでやるかどうか…? まぁ気分がノッたらね、やるよ。
2022-01-30 14時追記:
お待ちかねかね:
「まだやってない」は割とある。たとえばファイル属性の維持はまだやりきってないし、パスワード付き zip への措置もしてない。tar であれば、シンボリックリンクの対応なんぞもあるがやってない。けど、そういうのはおいおいで必要に感じ次第やってくと思う。
今のところもとの Python 版より良くなってるのは「zip の日本語ファイル名の問題は完全な措置が出来ている、ハズ」というのと、Python 版では考えもしてなかった「再アーカイブではなく展開」。後者は「PAX フォーマットを理解するアンパッカーをお手持ちじゃない」という場合に役に立つ。
にしても標準ライブラリの bzip2 パッケージにライターがないのは無念だ…。
2022-02-21追記:
Pythonのほうでもやってなかったけど、Goのほうのでパスワード付き zip を扱おうとして、絶賛果ててる中。
あぁ、サポートされてないんだ…。この issue に登場してくれている yeka さんのを始めいくつか encrypted 対応した fork が見つかったが、見つけた二つ(yeka/zip、alexmullins/zip)ともに今度は「utf-8 問題への措置」が取り込まれてない。むむ…。自力でこれらに「utf-8 問題への措置」を取り込んだものを作るのは難しくはないけれど…。
今これ以外にも果てて中なのよね…。lzh と rar もやっておこうかと思ったのだけれど、lzh は全くインターフェイスが合わない上にたった一つのバージョンの lzh にしか対応してないものしか見つかってなくて。これはやる価値ないなぁと思っている。
パスワード付き zip についても lzh についても、アンパッカーを外部プロセスに頼るモードもあるといいかなぁ、とはちょっと思っている。気力があったら…。
2022-02-23追記:
「アンパッカーを外部プロセスに頼るモード」はやっといた。7z など、パッカーのほうを、というのも思うことは思うんだけれど、そちらは保留中。こまごま小さな問題があってやりにくいもんで。
把握している「やりたきこと」は:
* ファイル名エンコーディングについて、zip 以外のケースでも
– パスワード付き zip を外部プロセスで展開して既に呪詛済みの場合への措置のため
* シンボリックリンク
* omit_root 的な
– tar の strip_component に似ているがそれそのものではなくて、単一のフォルダなら端折る、てやつ
てことにはなるんだけれど、どれもまぁやらんでもいいか、とも思うし。気力次第だな。特に最後のやつ、ほしいと思うことは多いのだけれど、「外部プロセスに頼る」ケースで厄介なんだよ、だから腰は重い。
ちなみに、普通のパッカー、つまり tar だの zip だの rar だの 7z だのいずれも「ファイル群を与えて固めることが出来る」:
1 [me@host: ~]$ tar zcvf aaa.tar.gz file1.txt file2.mp3 file3.wav
これをワタシの zip2tar は出来ないけれど、これを出来るようにするつもりはない。というのも、近い目的のことをする手段はあるから。例えばこうすればいい:
1 [me@host: ~]$ zip2tar -m "*.mp3" . pk.zip # カレントディレクトリ内の mp3
単一のフォルダだけを対象にする作りにしてるので tar などで出来ることが出来ないこともあるけれど、でも今例にした使い方で多くは足りると思うし、少なくともワタシにはその機能は必要ない。のでやらない。