これの追記には書いといたんだけれどもさ。
asr の例を書いといたけど、なんで「ametadata=mode=print:file=out.txt」しないかは、やってみればわかる。バグだと思うが、仕様だとぬかしやがる可能性もあるかもな。file= が文字列長を固定で扱うらしく、認識結果の文字列が長いとちょん切られてしまう。しかも改行コードも失われるので、結果のファイルが全然使い物にならない。…、てのは、公式として手に入る ffmpeg バイナリを使ってる限りわからなかったことなので…、「Docker バンザイ!!」。
このネタ、「野良ビルドを共有する」という発想のネタになるわけなんだけれど、実際にやってみて、やっぱりちょっと問題もあるかなと思った。依存物がすべて「-dev」なのでその分大きくなるのと、「ビルド過程を共有」したいと思うと、ソースツリーや一時ファイルも消したくないな、てことがあって、どうしてもサイズがデカくなってしまうのね。/hhsprings/ffmpeg-yours は 3GB を超えてしまった。
なお、ocr も asr も、まぁ想像通りというか、精度は良くない。あと日本語用があるのかどうかは知らない。使えるようになったものだと、ocv の例がちょっと面白いかもと思った。
2022-06-05追記:
こちらもどぞ:
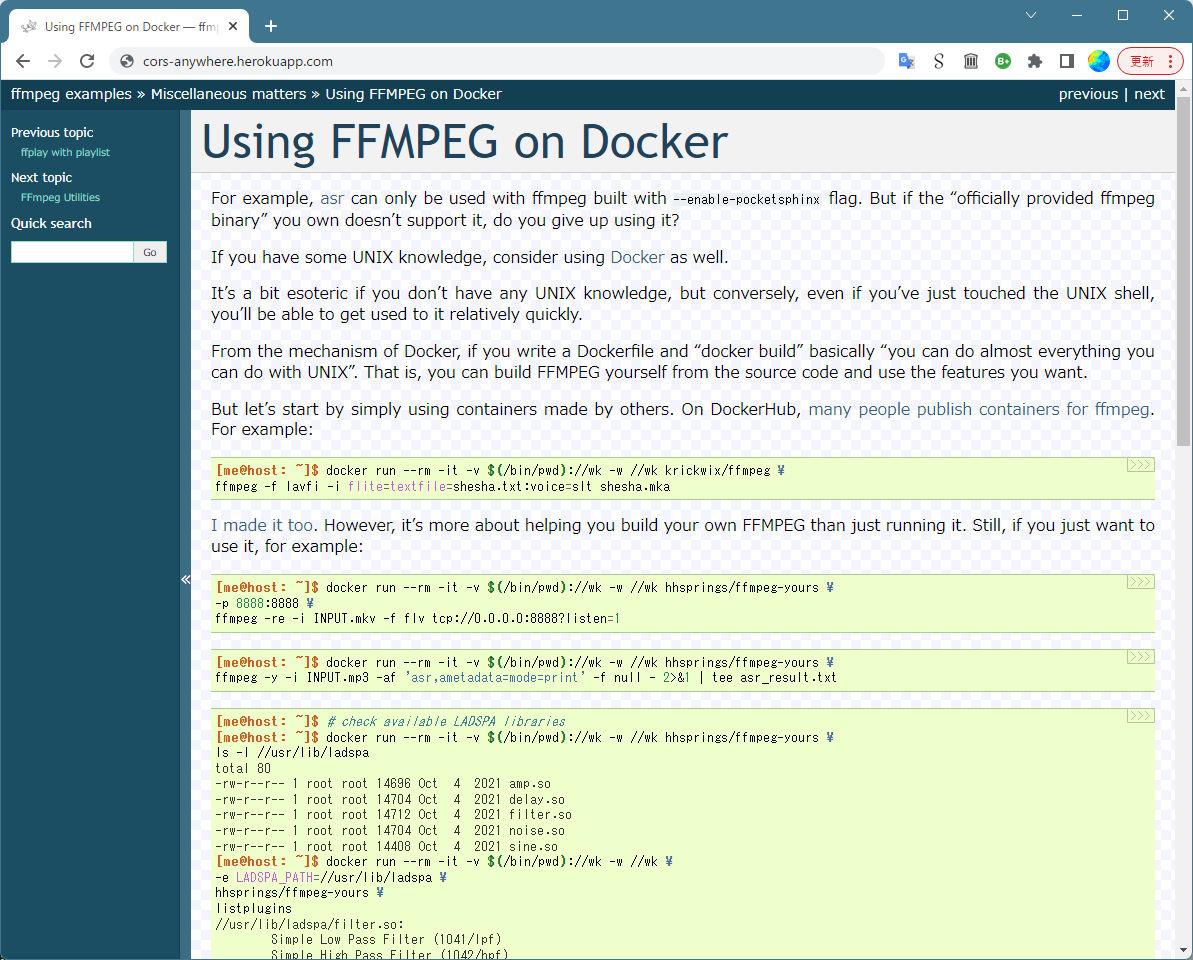
LADSPA、frei0r を使う例を書いてる。