ワレ的には「ついに」てネタ。
先延ばしてたんだよね、思ってはいたけれど。ここ数日の「Tabulator のバージョンを最新に乗り換える」話とは一応独立したネタ。
個人的ニーズはテレビ朝日の番組「声優パーク建設計画VR部」内のコーナー「声優世代表を作ろう!」のおともに使える表が欲しい、そして、そのアプローチとして「Python で wikipedia をスクレイプして、その結果を Tabulator な html に仕立て上げる」としたわけだ。で、(1) → (2) → (3) (→ (4))の、「技術ネタ」の本題は「Tabulator の新しいバージョンへの乗り換え」だったのだが、技術ネタとともにワタシには「声優世代表のおとも、そのもの」も本題なわけで、なのでスクリプトの進化といっしょに、扱う声優の数もガンガン増やしていた。
当然の話だが、量が増えてくればそれにともなう問題も出てくる。スクリプトの処理時間がかかる問題は(どうせオフラインなので)あまり気にしないとして、ブラウザも重くなることもあるが、一番最初に致命傷になったのが、ワタシのケースでは「Wordpress の制限」だった。あなたが今目にしているこのページは WordPress で管理していて、こんなふう:
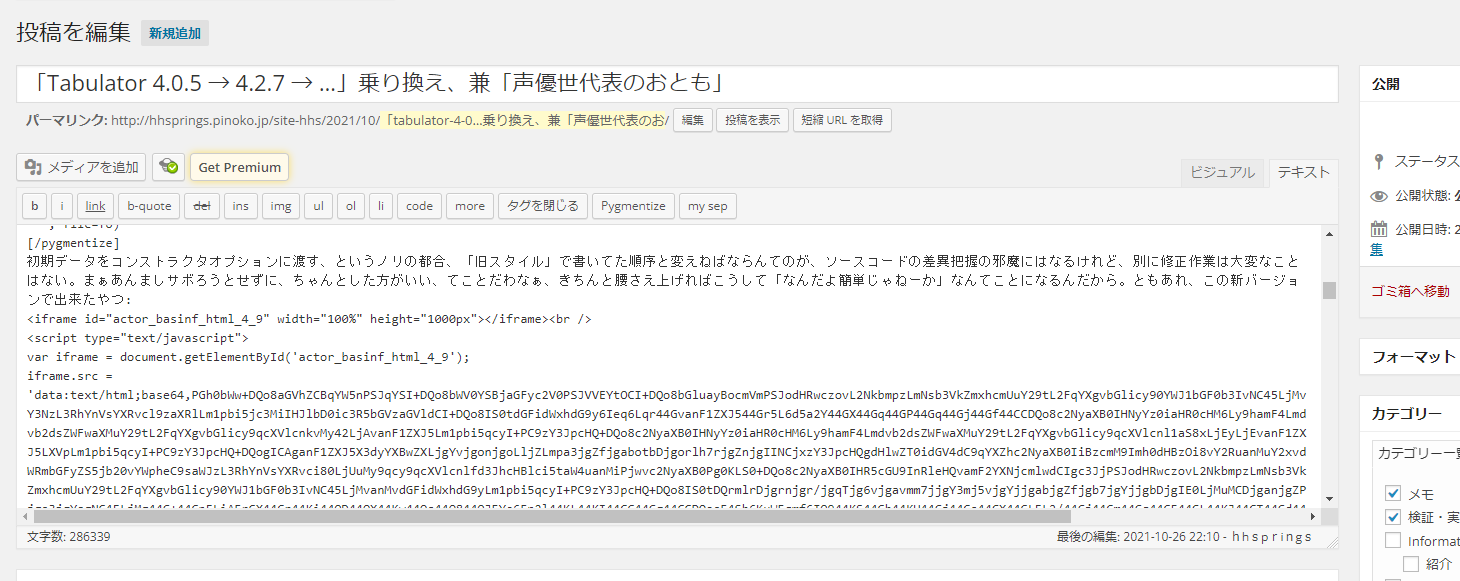
に編集しているのだが、この絵のテキストボックス内のテキストが、ワタシのこのケースではロリポップサーバ内に配置された MySQL データベースのカラムとして格納される。今回初めて知ったのだがこの列サイズの制限にひっかかると、編集画面にはなんのエラー報告もなく空っぽのページを生成してしまうらしい。「Tabulator 実例を完全な形のものとして紹介する」ための手法としてワタシが採っているのがキャプチャ画面でみえている通り生成した html ページ全体を data-uri にしてしまってワタシのブログ管理を簡単にする、というアプローチなので、今回の例のように生成 HTML が大きくなれば、MySQL に放り込まれるサイズもそれにともなって大きくなっていき、そしてカラムサイズ制限にひっかかる、てわけだ。
この、ワタシに固有の問題の有無に関わらず、いずれにしても「データ量との闘い」は必要である。似た話を、少なくとも3回書いている: 36進数、名前の切り詰めの話、数値表現の切り詰め。名前の切り詰めは、既に施してある(最初の版では「field」と「title」が同じだった)。また、「男性/女性」という文字列でなくコード化したり、生誕年度を文字列でなく数値にしたりもしてる。データの冗長さはなくせるならなくそうと少し努力もした(「名前」)。そしてまぁおよそほぼ「最後の一手」として今回のケースで効くのは無論、2つめのところで書いている通り、「key-value が全ての世界を救う…わけないのであって、適材適所、TPO」であり、今の場合、「コンパクトな csv 的なのでいいんだよなぁ」て話。「的」といってるのは、「key-value ではなくただのリスト」て意味ね、「カンマセパレーティッドな形式のファイルを入力とする」ことはひとまず置いといて、まずは単に javascript としてのリストが既存で、それを Tabuletor への入力とする話ね。「key がかさばるんだよ」てことだよ、わかるよね?
ただねぇ…。
探してはみるも、Tabulator は「csv を入力とする」ことをサポートしてはくれてないみたいなんだよね。ひとまずはこんなふうに自力でコンバートすりゃぁ、そらうまくはいく:
1 <!-- ... snip -->
2 <script>
3 /* ... snip ... */
4 var actor_basinf_data_csv =
5 [
6 [
7 "1920",
8 "1938",
9 "1920-08-03",
10 "",
11 1,
12 "高杉哲平",
13 "高杉哲平, たかすぎ てっぺい",
14 "",
15 "東京都",
16 "",
17 "",
18 "",
19 "",
20 ""
21 ],
22 [
23 "1922",
24 "1960年代",
25 "1922-11-09",
26 "2012-06-27",
27 2,
28 "高村章子",
29 "高村章子, たかむら あきこ, 高村 章子",
30 "O",
31 "長野県岡谷市",
32 "",
33 "153 cm / 60 kg",
34 "アドヴァンスプロモーション",
35 "",
36 ""
37 ],
38 /* ... snip ... */
39 ]
40 /* ... snip ... */
41 var actor_basinf_data = Array();
42 actor_basinf_data_csv.forEach(function (r, i) {
43 actor_basinf_data.push({
44 "by": r[0], /* 生誕年度 */
45 "as": r[1], /* 活動開始年? */
46 "bymd": r[2], /* 生年月日 */
47 "dymd": r[3], /* 没年月日 */
48 "gen": r[4], /* 性別 */
49 "wp": r[5], /* wikipedia */
50 "nm": r[6], /* 名前 */
51 "bld": r[7], /* 血液型 */
52 "bor": r[8], /* 出生地・出身地 */
53 "nn": r[9], /* 愛称 */
54 "tw": r[10], /* 身長/体重 */
55 "bel": r[11], /* 事務所・レーベル */
56 "fst": r[12], /* デビュー作 */
57 "tea": r[13], /* 共同作業者 */
58 })
59 })
60
61
62 var table = new Tabulator("#actor_basinf", {
63 /* ... snip ... */
64 "data": actor_basinf_data
65 });
66 </script>
ダサいよね、とは思うが、これしか思い浮かばない。
というわけでこれを生成するスクリプト全体としてはこうした(列もひとつ追加してる):
1 # -*- coding: utf-8 -*-
2 # require: python 3, bs4
3 """
4 「wikipedia声優ページ一覧」(など)を入力として、およそ世代関係を把握しやすい
5 html テーブルを生成する。
6
7 該当アーティストが情報を公開しているかどうかと wikipedia 調べがすべて一致する
8 かどうかは誰も保証出来ない。正しい公開情報が真実である保証もない。という、元
9 データそのものについての注意はあらかじめしておく。そして、wikipedia における
10 ペンディング扱い(「要出典」など)やその他補足情報はこのスクリプトは無視している
11 ので、「確実かそうでないか」がこの道具の結果だけでは判別出来ないことにも注意。
12 (wikipedia 本体を読んでいる限りは、正しくない可能性がまだ残っている場合、
13 そうであるとわかることが多い。)
14
15 ワタシの目下の目的が「声優世代表のおとも」なので、「生年月日非公開/不明」が困る。
16 なので、wikipedia が管理しようとしている「活動期間」を補助的に使おうと考えた。
17 これが活用出来る場合は「生誕年=活動開始-20年くらい」みたいな推測に使える。
18
19 この情報の精度には、当たり前ながらかなりのバラつきがあるし、要約の仕方も統一感
20 がない。たとえば「田中ちえ美」の声優活動は最低でも「サクラクエスト」の2017年に
21 始まっているが、当該ページ執筆者が「声優アーティスト活動開始」の定義に基いて
22 「音楽活動の活動期間は2021年-」と記述してしまっていて、かつ、声優活動としての
23 開始を記述していない。ゆえにこの情報だけを拾うと「田中ちえ美の活動期間は2021年-」
24 であると誤って判断してしまいかねない。そもそもが「サクラクエスト」にてキャラク
25 ターソングを出しているので、定義次第では「音楽活動の活動期間は2021年-」も誤って
26 いる。また、「2011年」のように年を特定出来ずに「2010年代」と要約しているページ
27 も多く、これも結構使いにくい。
28
29 ので、「テレビアニメ」などの配下の「2012年」みたいな年ごとまとめ見出しの最小値を、
30 活動期間の情報として補助的に拾ってる。
31
32 活動期間は年齢の推測にも使えるけれど、「声優世代表のおとも」として考える場合は、
33 生年月日と活動期間の両方が既知でこその面白さがある。たとえば黒沢ともよ、宮本侑芽、
34 諸星すみれ、浪川大輔などの子役出身者の例。あるいは逆に「遅咲き」と言われる役者。
35
36 なお、日本語版では不明となっているのに英語版には記載されていることがあり、この
37 スクリプトはそれも拾うが、これがアーティスト自身の公開非公開選択の方針とはより
38 ズレる可能性があることには一応注意。(日本語版では判明情報を本人方針尊重で隠して
39 いるのに、英語版ではそれが届いていない、のようなこと。)
40 """
41 import io
42 import os
43 import sys
44 import tempfile
45 import shutil
46 import ssl
47 import re
48 import json
49 import urllib
50 import urllib.request
51 from urllib.request import urlretrieve as urllib_urlretrieve
52 from urllib.request import quote as urllib_quote
53
54
55 import bs4 # require: beutifulsoup4
56
57
58 __MYNAME__, _ = os.path.splitext(
59 os.path.basename(sys.modules[__name__].__file__))
60 #
61 __USER_AGENT__ = "\
62 Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
63 AppleWebKit/537.36 (KHTML, like Gecko) \
64 Chrome/91.0.4472.124 Safari/537.36"
65 _htctxssl = ssl.create_default_context()
66 _htctxssl.check_hostname = False
67 _htctxssl.verify_mode = ssl.CERT_NONE
68 https_handler = urllib.request.HTTPSHandler(context=_htctxssl)
69 opener = urllib.request.build_opener(https_handler)
70 opener.addheaders = [('User-Agent', __USER_AGENT__)]
71 urllib.request.install_opener(opener)
72 #
73
74
75 _urlretrieved = dict()
76
77
78 def _urlretrieve(url):
79 if url in _urlretrieved:
80 return _urlretrieved[url]
81
82 def _gettemppath(s):
83 tmptopdir = os.path.join(tempfile.gettempdir(), __MYNAME__)
84 if not os.path.exists(tmptopdir):
85 os.makedirs(tmptopdir)
86 import hashlib, base64
87 ep = base64.urlsafe_b64encode(
88 hashlib.md5(s.encode("utf-8")).digest()
89 ).partition(b"=")[0].decode()
90 flat = os.path.join(tmptopdir, ep)
91 p1, p2 = ep[0], ep[1:]
92 d1 = os.path.join(tmptopdir, p1)
93 if not os.path.exists(d1):
94 os.makedirs(d1)
95 d2 = os.path.join(tmptopdir, p1, p2)
96 if os.path.exists(flat) and not os.path.exists(d2):
97 os.rename(flat, d2)
98 return d2
99
100 cachefn = _gettemppath(url)
101 if os.path.exists(cachefn):
102 res = cachefn
103 else:
104 try:
105 res, _ = urllib_urlretrieve(url, filename=cachefn)
106 except Exception:
107 from urllib.request import unquote as urllib_unquote
108 print(url, repr(urllib_unquote(url)))
109 raise
110 _urlretrieved[url] = res
111 return res
112
113
114 def _norm(s):
115 for f, r in (("(", "("), (")", ")"), ("・", "・")):
116 s = s.replace(f, r)
117 return s
118
119
120 def _try_get_actst(doc, actst, actst_rough):
121 # 活動開始をどうにか特定したい、ので、ヘディングで「1999年」としてるならまずはそれ、
122 # また、ヘディングが「出演」の配下にあるリスト項目の「~(1999年、…)」みたいな羅列
123 # を拾いたい、と思うわけだが、「html なのでこれは」なので(特に後者が)ひたすらに
124 # めんどいのよ。
125 validymin = 1900 # 日本の声優第一号の生誕から得るのがよかろうが、わからんのでてきとう
126 for stt, sta in (("dt", {}), ("b", {})):
127 # ヘディングから。<b>をヘディングにしてるのがいて迷惑…。
128 for dtt in [
129 dt.text
130 for dt in doc.find_all(stt, sta) if re.match(r"\d{4}年代?$", dt.text)]:
131 m = re.match(r"(\d+)年(代)?", dtt)
132 if not m.group(2):
133 v = int(m.group(1))
134 if v > validymin:
135 actst = min(v, actst)
136 else:
137 actst_rough.append(m.group(0))
138 if actst == 9999:
139 docs = str(doc)
140 m = re.search(r'<h2.* id="出演.*</h2>', docs)
141 if m:
142 _, rngs = m.span()
143 m = re.search(r'<h2.*.*</h2>', docs[rngs:])
144 if m:
145 rnge, _ = m.span()
146 sect = bs4.BeautifulSoup(docs[rngs:rngs + rnge], features="html.parser")
147 s = sect.text
148 for ys in re.findall(r"\((\d{4}[年.]代?)", s):
149 if ys[-1] == "代":
150 actst_rough.append(ys)
151 else:
152 v = int(ys[:-1])
153 if v > validymin:
154 actst = min(v, actst)
155 return actst, actst_rough
156
157
158 def _from_wp_jp(actorpagename):
159 baseurl = "https://ja.wikipedia.org/wiki/"
160 pn = urllib_quote(actorpagename, encoding="utf-8")
161 fn = _urlretrieve(baseurl + pn)
162
163 result = {"wikipedia": actorpagename, "名前": [actorpagename.partition("_")[0]]}
164 with io.open(fn, "r", encoding="utf-8") as fi:
165 soup = bs4.BeautifulSoup(_norm(fi.read()), features="html.parser")
166 entr = soup.find("a", {"class": "interlanguage-link-target", "lang": "en"})
167 if entr:
168 result["wikipedia_en"] = entr.attrs["href"]
169 try:
170 categos = [
171 a.text
172 for a in soup.find("div", {"id": "mw-normal-catlinks"}).find_all("a")]
173 except Exception:
174 categos = []
175 trecords = []
176 try:
177 trecords = iter(
178 soup.find("table", {"class": "infobox"}).find("tbody").find_all("tr"))
179 except Exception:
180 pass
181 if trecords:
182 tr = next(trecords)
183 if tr.find("th"):
184 tr = bs4.BeautifulSoup(
185 re.sub(r"<br\s*/?>", r"\n", str(tr)), features="html.parser")
186 for sp in tr.find("th").find_all("span"):
187 s = re.sub(r"\[[^\[\]]+\]", "", sp.text)
188 if "\n" in s:
189 result["名前"].extend(s.split("\n"))
190 else:
191 result["名前"].append(s)
192
193 actst = 9999
194 actst_rough = ["9999年代"]
195 for tr in trecords:
196 th, td = tr.find("th"), tr.find("td")
197 if not th or not td:
198 continue
199 k = th.text.replace("\n", "").replace(
200 "誕生日", "生年月日").replace("生誕", "生年月日")
201 k = re.sub("身長.*$", "身長/体重", k)
202 if k in ("事務所", "レーベル"):
203 k = "事務所・レーベル"
204 elif k in ("職業", "職種", "ジャンル",):
205 k = "occ"
206 v = ""
207 if td:
208 if td.find("li"):
209 td = "\n".join([li.text for li in td.find_all("li")])
210 elif td.find("br"):
211 td = bs4.BeautifulSoup(
212 re.sub(r"<br\s*/?>", r"\n", str(td)), features="html.parser").text.strip()
213 else:
214 td = td.text
215 v = re.sub(
216 r"\[[^\[\]]+\]", "\n", td).strip()
217 if k == "活動期間":
218 m = re.match(r"(\d+)年(代)?", v)
219 if m:
220 if not m.group(2):
221 actst = min(int(m.group(1)), actst)
222 else:
223 actst_rough.append(m.group(0))
224 continue
225 elif k in ("生年月日", "没年月日"):
226 m1 = re.search(r"\d+-\d+-\d+", v)
227 m2 = re.search(r"(\d+)年(\d+)月(\d+)日", v)
228 m3 = re.search(r"(\d+)月(\d+)日", v)
229 if m1:
230 v = m1.group(0)
231 elif m2:
232 v = "{:04d}-{:02d}-{:02d}".format(
233 *list(map(int, m2.group(1, 2, 3))))
234 elif m3:
235 v = "0000-{:02d}-{:02d}".format(
236 *list(map(int, m3.group(1, 2))))
237 else:
238 v = ""
239 v = re.sub(
240 r"(、\s*)+", "、",
241 "、".join(re.sub(r"\n+", r"\n", v).split("\n")))
242 if k in ("デビュー作", "事務所・レーベル", "共同作業者",):
243 v = "、".join(list(filter(None, [result.get(k), v])))
244 elif k == "occ":
245 v = "、".join(
246 list(
247 set("、".join(list(filter(None, [result.get(k, ""), v]))).split("、"))))
248 elif k == "身長/体重":
249 v = re.sub(r"\s*、\s*cm", " cm", v) # なんで??
250 result[k] = v
251 actst, actst_rough = _try_get_actst(soup, actst, actst_rough)
252 actst_rough_min = list(sorted(actst_rough))[0]
253 armv = int(re.match(r"(\d+)", actst_rough_min).group(1))
254 if actst < 9999 and armv // 10 > actst // 10:
255 result["actst"] = "{:04d}".format(actst)
256 elif armv < 9999:
257 result["actst"] = actst_rough_min
258 else:
259 result["actst"] = "0000"
260 if not result.get("生年月日"):
261 # infobox なしなのに律儀に生年月日は書いてる、てのが結構ある。
262 m = re.search(
263 r"[^、。()\n]+\s*\([^、。()\n]+、(\d{4}年)?(\d+月)?(\d+日)?[^()]*\)は、日本の",
264 soup.text)
265 if m:
266 yy, mm, dd = m.group(1, 2, 3)
267 if yy:
268 yy = int(yy[:-1])
269 else:
270 yy = 0
271 if mm and dd:
272 result["生年月日"] = "{:04d}-{:02d}-{:02d}".format(
273 yy, int(mm[:-1]), int(dd[:-1]))
274 elif mm:
275 result["生年月日"] = "{:04d}-{:02d}-??".format(
276 yy, int(mm[:-1]))
277 else:
278 result["生年月日"] = "{:04d}-??-??".format(yy)
279 else:
280 result["生年月日"] = "0000-??-??"
281 if not result.get("性別"):
282 if any([("男性" in c or "男優" in c) for c in categos]):
283 result["性別"] = 1
284 elif any([("女性" in c or "女優" in c) for c in categos]):
285 result["性別"] = 2
286 else:
287 result["性別"] = 0
288 else:
289 result["性別"] = 1 if ("男" in result["性別"]) else 2
290 return result
291
292
293 def _from_wp_en(result):
294 # 基本的に日本語版を信じ、欠落のものだけ英語版に頼ることにする。
295 if "生年月日" in result and "0000" not in result["生年月日"]:
296 return result
297 try:
298 fn = _urlretrieve(result["wikipedia_en"])
299 except urllib.error.HTTPError:
300 return result
301 with io.open(fn, "r", encoding="utf-8") as fi:
302 soup = bs4.BeautifulSoup(fi.read(), features="html.parser")
303 try:
304 trecords = iter(
305 soup.find("table", {"class": "infobox"}).find("tbody").find_all("tr"))
306 except Exception:
307 return result
308 for tr in trecords:
309 th, td = tr.find("th"), tr.find("td")
310 if not th or not td:
311 continue
312 k_en = th.text.strip()
313 if k_en == "Born":
314 if "生年月日" not in result or "0000" in result["生年月日"]:
315 bd = td.find("span", {"class": "bday"})
316 if bd:
317 bd = re.sub(r"\[[^\[\]]+\]", "", bd.text)
318 result["生年月日"] = bd
319 return result
320
321
322 def _from_wp(actorpagename):
323 result = _from_wp_jp(actorpagename)
324 if "wikipedia_en" in result:
325 _from_wp_en(result)
326 return result
327
328
329 if __name__ == '__main__':
330 def _yrgrp(ymd, actst):
331 y = 0
332 if ymd:
333 y, _, md = ymd.partition("-")
334 y = int(y)
335 if y and md < "04-02":
336 y -= 1
337 return [
338 y,
339 actst.replace("0000", "????"),
340 ymd.replace("0000", "????")]
341 def _names(inf):
342 # inf["名前"]
343 # 通常は
344 # 0: wikipediaページ名からあいまい回避サフィクスを取り除いた名前
345 # 1: 2のよみ
346 # 2: 姓+スペース+名
347 # ページによってこれがバラつく。0しか取れないものは結構ある。外国人名は「姓+スペース+名」
348 # に従わない。通常ケースでは 2、1 をとって 0 を捨てるのが使いやすい。
349 nms = inf["名前"]
350 if len(nms) == 3:
351 if nms[0] == re.sub(r"\s+", "", nms[2]) or nms[0] == nms[1]:
352 return ", ".join([nms[2], nms[1]]), nms[2]
353 return ", ".join([nms[0], nms[2], nms[1]]), nms[0]
354 elif len(nms) == 1:
355 return nms[0], nms[0]
356 else: # ふりがながないケース、と思う。
357 if nms[0] != re.sub(r"\s+", "", nms[1]):
358 return ", ".join([nms[0], nms[1]]), nms[0]
359 return nms[1], nms[1]
360
361 actorpages = list(set(
362 map(lambda s: s.strip(),
363 io.open("wppagenames.txt", encoding="utf-8").read().strip().split("\n"))))
364 result = []
365 for a in filter(None, actorpages):
366 inf = _from_wp(a)
367 g = _yrgrp(inf.get("生年月日", ""), inf.get("actst", "0000"))
368 nms_disp, n0 = _names(inf)
369 wp = inf["wikipedia"]
370 if n0.replace(" ", "") == wp:
371 wp = ""
372 result.append((
373 g[0], g[1], g[2].replace("-", ""),
374 inf.get("没年月日", "").replace("-", ""),
375 inf.get("性別", 0),
376 wp,
377 nms_disp,
378 re.sub(r"\s*型", "", inf.get("血液型", "")),
379 re.sub(
380 r"\b日本・", "",
381 "、".join(list(filter(None, [inf.get("出生地", ""), inf.get("出身地", "")])))),
382 re.sub(r"、\s*([((])", r"\1", inf.get("愛称", "")),
383 re.sub(r"(\d)\s+([a-z])", r"\1\2", inf.get("身長/体重", "")),
384 re.sub(r"、\s*([((])", r"\1", inf.get("事務所・レーベル", "")),
385 re.sub(r"、\s*([((])", r"\1", inf.get("デビュー作", "")),
386 inf.get("共同作業者", ""),
387 inf.get("occ", ""),
388 ))
389 result.sort()
390 with io.open("actor_basinf.html", "w", encoding="utf-8") as fo:
391 print("""\
392 <html>
393 <head jang="ja">
394 <meta charset="UTF-8">
395 <link href="https://cdnjs.cloudflare.com/ajax/libs/tabulator/5.0.6/css/tabulator_site.min.css" rel="stylesheet">
396 <script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/tabulator/5.0.6/js/tabulator.min.js"></script>
397 <script type="text/javascript" src="https://oss.sheetjs.com/sheetjs/xlsx.full.min.js"></script>
398
399 <!--
400 {}
401 -->
402 </head>""".format(__doc__), file=fo)
403 print("""\
404 <body>
405 <div style="margin: 1em 0em">
406 <select id="filter-gender">
407 <option value=""></option>
408 <option value="1">男性のみ</option>
409 <option value="2">女性のみ</option>
410 </select>
411 <select id="filter-alive">
412 <option></option>
413 <option>存命者のみ</option>
414 <option>死没者のみ</option>
415 </select>
416 </div>
417 <div id="actor_basinf"></div>
418 <div style="margin: 1em 0em">
419 <button id="download-csv">Download CSV</button>
420 <button id="download-json">Download JSON</button>
421 <button id="download-xlsx">Download XLSX</button>
422 <button id="download-html">Download HTML</button>
423 </div>
424 <script>
425 var filter_gender = document.getElementById("filter-gender");
426 function _update_genderfilter() {
427 let i = filter_gender.selectedIndex;
428 let v = filter_gender.options[i].value;
429 let eflts = table.getFilters(true);
430 for (let efi in eflts) {
431 let f = eflts[efi];
432 if (f["field"] == "gen") {
433 table.removeFilter(f["field"], f["type"], f["value"]);
434 break;
435 }
436 }
437 if (v) {
438 table.addFilter("gen", "regex", v);
439 }
440 }
441 filter_gender.addEventListener("change", _update_genderfilter);
442 var filter_alive = document.getElementById("filter-alive");
443 function _update_alivefilter() {
444 let i = filter_alive.selectedIndex;
445 let eflts = table.getFilters(true);
446 for (let efi in eflts) {
447 let f = eflts[efi];
448 if (f["field"] == "dymd") {
449 table.removeFilter(f["field"], f["type"], f["value"]);
450 break;
451 }
452 }
453 if (i == 1) {
454 table.addFilter("dymd", "=", "");
455 } else if (i == 2) {
456 table.addFilter("dymd", "!=", "");
457 }
458 }
459 filter_alive.addEventListener("change", _update_alivefilter);
460
461 document.getElementById("download-csv").addEventListener("click", function() {
462 table.download("csv", "data.csv");
463 });
464 document.getElementById("download-json").addEventListener("click", function() {
465 table.download("json", "data.json");
466 });
467 document.getElementById("download-xlsx").addEventListener("click", function() {
468 table.download("xlsx", "data.xlsx", {sheetName:"My Data"});
469 });
470 document.getElementById("download-html").addEventListener("click", function() {
471 table.download("html", "data.html", {style: true});
472 });
473
474 function _dt2int(dt) {
475 function _pad(n) {
476 let ns = "" + Math.abs(n);
477 if (ns.length === 1) {
478 ns = "0" + ns;
479 }
480 return ns;
481 }
482 return parseInt(dt.getFullYear() + _pad(dt.getMonth() + 1) + _pad(dt.getDate()));
483 }
484 var nowi = _dt2int(new Date());
485 function _calcage(cell, formatterParams) {
486 var v = cell.getValue().replace(new RegExp("\-", "g"), "");
487 if (v.startsWith("????")) {
488 return "";
489 }
490 v = parseInt(v.replace(/\?/g, "0"));
491 var result = "" + parseInt((nowi - v) / 10000);
492 result += "歳";
493 let unk = cell.getValue().includes("-??");
494 if (unk) {
495 result += "?";
496 }
497 var d = cell.getRow().getCell("dymd").getValue().replace(
498 "?", "0").replace(new RegExp("\-", "g"), "");
499 if (d) {
500 result += " (";
501 result += parseInt((parseInt(d) - v) / 10000);
502 result += "歳";
503 if (unk) {
504 result += "?";
505 }
506 result += "没)";
507 }
508 return result;
509 }
510
511
512 var actor_basinf_data_csv = """, file=fo)
513 jds = json.dumps(
514 result,
515 ensure_ascii=False, indent=0)
516 print(jds, file=fo)
517 print("""
518 var actor_basinf_data = Array();
519 actor_basinf_data_csv.forEach(function (r, i) {
520 let bymd = r[2];
521 if (bymd) {
522 bymd = bymd.slice(0, 4) + "-" + bymd.slice(4, 6) + "-" + bymd.slice(6, 8);
523 }
524 let dymd = r[3];
525 if (dymd) {
526 dymd = dymd.slice(0, 4) + "-" + dymd.slice(4, 6) + "-" + dymd.slice(6, 8);
527 }
528 actor_basinf_data.push({
529 "by": r[0], /* 生誕年度 */
530 "as": r[1], /* 活動開始年? */
531 "bymd": bymd, /* 生年月日 */
532 "dymd": dymd, /* 没年月日 */
533 "gen": r[4], /* 性別 */
534 "wp": r[5], /* wikipedia */
535 "nm": r[6], /* 名前 */
536 "bld": r[7], /* 血液型 */
537 "bor": r[8], /* 出生地・出身地 */
538 "nn": r[9], /* 愛称 */
539 "tw": r[10], /* 身長/体重 */
540 "bel": r[11], /* 事務所・レーベル */
541 "fst": r[12], /* デビュー作 */
542 "tea": r[13], /* 共同作業者 */
543 "occ": r[14], /* 職業/職種/ジャンル */
544 })
545 })
546
547
548 var table = new Tabulator("#actor_basinf", {
549 "height": "800px",
550 "columnDefaults": {
551 /* 注意: 「tooltips」ではない。「tooltip」である。 */
552 "tooltip": true,
553
554 /* これはいつから使えたのかな? かつては「columnDefaults」の外にいたやつ。 */
555 "headerSortTristate": true,
556 },
557 "columns": [
558 {
559 "field": "by",
560 "title": "生誕年度",
561 "headerFilter": "input",
562 "headerFilterFunc": "regex",
563 "formatter": function (cell, formatterParams, onRendered) {
564 let v = cell.getValue();
565 return !v ? "????" : v;
566 },
567 },
568 {
569 "field": "as",
570 "title": "活動開始年?",
571 "headerFilter": "input",
572 "headerFilterFunc": "regex",
573 },
574 {
575 "field": "bymd",
576 "title": "生年月日",
577 "headerFilter": "input",
578 "headerFilterFunc": "regex",
579 },
580 {
581 "field": "bymd",
582 "formatter": _calcage,
583 "headerTooltip": "存命の場合は年齢そのもの。亡くなっている方の場合は「生きていれば~歳」。 "
584 },
585 {
586 "field": "dymd",
587 "title": "没年月日",
588 },
589 {
590 "field": "gen",
591 "title": "性別",
592 "formatter": function (cell, formatterParams, onRendered) {
593 let g = cell.getValue();
594 if (g == 1) {
595 return "男";
596 } else if (g == 2) {
597 return "女";
598 }
599 return "";
600 },
601 },
602 {
603 "field": "nm",
604 "title": "名前",
605 "headerFilter": "input",
606 "headerFilterFunc": "regex",
607 },
608 {
609 "field": "wp",
610 "title": "wikipedia",
611 "formatter": function (cell, formatterParams, onRendered) {
612 let pn = cell.getValue();
613 if (!pn) {
614 let n0 = cell.getRow().getCell("nm").getValue();
615 n0 = n0.replace(new RegExp(", .*$"), "");
616 pn = n0.replace(new RegExp("\\\\s+", "g"), "");
617 }
618 return "<a href='https://ja.wikipedia.org/wiki/" +
619 pn + "' target=_blank>" + pn + "</a>";
620 },
621 },
622 {
623 "field": "bld",
624 "title": "血液型",
625 "headerFilter": "input",
626 "headerFilterFunc": "regex",
627 },
628 {
629 "field": "bor",
630 "title": "出生地・出身地",
631 "headerFilter": "input",
632 "headerFilterFunc": "regex",
633 },
634 {
635 "field": "nn",
636 "title": "愛称",
637 "headerFilter": "input",
638 "headerFilterFunc": "regex",
639 },
640 {
641 "field": "tw",
642 "title": "身長/体重",
643 "headerFilter": "input",
644 "headerFilterFunc": "regex",
645 },
646 {
647 "field": "bel",
648 "title": "事務所・レーベル",
649 "headerFilter": "input",
650 "headerFilterFunc": "regex",
651 },
652 {
653 "field": "fst",
654 "title": "デビュー作",
655 "headerFilter": "input",
656 "headerFilterFunc": "regex",
657 },
658 {
659 "field": "tea",
660 "title": "共同作業者",
661 "headerFilter": "input",
662 "headerFilterFunc": "regex",
663 },
664 {
665 "field": "occ",
666 "title": "職業/職種/ジャンル",
667 "headerFilter": "input",
668 "headerFilterFunc": "regex",
669 },
670 ],
671 "layout": "fitColumns",
672 "data": actor_basinf_data
673 });
674 </script>
675 </html>
676 """, file=fo)
「columns」定義部分で「field」を指定してるのだから、ここに配列のインデクスを指定したらおkなのでは、と期待してみたけど、それはどうやらダメ。残念。
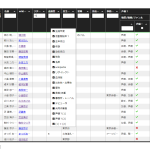
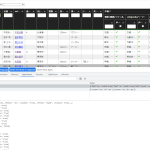
ともあれ、ここまでやればかなりの人数の声優を(このワタシの MySQL 管理の制限内でも)こうやって貼り付けられる:
切り詰めを行っていない最初のバージョンだと、1000人くらいしか扱えないが、この版だとこの人数でまだ少しだけ余力がある、列追加もしたのに。それと、リストから辞書への変換の処理時間は、体感ではこの量でも大したことはなさそうだね。
もちろん、このままのアプローチのままでデータ増量をさらに続ければ再び同じ問題が起こる。その場合はそもそも「技術ネタとして実例をブログに貼り付けて公開」としての目的が済んでしまえば「data-url にしてブログに貼り付け」自体不要なわけなので、基本的にはあとは純粋に普通の性能問題だけ考えればいい。また、html とデータを一体にしているのも結局は「Wordpress の外に出たくない」ということだけから来ている制約、必要であれば分離を考えれば良い。