10万人あたり換算で統一したとしても、その図示がわかりやすいものになるかどうかはまた別。
これの続きというかなんというか。予測の話は含まない。まずは前提のデータ取得:
1 # -*- coding: utf-8-unix -*-
2 import io
3 import csv
4 import datetime
5 import numpy as np
6
7
8 _PREFCODE = {
9 '北海道': 1,
10 '青森県': 2,
11 '岩手県': 3,
12 '宮城県': 4,
13 '秋田県': 5,
14 '山形県': 6,
15 '福島県': 7,
16 '茨城県': 8,
17 '栃木県': 9,
18 '群馬県': 10,
19 '埼玉県': 11,
20 '千葉県': 12,
21 '東京都': 13,
22 '神奈川県': 14,
23 '新潟県': 15,
24 '富山県': 16,
25 '石川県': 17,
26 '福井県': 18,
27 '山梨県': 19,
28 '長野県': 20,
29 '岐阜県': 21,
30 '静岡県': 22,
31 '愛知県': 23,
32 '三重県': 24,
33 '滋賀県': 25,
34 '京都府': 26,
35 '大阪府': 27,
36 '兵庫県': 28,
37 '奈良県': 29,
38 '和歌山県': 30,
39 '鳥取県': 31,
40 '島根県': 32,
41 '岡山県': 33,
42 '広島県': 34,
43 '山口県': 35,
44 '徳島県': 36,
45 '香川県': 37,
46 '愛媛県': 38,
47 '高知県': 39,
48 '福岡県': 40,
49 '佐賀県': 41,
50 '長崎県': 42,
51 '熊本県': 43,
52 '大分県': 44,
53 '宮崎県': 45,
54 '鹿児島県': 46,
55 '沖縄県': 47,
56 }
57 _COLSNM = (
58 "testedPositive",
59 "peopleTested",
60 "hospitalized",
61 "serious",
62 "discharged",
63 "deaths",
64 "effectiveReproductionNumber",
65 )
66 def _tonpa(fn):
67 # 元データ prefectures.csv の著作権:
68 # 『東洋経済オンライン「新型コロナウイルス 国内感染の状況」制作:荻原和樹』
69 #
70 # 1. 開始日が NHK まとめと違う
71 # 2. 更新のない都道府県は省略してある
72 # 3. 日付は一応抜けなく連続している、今のところ
73 #
74 # NHKまとめのほうで密行列として扱った同じノリにしたい、ここでは面倒だけど。
75 # つまり、列方向に都道府県、行方向に日付。
76 result = {
77 k: np.zeros((1, 47))
78 for k in _COLSNM}
79 reader = csv.reader(io.open(fn, encoding="utf-8-sig"))
80 next(reader)
81 def _f(d):
82 if not d or d == "-":
83 # 不明とか未報告の意味だと思う。
84 return float("nan")
85 return float(d)
86
87 era = datetime.datetime(2020, 1, 16) # NHKまとめのほうの起点日
88 curdate = era
89 for line in reader:
90 date = datetime.datetime(*map(int, line[:3]))
91 dadv = (date - curdate).days
92 data = list(map(_f, line[5:]))
93 p = _PREFCODE[line[3]]
94 for i, k in enumerate(_COLSNM):
95 for _ in range(dadv):
96 result[k] = np.vstack((result[k], np.zeros((1, 47))))
97 result[k][-1, p - 1] = data[i]
98 curdate = date
99 # 元データについて、どうやら厚労省のオープンデータそのものを転記しただけの
100 # 項目は累積でのみ管理しているらしく、この csv 全体では「累積だったりそうで
101 # なかったり」と大変使いにくい。ゆえ、累積のものは読み替えておく。
102 for k in ("testedPositive", "peopleTested", "discharged", "deaths",):
103 result[k][1:] = (
104 result[k] - np.roll(result[k], 1, axis=0))[1:]
105 #
106 # peopleTested の最新2日分はゴミ:
107 # ---
108 # 2021,1,28,東京都,Tokyo, 97571, 1303823.0, 14957.0, 150, 81767.0, 847, 0.74
109 # 2021,1,29,東京都,Tokyo, 98439, 1309999.0, 13807.0, 147, 83768.0, 864, 0.76
110 # 2021,1,30,東京都,Tokyo, 99208, 1309999.0, 13383.0, 141, 84942.0, 883, 0.77
111 # 2021,1,31,東京都,Tokyo, 99841, 1309999.0, 13257.0, 140, 85698.0, 886, 0.78
112 # ---
113 # 集計が3日遅れ、てこと、だろう。
114 result["peopleTested"][np.where(result["peopleTested"] == 0.0)] = float("nan")
115 # 移動平均
116 for k in ("testedPositive", "peopleTested", "hospitalized", "serious", "deaths"):
117 k1, k2 = k, k + "_movavg"
118 result[k2] = np.zeros(result[k1].shape)
119 for dt in range(len(result[k1])):
120 result[k2][dt, :] = result[k1][
121 max(0, dt - 6):dt + 1, :].mean(axis=0)
122 #
123 np.savez(io.open("toyokeizai_online_covid19.npz", "wb"), **result)
124
125
126 if __name__ == '__main__':
127 _tonpa("prefectures.csv")
で、これでは示さなかったが、wikipedia からデータをコピペしてきてる、ワタシは:
1 1 東京都 13000-1 13,515,271 13,960,236 +3.29 2021年1月1日
2 2 神奈川県 14000-7 9,126,214 9,216,009 +0.98 2020年9月1日
3 3 大阪府 27000-8 8,839,469 8,815,082 -0.28 2020年11月1日
4 4 愛知県 23000-6 7,483,128 7,538,701 +0.74 2020年11月1日
5 5 埼玉県 11000-1 7,266,534 7,342,682 +1.05 2020年12月1日
6 6 千葉県 12000-6 6,222,666 6,281,869 +0.95 2021年1月1日
7 7 兵庫県 28000-3 5,534,800 5,434,645 -1.81 2021年1月1日
8 8 北海道 01000-6 5,381,733 5,231,685 -2.79 2020年11月30日
9 9 福岡県 40000-9 5,101,556 5,108,038 +0.13 2020年9月1日
10 10 静岡県 22000-1 3,700,305 3,613,788 -2.34 2021年1月1日
11 11 茨城県 08000-4 2,916,976 2,852,499 -2.21 2021年1月1日
12 12 広島県 34000-6 2,843,990 2,793,470 -1.78 2020年11月1日
13 13 京都府 26000-2 2,610,353 2,566,341 -1.69 2021年1月1日
14 14 宮城県 04000-2 2,333,899 2,290,915 -1.84 2021年1月1日
15 15 新潟県 15000-2 2,304,264 2,195,068 -4.74 2021年1月1日
16 16 長野県 20000-0 2,098,804 2,031,795 -3.19 2021年1月1日
17 17 岐阜県 21000-5 2,031,903 1,975,397 -2.78 2020年9月1日
18 18 栃木県 09000-0 1,974,255 1,930,000 -2.24 2021年1月1日
19 19 群馬県 10000-5 1,973,115 1,924,116 -2.48 2021年1月1日
20 20 岡山県 33000-1 1,921,525 1,880,772 -2.12 2021年1月1日
21 21 福島県 07000-9 1,914,039 1,820,949 -4.86 2021年1月1日
22 22 三重県 24000-1 1,815,865 1,768,632 -2.60 2020年9月1日
23 23 熊本県 43000-5 1,786,170 1,734,231 -2.91 2021年1月1日
24 24 鹿児島県 46000-1 1,648,177 1,587,785 -3.66 2021年1月1日
25 25 沖縄県 47000-7 1,433,566 1,460,427 +1.87 2021年1月1日
26 26 滋賀県 25000-7 1,412,916 1,412,095 -0.06 2021年1月1日
27 27 山口県 35000-1 1,404,729 1,339,003 -4.68 2021年1月1日
28 28 愛媛県 38000-8 1,385,262 1,323,851 -4.43 2021年1月1日
29 29 長崎県 42000-0 1,377,187 1,308,277 -5.00 2021年1月1日
30 30 奈良県 29000-9 1,364,316 1,321,250 -3.16 2021年1月1日
31 31 青森県 02000-1 1,308,265 1,228,730 -6.08 2020年12月1日
32 32 岩手県 03000-7 1,279,594 1,209,457 -5.48 2021年1月1日
33 33 大分県 44000-1 1,166,338 1,124,309 -3.60 2020年11月1日
34 34 石川県 17000-3 1,154,008 1,129,362 -2.14 2020年12月1日
35 35 山形県 06000-3 1,123,891 1,062,239 -5.49 2021年1月1日
36 36 宮崎県 45000-6 1,104,069 1,062,180 -3.79 2021年1月1日
37 37 富山県 16000-8 1,066,328 1,033,981 -3.03 2020年11月1日
38 38 秋田県 05000-8 1,023,119 948,964 -7.25 2021年1月1日
39 39 香川県 37000-2 976,263 949,357 -2.76 2020年9月1日
40 40 和歌山県 30000-4 963,579 912,364 -5.32 2021年1月1日
41 41 山梨県 19000-4 834,930 805,339 -3.54 2021年1月1日
42 42 佐賀県 41000-4 832,832 808,074 -2.97 2021年1月1日
43 43 福井県 18000-9 786,740 762,272 -3.11 2020年11月1日
44 44 徳島県 36000-7 755,733 721,721 -4.50 2020年9月1日
45 45 高知県 39000-3 728,276 688,583 -5.45 2021年1月1日
46 46 島根県 32000-5 694,352 665,702 -4.13 2021年1月1日
47 47 鳥取県 31000-0 573,441 550,651 -3.97 2021年1月1日
この表を取り込んで、前回の表を作った。
の上で。「10万人あたり」という見方で統一すれば、全国を一気に見ることが出来る:
1 # -*- coding: utf-8-unix -*-
2 import io
3 import csv
4 import datetime
5 import numpy as np
6 import matplotlib as mpl
7 import matplotlib.pyplot as plt
8 import matplotlib.font_manager
9 import matplotlib.ticker as ticker
10
11
12 _PREFCODE = {
13 '北海道': 1,
14 '青森県': 2,
15 '岩手県': 3,
16 '宮城県': 4,
17 '秋田県': 5,
18 '山形県': 6,
19 '福島県': 7,
20 '茨城県': 8,
21 '栃木県': 9,
22 '群馬県': 10,
23 '埼玉県': 11,
24 '千葉県': 12,
25 '東京都': 13,
26 '神奈川県': 14,
27 '新潟県': 15,
28 '富山県': 16,
29 '石川県': 17,
30 '福井県': 18,
31 '山梨県': 19,
32 '長野県': 20,
33 '岐阜県': 21,
34 '静岡県': 22,
35 '愛知県': 23,
36 '三重県': 24,
37 '滋賀県': 25,
38 '京都府': 26,
39 '大阪府': 27,
40 '兵庫県': 28,
41 '奈良県': 29,
42 '和歌山県': 30,
43 '鳥取県': 31,
44 '島根県': 32,
45 '岡山県': 33,
46 '広島県': 34,
47 '山口県': 35,
48 '徳島県': 36,
49 '香川県': 37,
50 '愛媛県': 38,
51 '高知県': 39,
52 '福岡県': 40,
53 '佐賀県': 41,
54 '長崎県': 42,
55 '熊本県': 43,
56 '大分県': 44,
57 '宮崎県': 45,
58 '鹿児島県': 46,
59 '沖縄県': 47,
60 }
61 def _vis(dattko):
62 reader = csv.reader(io.open("pp.txt", encoding="cp932"), delimiter="\t")
63 fac = []
64 for row in reader:
65 fac.append((_PREFCODE[row[1]], int(row[4].replace(",", ""))))
66 fac.sort()
67 fac = np.array([(100000. / n) for pc, n in fac])
68 #
69 era = datetime.date(2020, 1, 16)
70 #
71 fontprop = matplotlib.font_manager.FontProperties(
72 fname="c:/Windows/Fonts/meiryo.ttc")
73
74 era = "2020/1/16" # 木曜日
75 era = datetime.date(*map(int, era.split("/")))
76 #
77 k = "testedPositive_movavg"
78 #k = "hospitalized"
79 #k = "deaths"
80 #
81 Z = dattko[k] * fac
82 Z[np.argwhere(np.isnan(Z))] = 0
83
84 T = np.array([era + datetime.timedelta(t) for t in range(len(Z))])
85 Y = np.arange(48)
86 X, Y = np.meshgrid(T, Y)
87 #
88 fig, ax1 = plt.subplots(tight_layout=True)
89 fig.set_size_inches(16.53 * 1.2, 11.69)
90 ax1.invert_yaxis()
91 ax1.yaxis.set_major_formatter(
92 ticker.FuncFormatter(
93 lambda x, pos=None: {pc: pn for (pn, pc) in _PREFCODE.items()}.get(x + 1, "")))
94 for lab in ax1.get_yticklabels():
95 lab.set_fontproperties(fontprop)
96 CS = ax1.pcolor(X, Y, Z.T)
97 ax1.set_yticks(range(47))
98 cbar = fig.colorbar(CS)
99 ax1.grid(True)
100 ax1.set_xlabel(
101 "入院治療等を要する者(10万人あたり)\n「東洋経済オンライン「新型コロナウイルス 国内感染の状況」制作:荻原和樹」を加工",
102 fontproperties=fontprop)
103
104 fig.savefig("hospitalized_per100000.png")
105 plt.close(fig)
106
107
108 if __name__ == '__main__':
109 _vis(np.load(io.open("toyokeizai_online_covid19.npz", "rb")))
ごめん、上で「Z[np.argwhere(np.isnan(Z))] = 0」としてる部分、「Z[np.where(np.isnan(Z))] = 0」でないとダメ。失礼。
ほんとか?:
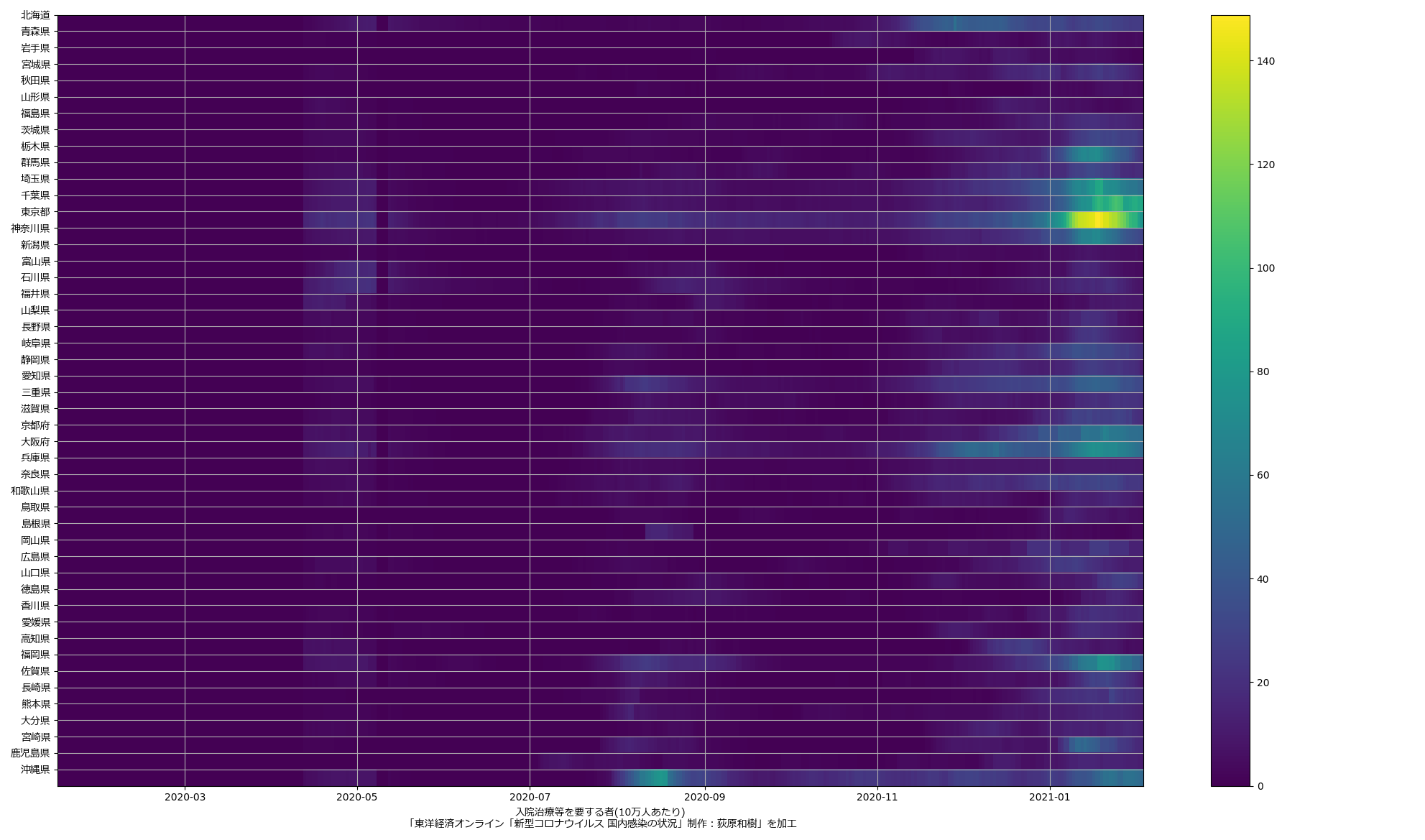
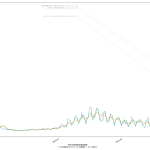
それほどわかりやすいとは言えないよな。なお、3D プロットも試みたが、そっちはもっとダメ、読めたもんじゃない。この pcolor がはるかにいい。
ちなみに、「都道府県コード」っておおよそは日本地図の位置関係に対応しているんだけれど、たとえば宮城県の位置がおかしくて、ほんとは「北海道→青森→秋田→岩手→山形→宮城→福島」であって欲しいんだけどそうなってない。緯度経度の関係順に並べる、ってことそのものが、一次元リストでは無理なことだとはいえ、せめて緯度順にはなってて欲しかった。それでも、とはいえ、これでも一応「生活圏」のかたまりで広がる様子はなんとなくは出てて、尾身会長の言ってた「首都圏から染み出している」が、なんとなくは出てる。
ところで、ここ数日作業してて、今一番危険信号なのは千葉県なんではないかとみているのだが、知事はじめ報道も全然騒いでないよね、いいのかそれで?
2021-02-08追記:
どうにかもう少しクリアに見えんかなぁと思ってやってたが、これだと結構いいかな?:
1 # -*- coding: utf-8-unix -*-
2 import io
3 import csv
4 import datetime
5 import numpy as np
6 import matplotlib as mpl
7 import matplotlib.pyplot as plt
8 import matplotlib.font_manager
9 import matplotlib.ticker as ticker
10 from matplotlib.colors import LogNorm, PowerNorm
11
12
13 _PREFCODE = {
14 '北海道': 1,
15 '青森県': 2,
16 '岩手県': 3,
17 '宮城県': 4,
18 '秋田県': 5,
19 '山形県': 6,
20 '福島県': 7,
21 '茨城県': 8,
22 '栃木県': 9,
23 '群馬県': 10,
24 '埼玉県': 11,
25 '千葉県': 12,
26 '東京都': 13,
27 '神奈川県': 14,
28 '新潟県': 15,
29 '富山県': 16,
30 '石川県': 17,
31 '福井県': 18,
32 '山梨県': 19,
33 '長野県': 20,
34 '岐阜県': 21,
35 '静岡県': 22,
36 '愛知県': 23,
37 '三重県': 24,
38 '滋賀県': 25,
39 '京都府': 26,
40 '大阪府': 27,
41 '兵庫県': 28,
42 '奈良県': 29,
43 '和歌山県': 30,
44 '鳥取県': 31,
45 '島根県': 32,
46 '岡山県': 33,
47 '広島県': 34,
48 '山口県': 35,
49 '徳島県': 36,
50 '香川県': 37,
51 '愛媛県': 38,
52 '高知県': 39,
53 '福岡県': 40,
54 '佐賀県': 41,
55 '長崎県': 42,
56 '熊本県': 43,
57 '大分県': 44,
58 '宮崎県': 45,
59 '鹿児島県': 46,
60 '沖縄県': 47,
61 }
62 def _vis(dattko):
63 reader = csv.reader(io.open("pp.txt", encoding="cp932"), delimiter="\t")
64 fac = []
65 for row in reader:
66 fac.append((_PREFCODE[row[1]], int(row[4].replace(",", ""))))
67 fac.sort()
68 fac = np.array([(100000. / n) for pc, n in fac]) #10万人換算
69 #fac = np.array([(fac[12][1] / n) for pc, n in fac]) #東京換算
70 #
71 era = datetime.date(2020, 1, 16)
72 #
73 fontprop = matplotlib.font_manager.FontProperties(
74 fname="c:/Windows/Fonts/meiryo.ttc")
75
76 era = "2020/1/16" # 木曜日
77 era = datetime.date(*map(int, era.split("/")))
78 #
79 #k = "testedPositive_movavg"
80 #k = "hospitalized"
81 #k = "deaths"
82 #k = "serious_movavg"
83 k = "serious"
84 #
85 skip = 0 #7*4*7
86 Z = dattko[k] * fac
87 Z = Z[skip:]
88 Z[np.where(np.isnan(Z))] = 0
89 #
90 T = np.array([era + datetime.timedelta(t + skip) for t in range(len(Z))])
91 Y = np.arange(48)
92 X, Y = np.meshgrid(T, Y)
93 #
94 fig, ax1 = plt.subplots(tight_layout=True)
95 fig.set_size_inches(16.53 * 1.2, 11.69)
96 ax1.invert_yaxis()
97 ax1.yaxis.set_major_formatter(
98 ticker.FuncFormatter(
99 lambda x, pos=None: {pc: pn for (pn, pc) in _PREFCODE.items()}.get(x + 1, "")))
100 for lab in ax1.get_yticklabels():
101 lab.set_fontproperties(fontprop)
102 #CS = ax1.pcolor(X, Y, Z.T, cmap="coolwarm")
103 #CS = ax1.pcolor(X, Y, Z.T, norm=LogNorm(clip=True))
104 #CS = ax1.pcolor(X, Y, Z.T, norm=LogNorm(), cmap="coolwarm")
105 CS = ax1.pcolor(X, Y, Z.T, norm=PowerNorm(0.4), cmap="coolwarm")
106 ax1.set_yticks(range(47))
107 cbar = fig.colorbar(CS)
108 ax1.grid(True)
109 ax1.set_xlabel(
110 "重症者(10万人あたり)\n「東洋経済オンライン「新型コロナウイルス 国内感染の状況」制作:荻原和樹」を加工",
111 fontproperties=fontprop)
112
113 fig.savefig("{}_per100000.png".format(k))
114 plt.close(fig)
115
116
117 if __name__ == '__main__':
118 _vis(np.load(io.open("toyokeizai_online_covid19.npz", "rb")))
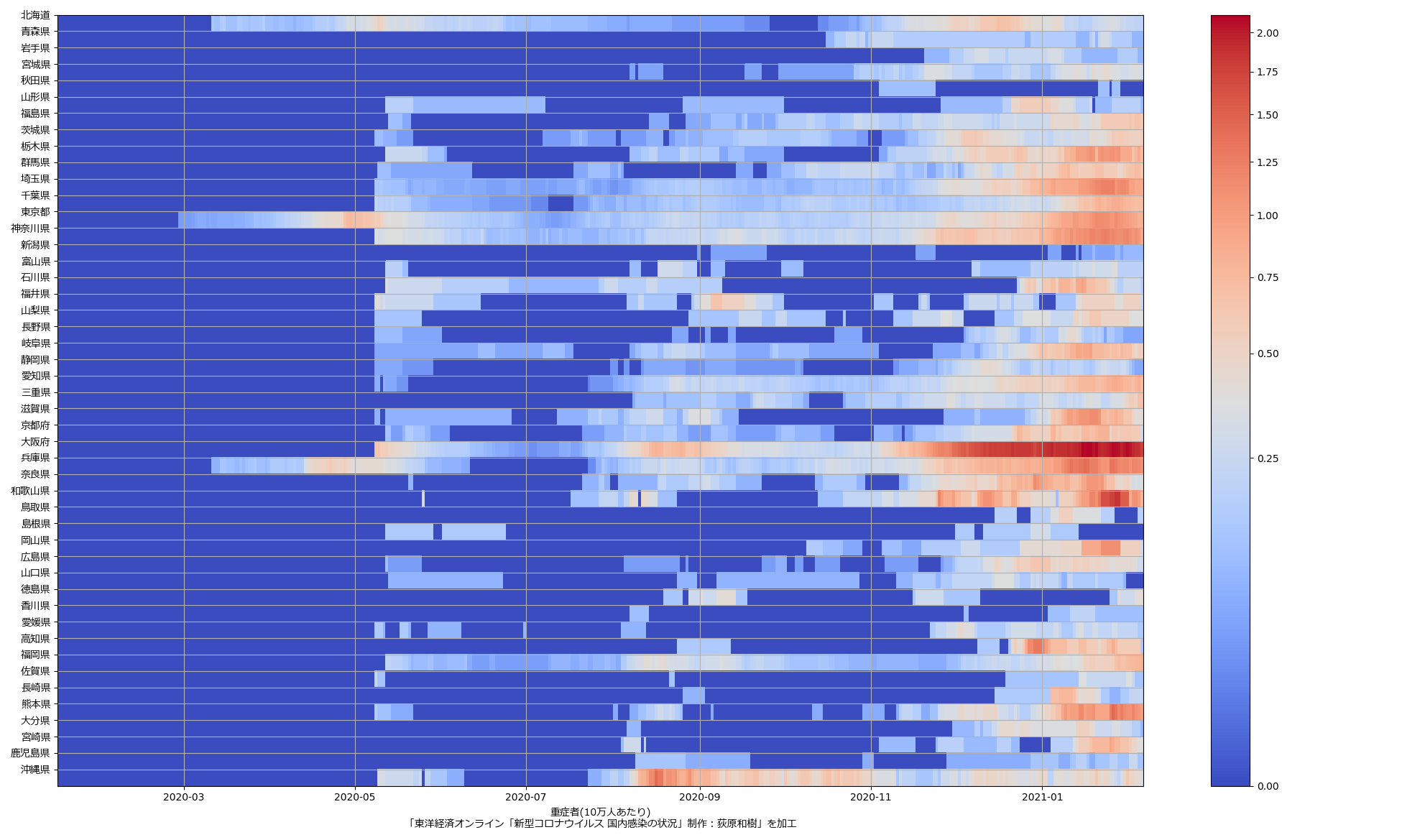
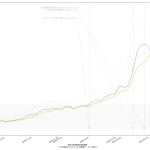
緊急事態宣言解除されてない10都道府県で今一番前のめりで解除に向けて動いてる大阪が、実は一番悪い状態である、てことがはっきりわかる、よね。つまり、こういう図示をしようとする努力をし、そしてそれを共有しようぜ、てことね。そうすりゃぁ吉村知事も「間違えない」と思うんだよなぁ。
2021-02-09追記:
本質的な話ではなくてすまん。上のスクリプトに以下を追加:
1 ax1.tick_params(labelright=True)
とすると、ちょっとだけ使いやすくなる:
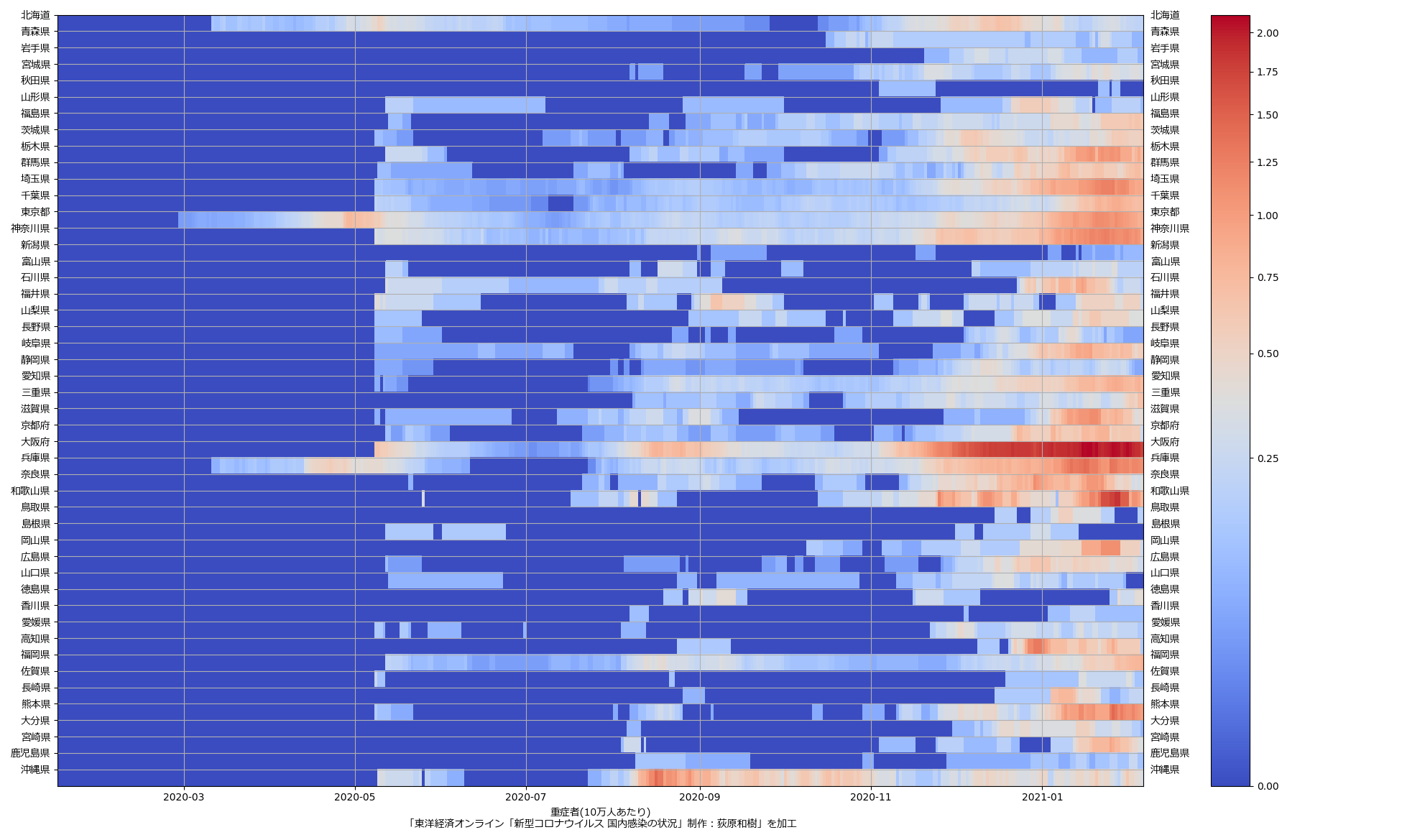
両サイドに都道府県名を描画、てだけね。
大阪問題は騒がれていないことはないんだけど、例の失言問題などで取り上げ方がなんだか異様に薄く、ちょっと気になる。オリンピック問題は確かに問題なのだが、果たして「欽…」を何時間もかけて伝える意味が、今あるのかどうか。コロナのことばっかやってんじゃないよ、って反発はわからんでもないけれどもだな、その反動で選ぶのがソレなの? なんだかなぁって思うよ。
2021-02-12追記:
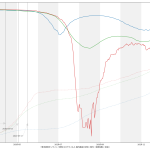
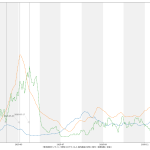
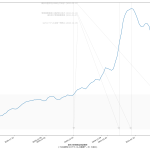
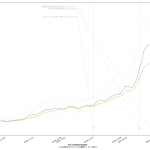
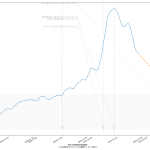
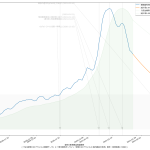
大阪問題については、まだ言いたい。重症病床使用率が60%未満になったからおkだ、としてまた突っ走ろうとしてるようだが、繰り返すが「大阪が今一番ヤバい状態にある」。もう少し見やすくならんかなぁと思った。一つにはやはり「東京で言うと」の数字で見せることの意義ね。インパクトがあろう。「10万人あたり2.3人」なんて言われるよりも。もう一つは、「(流行)波の形」なのよ。伝わるかなぁ? まずは二つの絵をみてみて:
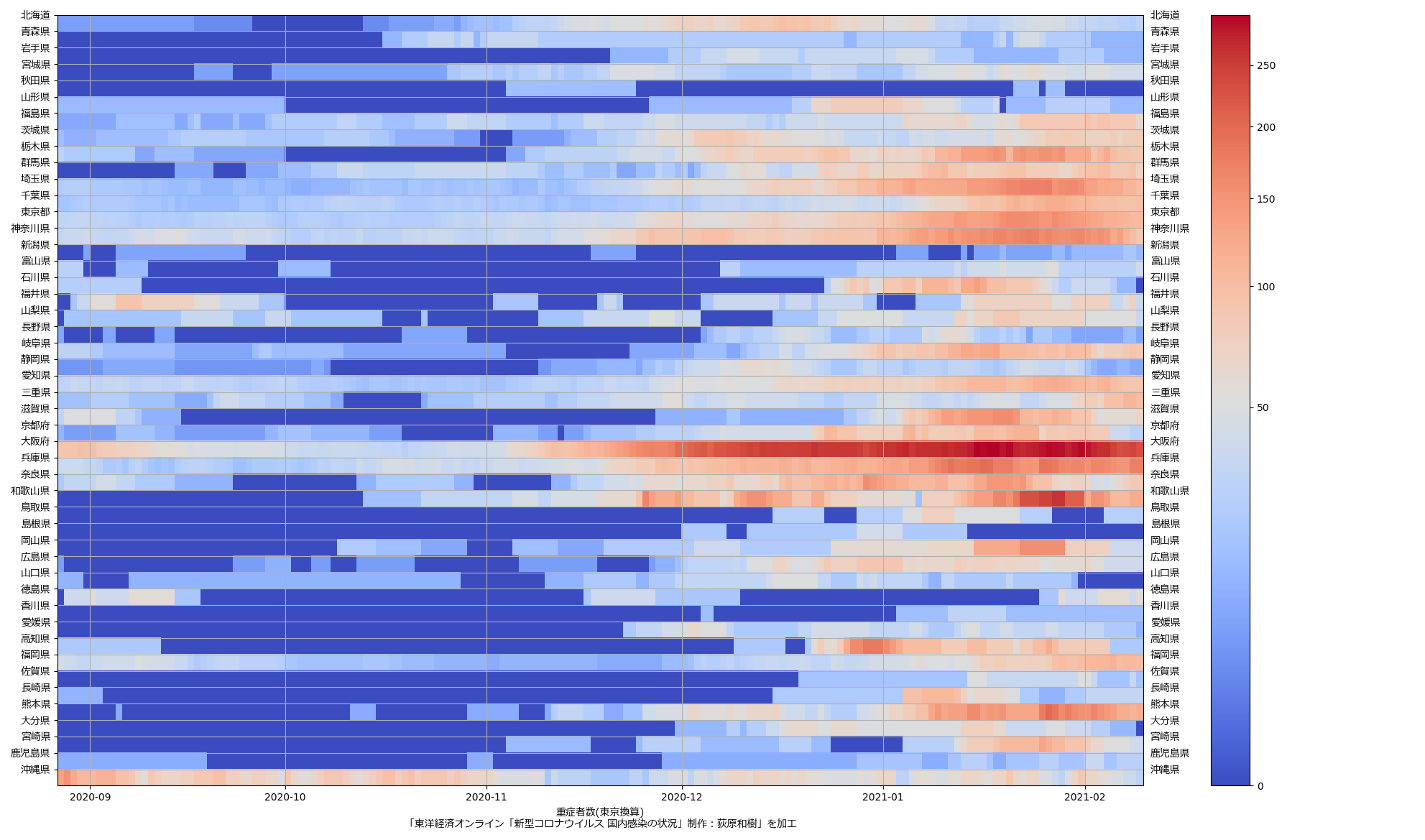
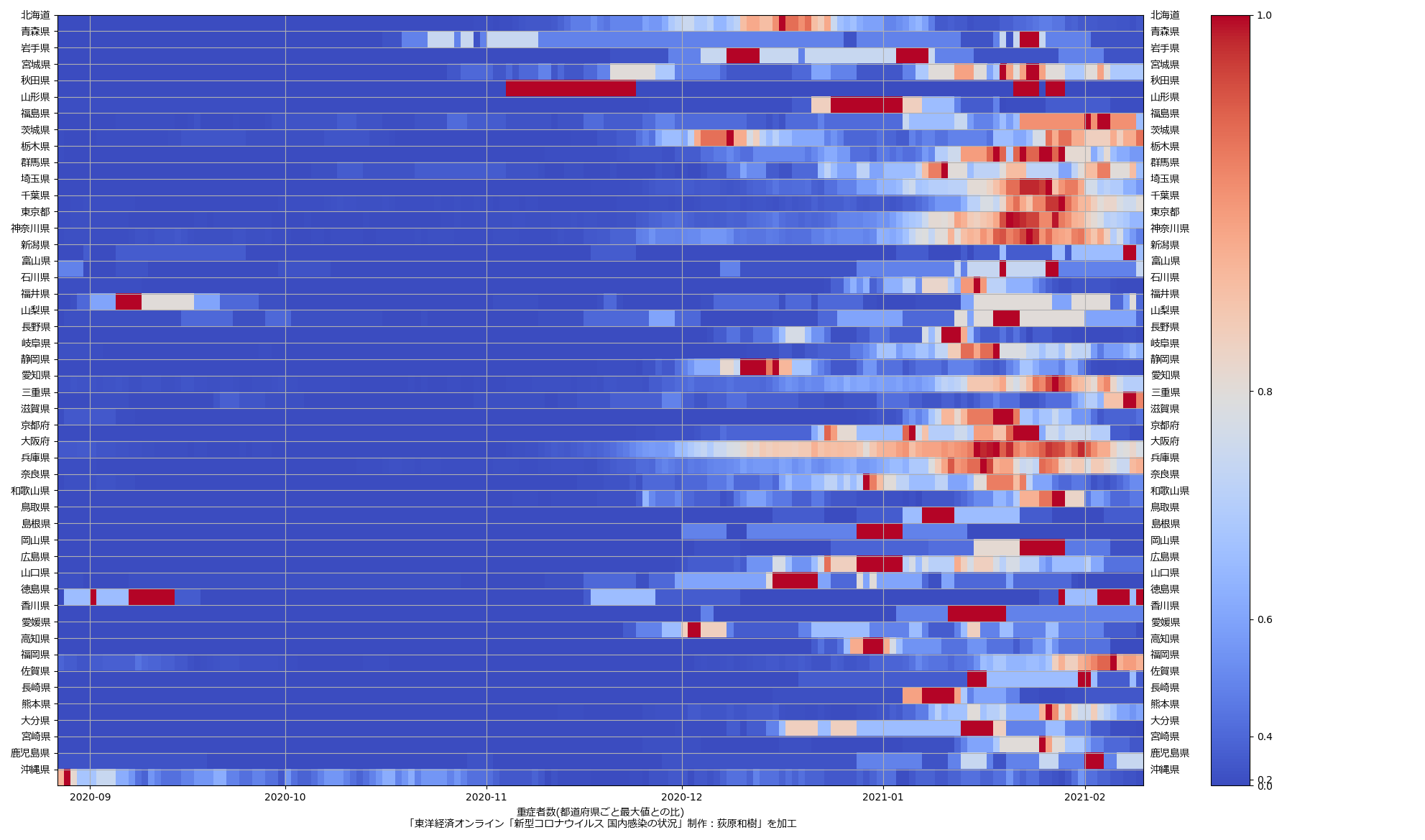
上の絵はわかるよね、「東京でいうところの250人である」てこと。下の絵は各都道府県ごとの最大値で割った値で、つまりはピーク位置を強調した絵。これをみれば、大阪のピークアウト開始が東京より随分遅く始まったのがわかる、かなと思うんだけど、どう? 死亡者は、これまでのところ、重症者の波の2週遅れという推移を辿ってきているので、大阪はまだ何日も死亡者数は増加傾向が続き、東京はこれから下がり続けるということがわかる。
繰り返す。「今日本で一番マズい状態にあるのは大阪」。東京ではない。吉村知事はそこを見誤ってるのではないのか。ちょっと前に書いたけど、やっぱり「医療体制拡充前の状態で言うところの逼迫度」もやっぱり同時にみた方がいいんではないかと思ってる。たとえば「自衛隊5万人に助けを求めたので感染者が5万人増えていい」というのと根本的に同じことをしようとしてるのだ、大阪は。結局これも「じぶんごと」として考えることが出来るかどうかだよなぁ、って思う。