ここんとこの「読むな」シリーズのためにやってたデータ分析からのネタだったりする。
Contents
sqlite3 小ネタ
拝啓背景
本業や本題とはおよそ無関係なアニメの「評価の推移」を知りたいてことから、最初は単に wget でページを定期的に取り寄せて、取り寄せたページ全部を都度読み込んで解析してたんだけれど、収集ページが多くなってきたことと、もうひとつはトップランキングページだけでなく詳細ページまで手繰りたくなったんで、さすがに「ページをダウンロードしたものをとっといて」というアプローチに無理が出てきて、となれば「都度データ抽出して永続化するかぁ」てことになり、なので sqlite を使うアプローチに乗り換えた、てこと。
いくら「ライト」だ言うてもこれは「それでもちゃんとした (R)DBMS」なので、初期コストは結構なもの。この初期コストを嫌えば json やら pickle も選択肢だったけれど、「ちゃんとした」、つまり「SQLによる集積データの取り回しやすさ」を取りたかったわけね。
今回抽出したネタはいずれも「久しぶりにデータベースそのものを扱ったわ」「お仕事モードでないから雑にやっちゃったのだわ」起因だったりもして、かなり他愛もない。小ネタ言うだけのことはある。
ランキングを自力で
これは sqlite 関係なく、DBMS ごとに「もっと楽なやり方はあるかも」はあるにしても汎用、一応。
何がしたかったかと言うと。最初は ランキングページの順位の値そのものを取って永続化してたのね。このランキングページにしか興味がないうちは良かったんだけれど、このページに現れるのは「放送中」のものだけなことともっと詳細が欲しいという二つの理由から詳細ページも利用しようと思うなら…。
当たり前だがランキングページは詳細ページを動的に集計することで生成されているわけであって、順位データは永続データじゃない。myanimelist.net のデータベースの構造(想像だけど)に合わせたいわけだね。放送終了後は詳細ページしか参照出来ないからには、もはや「永続データとしての放送中順位」なんてものは取れないんだから。
所詮遊びなので雑だがこんなテーブル構造にしている:
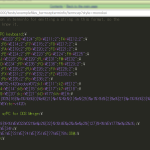
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3
4 import sqlite3
5
6
7 _DB_NAME = 'mal_stats.db'
8 def _create_db():
9 conn = sqlite3.connect(_DB_NAME)
10 c = conn.cursor()
11
12 # 最初 t_airing_snapshot に rank を入れてしまってた、てこと。
13 c.execute('''\
14 CREATE TABLE t_airing_snapshot
15 (
16 name TEXT
17 , datetime TEXT
18 , score REAL NOT NULL
19 , scored_by INTEGER
20 , members INTEGER NOT NULL
21 , PRIMARY KEY(name, datetime)
22 )''')
23 # ...
24 conn.commit()
25 conn.close()
で、rank をランキングページからデータとして取らずに、この t_airing_snapshot から rank を取りたいのだ、てことなわけだが、無論こんなもんは「sql に慣れてればイチパツだ」てことなんだけれど、なのに何でこんなネタを書こうと思ったかと言うと…。
自分で考えるのダルくて StackOverflow に頼ってダマされたから。この回答:
1 select p1.*
2 , (
3 select count(*)
4 from People as p2
5 where p2.age > p1.age
6 ) as AgeRank
7 from People as p1
8 where p1.Name = 'Juju bear'
ヒントとしてなら役に立つけど間違ってるのよね。アタシの例だと:
1 SELECT a.name, a.datetime, a.score, a.members
2 , (
3 SELECT COUNT(*) FROM t_airing_snapshot as c
4 WHERE c.datetime = a.datetime AND c.score > a.score
5 GROUP BY c.datetime
6 ) as rank
7 FROM t_airing_snapshot as a
元々 rank データを html ページから取ってたので答えが間違ってることはすぐに気付く。1 ずれるのね。あぁ、そうか!:
1 SELECT a.name, a.datetime, a.score, a.members
2 , (
3 SELECT COUNT(*) + 1 FROM t_airing_snapshot as c
4 WHERE c.datetime = a.datetime AND c.score > a.score
5 GROUP BY c.datetime
6 ) as rank
7 FROM t_airing_snapshot as a
真似しちゃダメだよ。
最初はこのバカ丸出し措置で優越感に浸ってたけれど、null (Python では None で取れる) が返ってくるヤツがいて、その場所特定に10分以上かかってしまった。当然正しい答えは:
1 SELECT a.name, a.datetime, a.score, a.members
2 , (
3 SELECT COUNT(*) FROM t_airing_snapshot as c
4 WHERE c.datetime = a.datetime AND c.score >= a.score
5 GROUP BY c.datetime
6 ) as rank
7 FROM t_airing_snapshot as a
sqlite3 の ALTER TABLE には DROP COLUMN がない
そういうわけで rank を動的に SQL で演算することにしたのでカラムとしては不要になり、DROP COLUMN したいぞ、と。
これそのものは FAQ。けど StackOverflow のこの回答は公式 FAQ よりクール:
1 CREATE TABLE t1_backup AS SELECT a, b FROM t1;
2 DROP TABLE t1;
3 ALTER TABLE t1_backup RENAME TO t1;
「DROP COLUMN の代用」としてよりも、「テーブルバックアップ」の術としてのこれは…、あ、これはいい。こんなん他の DBMS でも出来たっけか? (そんなに日常的に使うものではないから憶えてないけど、DB2 も postgresql も oracle も、それぞれ独自だった気がするがどうだったかなぁ?)
ワタシの例の場合だとこんな具合:
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals
3
4 import sqlite3
5
6
7 _DB_NAME = 'mal_stats.db'
8
9
10 def _drop_rank_from_airing_snapshot():
11 conn = sqlite3.connect(_DB_NAME)
12 c = conn.cursor()
13 c.execute('''\
14 CREATE TABLE t_airing_snapshot_new
15 AS SELECT
16 name
17 , datetime
18 , score
19 , scored_by
20 , members
21 FROM t_airing_snapshot;
22 ''')
23 c.execute("DROP TABLE t_airing_snapshot")
24 c.execute("ALTER TABLE t_airing_snapshot_new RENAME TO t_airing_snapshot")
25 conn.commit()
26 conn.close()
27
28 _drop_rank_from_airing_snapshot()
このやり方のアドバンテージについてはStackOverflow のこの回答についてるコメントに書かれてる通り、型も維持してコピーしてるとこ。アドバンテージつーかさ、型が維持されなかったら「DROP COLUMN の代用」にならんやんけ。だから StackOverflow でこの回答でない方にばかり votes されてるのは頭オカシイ。
sqlite3.OperationalError: database is locked
「ちゃんとした DBMS であるからには初期コストが高い」のを雑にやるとこうなる、の典型。
ここでも大騒ぎされつつ解決してないかったりするけれど、ワタシの場合はほんとに単純に「阿呆」なミス。
ミスつーかさ、こういう雑なプロジェクトって、「リソースの獲得・解放をメソッド内に詰め込んでもいいことはない」という基本中の基本を疎かにして始めちゃうことが多いのよね。わかる人はすぐにわかる、以下のダメっぷりは:
1 def _update_baseinfo_all():
2 conn = sqlite3.connect(_DB_NAME)
3 c = conn.cursor()
4 c.execute("SELECT name, relative_url, japanese FROM t_anime_baseinfo WHERE japanese IS NULL")
5 for row in c:
6 name, relative_url, japanese = row
7 info = _get_detail_snapshot(relative_url)
8 c.execute("""\
9 UPDATE t_anime_baseinfo
10 SET
11 japanese = ?
12 , synonyms = ?
13 , english = ?
14 WHERE name = ?""", [info["japanese"], info.get("synonyms"), info.get("english"), name])
15 conn.commit()
16 conn.close()
17
18
19 def update_db():
20 conn = sqlite3.connect(_DB_NAME)
21 c = conn.cursor()
22 # ...
23 for name, relative_url in allprogs:
24 # ...
25 if cnt[0]:
26 # ...
27 else:
28 _update_baseinfo_all()
29 # ...
30 #
31 conn.commit()
32 conn.close()
これが database is locked になるのは「自明」なのだがなぜすぐに気付かなかったかと言えば無論「if cnt[0]」が比較的稀なケースだったから。
こういう雑でなおかつ「動くものを正しく書ける順に少しずつ」というボトムアップアプローチで作っていく場合にこれ、やりがちなんだよね。最初から本格的に作ろうと思うなら、コネクションやトランザクションの管理部分を整理するところから始めるのが定石だもん。(という流れから、普通は最初から class にするだろうね。)
未遂ネタ: sqlite3 の GUI
データベースアプリケーションだとやっぱり
- 手軽に SQL (や DDL) を試せて
- 結果セットをセルビューとして参照出来て
- structure も簡単にみれて
みたいな多少は優秀なものがないとダルい、てのはないではなくて。こんなしょーもないプロジェクトを作るんであってさえ。上のランキング取得の SQL だって、すぐさま試す環境があるほうが楽だし、何より「突っ込んだデータをすぐさまみる」ことですら、python + sqlite3 しかないならダルくて仕方ない。
多分 Eclipse + DBViewer が sqlite も使えるなら一番使いやすいんだろうとは思うけれど、ここんとこ Eclipse そのものがご無沙汰で、わざわざ DBViewer のためだけに Eclipse 入れるのも気分悪いし、てことで、少しだけ探し始めてはみた。
sqlite 専用ものなら SQLiteStudio は良さげに見えたんで、ダウンロードだけはしてみたが、まだ試してない。ほかにもありそうだと思うし、PostgreSQL に付属の psql みたいな CUI の優秀なヤツもあると嬉しいかなと思うんで、気力があればいくつか評価していつか書くかもしれない。今は(やりたいことがほぼ終わっちゃったので)気力がなくて、のでやらない。
2017-11-30 追記: SQLiteStudio お試した
大きな不満は、英語版にありがちなフォントが小さいことくらい、それ以外はかなりいい感じに思えている、今のところ。