前回のさらに続き。
発端のネタでの、Wikipedia 日本語版の最近接偶数への丸めの説明:
これが直感的にわからぬ、というのを「なーんだ」と言いたかったのがそのときのネタ。可視化するまでもなく、だよな、と。
そうなんだけれど、せっかく前回 2.7 以降の Python 全部で同じ検証が出来る round 各種を書いたので、「見せてもらおうか、丸めの偏りとやらを」ろうかしゃん。「half up / half down」なんぞはやってみるまでもなく頭に絵が浮かぶであろうとはいえ、そいでもやってみたいなと。せっかくだし。
てわけで:
1 import numpy as np
2 import matplotlib.pyplot as plt
3 import matplotlib.mlab as mlab
4 from round_int import ( # 前回の記事で作ったヤツらね
5 round_half_up,
6 round_half_down,
7 round_half_towards_zero,
8 round_half_away_from_zero,
9 round_half_to_even,
10 round_half_to_odd)
11
12 p = (
13 # numpy.vectorize は(性能度外視で)スカラーを受け取る関数を ndarray (-like) で
14 # ぶん回す関数で包んでくれる
15 (np.vectorize(round_half_up), "round half up"),
16 (np.vectorize(round_half_down), "round half down"),
17 (np.vectorize(round_half_towards_zero), "round half towards zero"),
18 (np.vectorize(round_half_away_from_zero), "round half away from zero"),
19 (np.vectorize(round_half_to_even), "round half to even"),
20 (np.vectorize(round_half_to_odd), "round half to odd"),
21 )
22
23 sampsiz = (50000, 200)
24 # make sure to include data having fraction==0.5.
25 samples = np.random.random_integers(-10, 10, sampsiz) + \
26 np.random.random_integers(-10, 10, sampsiz) / 10.0
27
28 num_bins = 40
29 for i in range(len(p)):
30 fig, ax = plt.subplots()
31 ax.grid(True)
32 f_ = p[i][0]
33 bios = f_(samples).sum(axis=1) - samples.sum(axis=1)
34
35 n, bins, patches = ax.hist(
36 bios,
37 num_bins,
38 normed=1,
39 facecolor='blue',
40 alpha=0.1)
41 y = mlab.normpdf(bins, bios.mean(), bios.std())
42 ax.plot(bins, y, 'r--')
43 ax.set_title(p[i][1])
44 ax.set_xlim(-16, 16)
45 ax.set_ylim(0, 0.12)
46 plt.savefig("rounds_err{}.png".format(i), bbox_inches="tight")
47 fig.clf()
慣れない人には超難解かもしれない箇所が若干あるのでそれについてはあとで。ざっくり言うと「端数0.5のデータが有限割合で存在するデータセットの、丸めないで sum したものと丸めて sum したものの差」の分布のヒストグラムを作ってる。まずは結果の絵。こんなです。一個画像クリックしてスライドショー的にみると見やすいと思う:
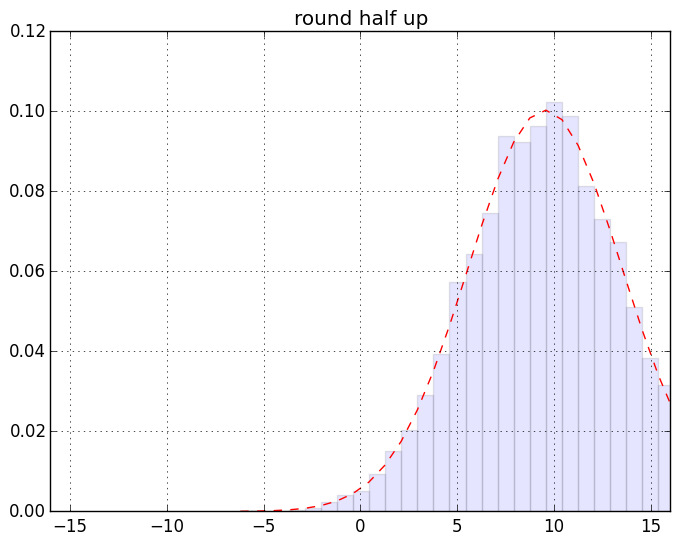
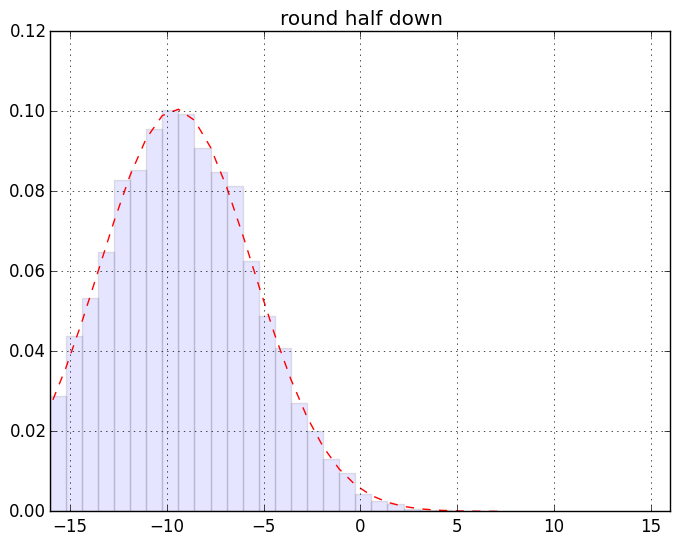
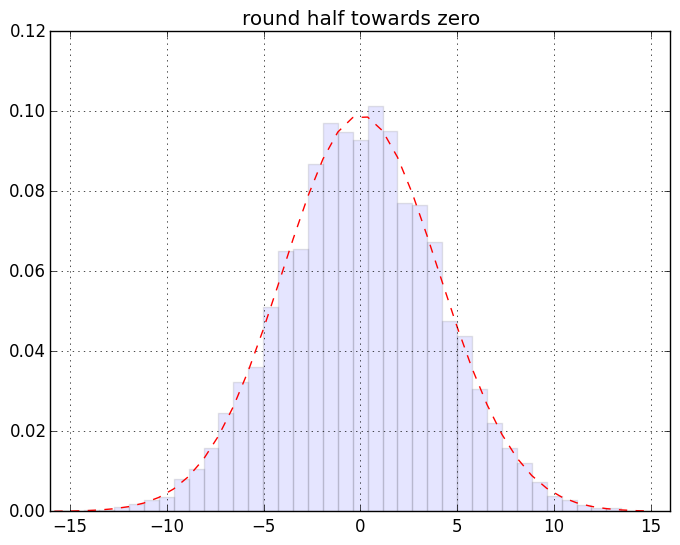
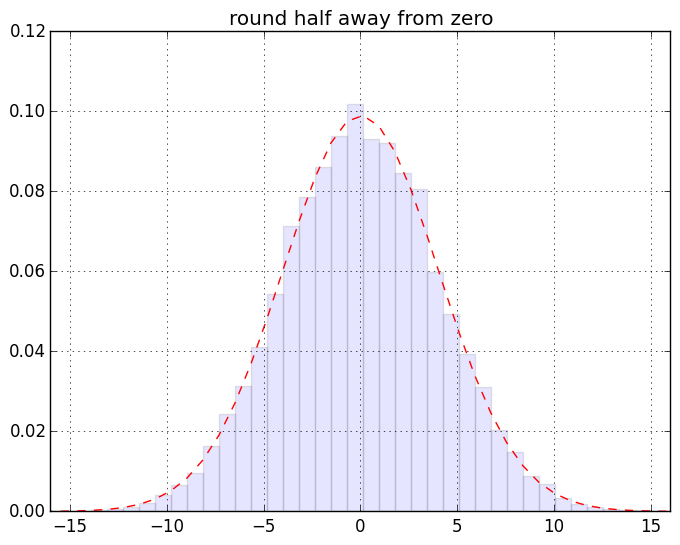
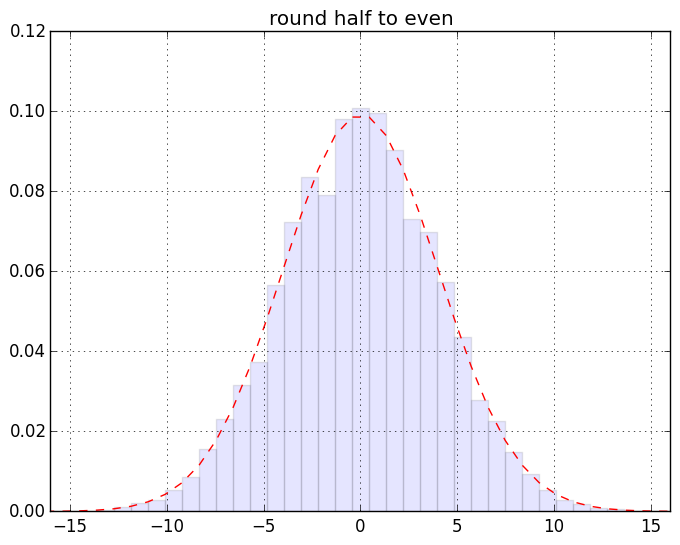
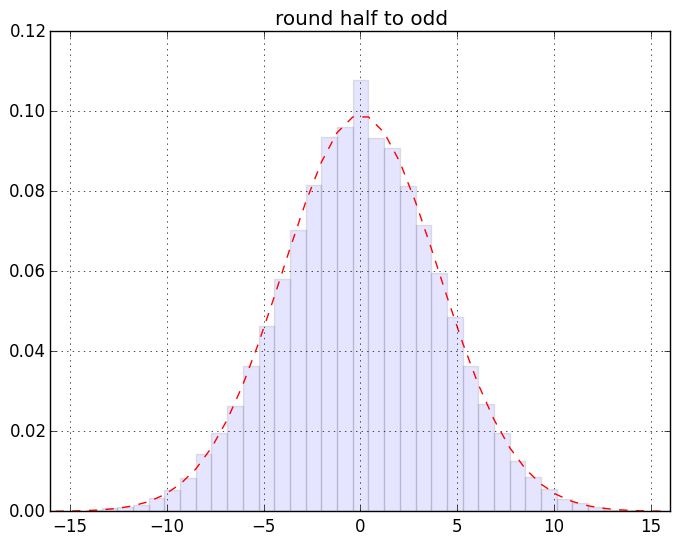
最初の2つを除けば激しい違いはわかりにくいんだけれど、目を凝らして分布の裾なんかをみるとちょっとは違うのかな、というのはわかるみたい。もっとわかりやすく出来そうな気もするけれど「作為のない作為的データを生み出す」てな矛盾した発明を要する作業なので、それをするのは大変と思う(ちうか要するに「確率論」にある程度慣れてないと厳しいつぅハナシ)。
さて、予告した「超難解かもしれない箇所」についてちょいとだけ。難解ちぅか、「なんで?」がわからないかもしれないのね、ここ:
1 sampsiz = (50000, 200)
2 # make sure to include data having fraction==0.5.
3 samples = np.random.random_integers(-10, 10, sampsiz) + \
4 np.random.random_integers(-10, 10, sampsiz) / 10.0
「NumPy 流儀」(というか行列指向)と「端数0.5のデータが有限割合で存在するようにする」という2つの全く独立したハナシがここに一気に詰め込まれちゃっていて、そしてここで作った構造のままこの後のコードに続いてくのね。ここ、まず「サンプル抽出数 200 (== sum 対象) を 50000 回繰り返す」というやりたいことを「(50000, 200) の行列で一気にやっちまえ」てことをしてる。そして「正確に端数が 0.5」というデータを生み出さねばならぬ、と。簡単ちゃぁ簡単かもしれないけれど、「それに相応しいこと」をしないと 0.513 だとか 0.499 だとかそういった端数が満遍なく分布してしまって、「端数が正確に 0.5」というデータは「自然に起こりうる確率でしか入ってこない」、つまり「狙った恣意的な確率で 0.5 データを持てない」。(答えのコードは簡単だけれどね。)
で「後続のコード」:
1 bios = f_(samples).sum(axis=1) - samples.sum(axis=1) # f_ は round_xxx のどれか
は、「抽出数 200 (== sum 対象)」のために「axis=1」しておるわけです。おけ?
不慣れな人にはほかにも難しいと思う箇所もあるかもしれないけれど、normpdf がわからないとかはもう、確率統計をある程度学習してもらうしかないしさ、まぁ頑張って理解しとくれ。
あーそうそう、ワタシはやるつもりはないけれど、round ではなくて floor, ceil, trunc について同じ絵を描いとくとよりわかりやすいかもしんない。(floor, ceil は half down, half up に似たものになり、trunc は half towards zero に似たものになるはず。)
このネタの発端の記事でも書いたけど一応繰り返しときます。ここでの絵から例えば「half up は誤差の蓄積が問題となるのだぁ」ということはわかりますね? けどな、「丸めてから足し込む」のはフツーはやってはいかんのですよ。「加算してから丸める」のが普通。なのでそういう意味では half up / half down だって「悪とはいえない」、使い方次第では。